关于层次结构的数据集合,在日常生活中的很多地方都会碰到。比如一个政府部门的组织结构图,有局长,局长下面分管部门的副局长,副局长下面有科长,科长下面有若干办事员工。每个上级有若干下级,每个下级最多只有一个上级,每一级的员工距离根节点的层级是不同的,这样就形成了一棵树。
层次树在家族关系、育种关系、组织管理、产品装配、科学研究等领域广泛应用。
一、适用场景
| 软件 | 版本 |
|---|---|
| 操作系统 | Redhat 7 及以上版本 |
| DM 数据库 | DM 8.0 及以上版本 |
| CPU 架构 | x86、ARM、龙芯、飞腾等国内外主流 CPU |
二、数据准备
- 导入初始脚本
请下载 init_connect_by.sql,按顺序执行脚本,完成脚本的初始化。
- 创建样例数据演示层次查询
CREATE TABLE dmhr.emp
AS
SELECT a.employee_id,
a.first_name || ', ' || a.last_name employee_name,
b.job_title,
a.manager_id,
a.department_id
FROM dmhr.employees a, dmhr.jobs b
WHERE a.job_id = b.job_id AND a.employee_id < 120;
三、操作方法
3.1 connect by 和 start with 关键字
- connect by 和 start with 是层次查询中很重要的关键字。
- connect by 子句说明每行数据按照顺序检索,并规定将表中的数据按照树形结构展示。
- start with 子句用来标识哪个结点作为按树形结构检索数据的根节点。若该子句被忽略,则所有满足查询条件的行都是根节点。
举例:列出所有员工自上而下的组织结构层级,并按员工号排序。
SELECT employee_id,
employee_name,
job_title,
manager_id,
department_id,
LEVEL
FROM dmhr.emp
START WITH employee_id = 100
CONNECT BY PRIOR employee_id = manager_id
ORDER SIBLINGS BY employee_id;

在这个标准的树形目录结构中,首先按照层级关系,再次按照同一层级下的员工号来排序,通过关键字 siblings 保证。prior 一侧为父节点,另一侧为子节点。所以在层次查询中最好从一个起点开始遍历,因此 START WITH 是非常有必要的。否则会将每行做为一个层次查询的起点,形成类似笛卡尔集的效果,没有实际意义。
建议层次查询中 where 过滤条件是在遍历结束之后才起作用的,并且是从已生成的层次数据中再次过滤。
3.2 层次查询-从顶向下
列出 employee_id=114 的员工自顶向下的组织结构图,level 伪列显示出节点层级。
SELECT employee_id, employee_name,job_title,manager_id, department_id,LEVEL
FROM dmhr.emp
START WITH employee_id=114
CONNECT BY PRIOR employee_id=manager_id;

3.3 层次查询-从下而上
列出 employee_id=113 的员工自下而上的组织结构层级。
SELECT employee_id emp_id, employee_name emp_name,job_title,
manager_id, department_id dept_id,LEVEL
FROM dmhr.emp
START WITH employee_id=113
CONNECT BY PRIOR manager_id=employee_id;

3.4 层次查询-展示兄弟节点
列出 employee_id=113 的员工的兄弟节点(同部门员工)。
SELECT employee_id, employee_name, job_title, manager_id, department_id
FROM dmhr.emp
WHERE manager_id= (SELECT manager_id FROM dmhr.emp WHERE employee_id=113);

列出 employee_id=113 的员工的兄弟节点(同级员工)。
WITH tmp AS
(SELECT e.employee_id, e.first_name ||','|| e.last_name employee_name, e.job_id,
e.manager_id, e.department_id, LEVEL lev
FROM employees e
START WITH employee_id=100
CONNECT BY PRIOR employee_id=manager_id)
SELECT *
FROM tmp
WHERE lev=(SELECT lev
FROM tmp
WHERE employee_id=113);

3.5 层次查询中的 where 语法
WHERE 的基本语法,仅列出部门 =100 的员工的组织结构层级,大家可以看到 LEVEL 仍然遵循原有的层级关系,而不是从 100 开始编号,很显然 WHERE 语句是在整个层次查询结束后,再对结果集进行第二次过滤。
SELECT employee_id emp_id, employee_name emp_name, job_title,
manager_id, department_id dept_id,LEVEL
FROM dmhr.emp
WHERE DEPARTMENT_ID=100
START WITH employee_id=100
CONNECT BY PRIOR employee_id=manager_id;
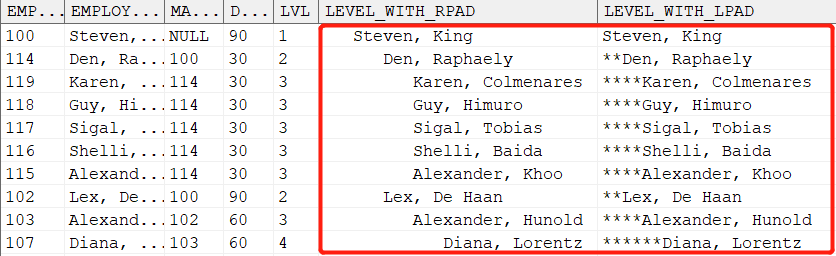
3.6 层次查询中的伪列使用
LEVEL 伪列与其他 Oracle 函数 RPAD、LPAD 的应用,可以得到特殊的显示效果。
- RPAD 是根据层级在左侧填充 3* 层级的空格。
- LPAD 是根据层级在左侧填充 2* 层级的下划线。
SELECT employee_id, employee_name, manager_id, department_id,LEVEL lvl,
RPAD(' ',LEVEL*3)||employee_name level_with_rpad,
LPAD(employee_name,length(employee_name)+(level*2)-2,'*') level_with_lpad
FROM dmhr.emp
START WITH employee_id=100
CONNECT BY PRIOR employee_id=manager_id;
CONNECT_BY_ISLEAF,CONNECT_BY_ROOT 伪列,该例子列出所有 3 级节点员工的上级姓名,及其是否为叶子节点。
SELECT employee_id emp_id, employee_name emp_name,
manager_id,LEVEL,
CONNECT_BY_ISLEAF,
CONNECT_BY_ROOT employee_name root_emp
FROM dmhr.emp
WHERE LEVEL=3
START WITH employee_id=100
CONNECT BY PRIOR employee_id=manager_id;

