一、数据库软件安装
1.1 解压安装包
1.1.1 Windows 环境
Windows 环境中,如果安装包是压缩包,而非 exe 文件,则需要先对压缩包进行解压,右键解压即可。
1.1.2 Linux 环境
iso 后缀的文件,需要对文件进行挂载,命令如下:
mount -o loop /opt/setup/dm8_20240514_x86_rh6_64.iso /mnt
1.2 安装数据库软件
1.2.1 Windows 环境
1)运行安装程序
双击 “setup.exe” 安装程序后可根据系统配置选择相应语言与时区,点击“确定”按钮继续安装。如下图所示:
2)欢迎页面
点击“下一步”按钮继续安装。如下图所示:
3)许可证协议
在安装和使用之前,该安装程序需要阅读许可协议条款,如接受该协议,则选中“接受”,并点击“下一步”继续安装;若选中“不接受”,将无法进行安装。如下图所示:
4)验证 Key 文件
点击“浏览”按钮,选取 Key 文件,安装程序将自动验证 Key 文件信息。如果是合法的 Key 文件且在有效期内,用户可以点击“下一步”继续安装。如下图所示:
5)选择安装组件
数据库软件安装程序提供四种安装方式:“典型安装”、“服务器安装”、“客户端安装”和“自定义安装”,用户可根据实际情况灵活地选择。如下图所示:
典型安装包括:服务器、客户端、驱动、用户手册、数据库服务。
服务器安装包括:服务器、驱动、用户手册、数据库服务。
客户端安装包括:客户端、驱动、用户手册。
自定义安装包括:用户根据需求勾选组件,可以是服务器、客户端、驱动、用户手册、数据库服务中的任意组合。
生产环境可以根据实际需求选择,一般情况下选择"典型安装"即可。
6)选择安装目录
根据前期规划,指定安装路径。
注意安装路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符等的路径。
7)安装前小结
显示即将进行的安装有关信息,例如产品名称、版本信息、安装类型、安装目录、可用空间、可用内存等信息,用户检查无误后点击“安装”按钮进行软件安装。如下图所示:
8)完成安装
点击“完成”,完成数据库安装。
1.2.2 Linux 环境
严禁使用 root 用户安装数据库及数据库相关操作。必须使用 dmdba 用户执行安装以及数据库相关操作。
- 图形化方式
1)安装运行
执行 ./DMInstall.bin 命令将运行图形化安装。根据系统配置选择相应语言与时区,点击“确定”按钮继续安装。如下图所示:
2)欢迎页面
点击“下一步”按钮继续安装。如下图所示:
3)许可证协议
在安装和使用之前,该安装程序需要用户阅读许可协议条款,用户如接受该协议,则选中“接受”,并点击“下一步”继续安装;用户若选中“不接受”,将无法进行安装。如下图所示:
4)验证 Key 文件
点击“浏览”按钮,选取 Key 文件,安装程序将自动验证 Key 文件信息。如果是合法的 Key 文件且在有效期内,用户可以点击“下一步”继续安装。如下图所示:
5)选择安装组件
数据库软件安装程序提供四种安装方式:“典型安装”、“服务器安装”、“客户端安装”和“自定义安装”,用户可根据实际情况灵活地选择。如下图所示:
典型安装包括:服务器、客户端、驱动、用户手册、数据库服务。
服务器安装包括:服务器、驱动、用户手册、数据库服务。
客户端安装包括:客户端、驱动、用户手册。
自定义安装包括:用户根据需求勾选组件,可以是服务器、客户端、驱动、用户手册、数据库服务中的任意组合。
生产环境可以根据实际需求选择,一般情况下选择"典型安装"即可。
6)选择安装目录
根据前期规划,指定安装路径。
注意安装路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符等的路径。
7)安装前小结
显示即将进行安装的相关信息,例如产品名称、版本信息、安装类型、安装目录、可用空间、可用内存等信息,用户检查无误后点击“安装”按钮进行软件的安装。如下图所示:
8)注册数据库服务
当安装进度完成时将会弹出对话框,提示使用 root 系统用户执行相关命令。用户可根据对话框的说明完成相关操作,之后可关闭此对话框,点击“完成”按钮结束安装。如下图所示:

9)完成安装
点击“完成”,完成数据库安装。
- 命令行方式
1)执行安装命令
在终端进入到安装程序所在文件夹,执行以下命令进行命令行安装:
[dmdba@~]# /mnt/DMInstall.bin -i
2)选择安装语言
根据系统配置选择相应语言,输入选项,回车进行下一步。如下所示:
Installer Language:
[1]: 简体中文
[2]: English
Please select the installer's language [2]:1
解压安装程序.........
欢迎使用达梦数据库安装程序
3)验证 key 文件
可以选择是否输入 Key 文件路径。不输入则进入下一步安装,输入 Key 文件路径,安装程序将显示 Key 文件的详细信息,如果是合法的 Key 文件且在有效期内,可以继续安装。如下所示:
是否输入Key文件路径? (Y/y:是 N/n:否) [Y/y]:Y
请输入Key文件的路径地址 [dm.key]:/opt/setup/dm.key
有效日期: 2024-06-25
服务器颁布类型: 企业版
发布类型: 试用版
用户名称: 达梦公司产品试用
授权用户数: 无限制
并发连接数: 无限制
4)输入时区
可以选择的时区信息。如下所示:
是否设置时区? (Y/y:是 N/n:否) [Y/y]:Y
设置时区:
[ 1]: GTM-12=日界线西
[ 2]: GTM-11=萨摩亚群岛
[ 3]: GTM-10=夏威夷
[ 4]: GTM-09=阿拉斯加
[ 5]: GTM-08=太平洋时间(美国和加拿大)
[ 6]: GTM-07=亚利桑那
[ 7]: GTM-06=中部时间(美国和加拿大)
[ 8]: GTM-05=东部部时间(美国和加拿大)
[ 9]: GTM-04=大西洋时间(美国和加拿大)
[10]: GTM-03=巴西利亚
[11]: GTM-02=中大西洋
[12]: GTM-01=亚速尔群岛
[13]: GTM=格林威治标准时间
[14]: GTM+01=萨拉热窝
[15]: GTM+02=开罗
[16]: GTM+03=莫斯科
[17]: GTM+04=阿布扎比
[18]: GTM+05=伊斯兰堡
[19]: GTM+06=达卡
[20]: GTM+07=曼谷,河内
[21]: GTM+08=中国标准时间
[22]: GTM+09=汉城
[23]: GTM+10=关岛
[24]: GTM+11=所罗门群岛
[25]: GTM+12=斐济
[26]: GTM+13=努库阿勒法
[27]: GTM+14=基里巴斯
请选择设置时区 [21]:21
5)选择安装类型
数据库软件安装程序提供四种安装方式:“典型安装”、“服务器安装”、“客户端安装”和“自定义安装”,用户可根据实际情况灵活地选择。如下所示:
典型安装包括:服务器、客户端、驱动、用户手册、数据库服务。
服务器安装包括:服务器、驱动、用户手册、数据库服务。
客户端安装包括:客户端、驱动、用户手册。
自定义安装包括:用户根据需求勾选组件,可以是服务器、客户端、驱动、用户手册、数据库服务中的任意组合。
生产环境可以根据实际需求选择,一般情况下选择"典型安装"即可。
安装类型:
1 典型安装
2 服务器
3 客户端
4 自定义
请选择安装类型的数字序号 [1 典型安装]:1
所需空间: 2201M
6)选择安装路径
输入数据库软件的安装路径,不输入则使用默认路径,默认路径为 $HOME/dmdbms (如果安装用户为 root ,则默认安装路径为 /opt/dmdbms ,但不建议使用 root 系统用户来安装)。如下所示:
请选择安装目录 [/home/dmdba/dmdbms]:/opt/dmdbms
可用空间: 9G
注意安装路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符等的路径。
7)安装小结
安装程序将打印用户之前输入的部分安装信息。如下所示:
是否确认安装路径(/opt/dmdbms)? (Y/y:是 N/n:否) [Y/y]:Y
安装前小结
安装位置: /opt/dmdbms
所需空间: 2201M
可用空间: 9G
版本信息: 企业版
有效日期: 2024-06-25
安装类型: 典型安装
8)安装
是否确认安装? (Y/y:是 N/n:否):Y
2024-05-21 12:14:48
[INFO] 安装达梦数据库...
2024-05-21 12:14:48
[INFO] 安装 基础 模块...
2024-05-21 12:14:51
[INFO] 安装 服务器 模块...
2024-05-21 12:14:52
[INFO] 安装 客户端 模块...
2024-05-21 12:14:53
[INFO] 安装 驱动 模块...
2024-05-21 12:14:54
[INFO] 安装 手册 模块...