CONNECT_BY_ISLEAF 字段值为零说明该节点不是叶子节点。
CONNECT_BY_ISCYCLE 的使用,首先需要制造一个循环引用的例子,然后再通过 NOCYCLE 关键字和 CONNECT_BY_ISCYCLE 进行判断。
UPDATE dmhr.emp SET manager_id=107 WHERE employee_id=102;
执行下面的 SQL,会报错,因为层次查询中存在循环。
SELECT employee_id emp_id, employee_name emp_name,job_title,
manager_id, department_id dept_id,LEVEL
FROM dmhr.emp
START WITH employee_id=102
CONNECT BY PRIOR employee_id=manager_id;

加 NOCYCLE 关键字避免循环,同时添加伪列 CONNECT_BY_ISCYCLE 找出导致循环的节点,然后再做进一步的处理。
SELECT employee_id emp_id, employee_name emp_name,job_title,
manager_id, department_id dept_id,LEVEL, CONNECT_BY_ISCYCLE "Cycle"
FROM dmhr.emp
START WITH employee_id=102
CONNECT BY NOCYCLE PRIOR employee_id=manager_id;

查询结果显示 cycle=1 的 107 员工的上下级关系可能出现循环嵌套。
3.7 配合层次查询的函数
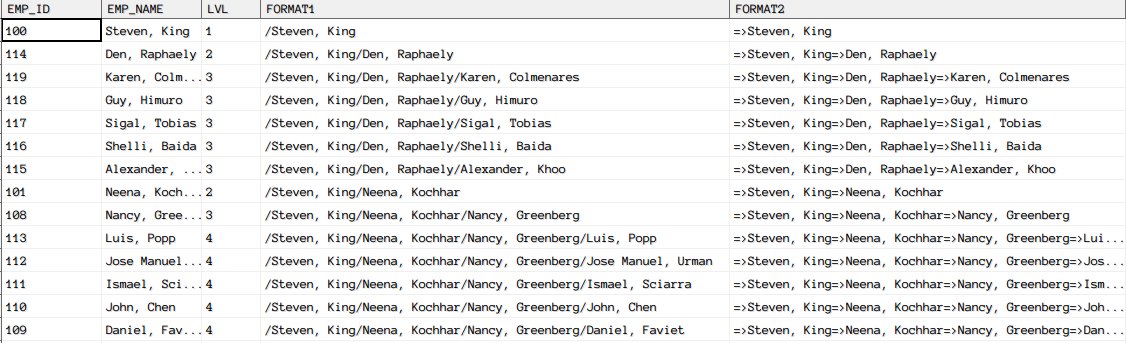
- SYS_CONNECT_BY_PATH 函数
该函数从 START WITH 开始的地方开始遍历,并记下其遍历到的节点,START WITH 开始的地方被视为根节点,将遍历到的路径根据函数中的分隔符,组成一个新的字符串。主要目的就是将父节点到当前节点的【path】按照指定的模式出现。
SELECT employee_id emp_id, employee_name emp_name,LEVEL lvl,
SYS_CONNECT_BY_PATH(employee_name, '/') format1,
SYS_CONNECT_BY_PATH(employee_name, '=>') format2
FROM dmhr.emp
START WITH employee_id=100
CONNECT BY NOCYCLE PRIOR employee_id=manager_id;
- WMSYS.WM_CONCAT 函数
WMSYS.WM_CONCAT 是聚合函数,也可以用在分析函数环境中。WMSYS.WM_CONCAT 返回的是以逗号符号隔开的字符串,它把符合满足条件的数据(无论是数字还是字符串)用逗号分隔符串联起来。以下例子返回每一个经理及其直接下属列表,但不能保证拼接的顺序。
SELECT manager_id,
WMSYS.WM_CONCAT(employee_id) wm_concat_emp_id,
WMSYS.WM_CONCAT(employee_name) wm_concat_emp_name
FROM dmhr.emp
GROUP BY manager_id;

把 WMSYS.WM_CONCAT() 作为分析函数来应用,来达到有序状态的。
SELECT manager_id, MAX(wm_concat_emp_id)
FROM
(
SELECT manager_id,
WMSYS.WM_CONCAT(employee_id)
OVER(PARTITION BY manager_id ORDER BY employee_id) wm_concat_emp_id
FROM dmhr.emp
)
GROUP BY manager_id
ORDER BY manager_id;

使用 SYS_CONNECT_BY_PATH 函数实现上面案例的需求。
SELECT t.manager_id,
MAX (SUBSTR (SYS_CONNECT_BY_PATH (t.employee_id, ','), 2)) str
FROM (SELECT manager_id,
employee_id,
ROW_NUMBER ()
OVER (PARTITION BY manager_id ORDER BY employee_id) rn
FROM dmhr.emp) t
START WITH rn = 1
CONNECT BY rn = PRIOR rn + 1 AND manager_id = PRIOR manager_id
GROUP BY t.manager_id
ORDER BY t.manager_id;

四、参考文档
更多 SQL 语言使用说明,请参考《DM_SQL 语言使用手册》,手册位于数据库安装路径 /dmdbms/doc 文件夹下。如有其他问题,请在达梦技术社区内咨询。