2024-05-21 12:14:54
[INFO] 安装 服务 模块...
2024-05-21 12:14:55
[INFO] 移动日志文件。
2024-05-21 12:14:55
[INFO] 安装达梦数据库完成。
请以root系统用户执行命令:
/opt/dmdbms/script/root/root_installer.sh
安装结束
9)注册数据库服务
当安装进度完成时将会弹出对话框,提示使用 root 系统用户执行相关命令。用户可根据对话框的说明完成相关操作,之后可关闭此对话框,点击“完成”按钮结束安装。如下所示:
[dmdba@~]# su - root
密码:<输入密码>
[root@~]# /opt/dmdbms/script/root/root_installer.sh
移动 /opt/dmdbms/bin/dm_svc.conf 到/etc目录
创建DmAPService服务
Created symlink /etc/systemd/system/multi-user.target.wants/DmAPService.service → /usr/lib/systemd/system/DmAPService.service.
创建服务(DmAPService)完成
启动DmAPService服务
1.3 初始化数据库实例
1.3.1 实例参数介绍
本章节列举常用参数,如需更改其它参数,请参考安装路径 doc 目录下的《dminit 使用手册》。
- PATH
初始数据库存放的路径。默认路径为 dminit 当前所在的工作目录。文件路径长度最大为 256 个字符,PATH 为可选参数。
生产环境中,该路径可根据前期规划的路径进行修改,一般为最大空间路径。
- EXTENT_SIZE
数据文件使用的簇大小,即每次分配新的段空间时连续的页数。取值:16、32、64。单位:页数。缺省值 16。EXTENT_SIZE 为可选参数。
生产环境中该参数建议设置为 32,或依据用户实际需求进行指定。
- PAGE_SIZE
数据文件使用的页大小。取值:8、16、32,单位:K。默认值为 8。可选参数。选择的页大小越大,则支持的元组长度也越大,但同时空间利用率可能下降。
在达梦数据库中,页大小可以为 8 KB、16 KB 或者 32 KB,一旦创建好了数据库,在该库的整个生命周期内,页大小都不能够改变。如果系统中存在或者以后可能存在含有较长的字符串类型的表,建议该参数设置为 16 或者 32。页大小设置越大,最后数据文件的物理大小就会越大,系统运行时,每次从磁盘调入内存的数据单位也就越大。除了每个字段的最大长度限制外,每条记录总长度不能大于页面大小的一半。如下表所示:
| 数据库页大小 | 每个字符类型字段实际最大长度(字节) |
|---|---|
| 4K | 1938 |
| 8K | 3878 |
| 16K | 8000 |
| 32K | 8138 |
生产环境中该参数建议设置为 32,或依据用户实际需求进行指定。
- LOG_SIZE
重做日志文件大小。取值:32 位版本时,取值为 256 和 2048 之间的整数;64 位版本时,取值为 256 和 8192 之间的整数,单位 MB。默认值为 4096MB。可选参数。每个数据库实例至少有两个重做日志文件,循环使用,LOG_SIZE 设置每个重做日志文件的大小。
生产环境中该参数建议给 2048,或依据用户实际需求进行指定。
- CASE_SENSITIVE
标识符大小写敏感。当大小写敏感时,小写的标识符应当用 "" 括起,否则被系统自动转换为大写;当大小写不敏感时,系统不会转换标识符的大小写,在标识符比较时也不能区分大小写。取值:Y、y、1 表示敏感;N、n、0 表示不敏感。默认值为 Y 。可选参数。
DM 为了兼容不同的数据库,在初始化数据库的时候有一个参数字符串比较大小写敏感,用于确定数据库对象及数据是否区分大小写,默认为区分,不可更改。建议从 MYSQL 和 SQLSERVER 迁移过来的系统,使用大小写不敏感,ORACLE 迁移过来的系统,使用大小写敏感,以便和原来系统匹配。
生产环境中该参数依据用户实际需求进行指定。
更多内容可参考:详解 DM 数据库字符串大小写敏感。
- CHARSET/UNICODE_FLAG
字符集选项。取值:0 代表 GB18030,1 代表 UTF-8,2 代表韩文字符集 EUC-KR。默认为 0。可选参数。
GB18030 编码向下兼容 GBK 和 GB2312,兼容的含义是不仅字符兼容,而且相同字符的编码也相同。GB18030 收录了所有 Unicode3.1 中的字符,包括中国少数民族字符,GBK 不支持的韩文字符等等,也可以说是世界大多民族的文字符号都被收录在内。
Unicode Transformation Format-8bit 是用以解决国际上字符的一种多字节编码。它对英文使用 8 位(即一个字节),中文使用 24 为(三个字节)来编码。UTF-8 包含全世界所有国家需要用到的字符,是国际编码,通用性强。UTF-8 编码的文字可以在各国支持 UTF8 字符集的浏览器上显示。
建议采用默认值 GB18030,如果需要国际字符可以采用 Unicode。GB18030 数字字母占 1 个字节,普通汉字占 2 个字节,部分繁体及少数民族文字占 4 字节。Unicode 在达梦中采用 UTF-8 编码格式,欧洲的字母字符占 1 到 2 个字节,亚洲的大部分字符占 3 个字节,附加字符为 4 个字节。如果只存储中文和字母数字,一般来说 GB18030 更节省空间一些。生产环境中该参数可依据用户实际需求进行指定。
- DB_NAME
初始化数据库名称,默认为 DAMENG。名称为字符串,长度不能超过 128 个字符。可选参数。WINDOWS 下文件名不能包含字符 /\*:? <>"|,LINUX 下文件名不能包含字符 /\:<>"|。
生产环境中该参数一般保持默认,或依据用户实际需求进行指定。
- INSTANCE_NAME
初始化数据库实例名称,默认为 DMSERVER。名称为字符串,长度不能超过 128 个字符。可选参数。
生产环境中该参数一般保持默认,或依据用户实际需求进行指定。
- PORT_NUM
初始化时设置 dm.ini 中的监听端口号,默认 5236 。服务器配置此参数,有效值范围(1024~65534),发起连接端的端口在 1024~65535 之间随机分配。可选参数。
生产环境中该参数一般保持默认,或依据用户实际需求进行指定。
- SYSDBA_PWD
初始化时设置 SYSDBA 的密码,不允许缺省。密码为字符串,必须同时包含大写字母、小写字母、数字,不允许与用户名重名,密码长度须大于或等于 INI 参数 PWD_MIN_LEN 所设定的值且小于 48,关于参数 PWD_MIN_LEN 的详细说明请参考《DM8 系统管理员手册》。
如果密码中包含特殊字符,则需要按照规定的书写规范进行书写,详细请参考《DM8_DIsql 使用手册》中关于特殊字符的书写规范相关介绍。
数据库创建成功后,SYSDBA 可通过修改用户密码语句修改自己的密码。
- SYSAUDITOR_PWD
初始化时设置 SYSAUDITOR 的密码,不允许缺省。密码为字符串,必须同时包含大写字母、小写字母、数字,不允许与用户名重名,密码长度须大于或等于 INI 参数 PWD_MIN_LEN 所设定的值且小于 48,关于参数 PWD_MIN_LEN 的详细说明请参考《DM8 系统管理员手册》。
如果密码中包含特殊字符,则需要按照规定的书写规范进行书写,详细请参考《DM8_DIsql 使用手册》中关于特殊字符的书写规范相关介绍。
数据库创建成功后,SYSAUDITOR 可通过修改用户密码语句修改自己的密码。
注意用户在安装数据库初始化实例时,必须设置数据库系统用户的密码,并保证一定的密码强度,以保障数据安全性。
1.3.2 Windows 环境
Windows 环境初始化实例,例如初始化参数设置如下:页大小(PAGE_SIZE)为 32,日志大小(LOG_SIZE)为 2048,大小写(CASE_SENSITIVE)为敏感,字符集(CHARSET)为 GB18030,SYSDBA_PWD 和 SYSAUDITOR_PWD 为配置数据库 SYSDBA 用户和 SYSAUDITOR 用户的登录密码,需要用户自定义配置,且需保证一定的密码强度。如需设置其它参数,请参考安装路径 doc 目录下的《dminit 使用手册》。
1)选择操作方式
在创建数据库实例、删除数据库实例、注册数据库服务和删除数据库服务四种操作方式中,选择创建数据库实例选项,点击“开始”进入下一步。
2)创建数据库模板
系统提供三套数据库模板供用户选择:一般用途、联机分析处理和联机事务处理,用户可根据自身的用途选择相应的模板。通常选择“一般用途”,如下图所示:
3)选择数据库目录
根据前期规划,通过浏览或是输入的方式选择数据库所在目录。如下图所示:
注意路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符等的路径。
4)输入数据库标识
可输入数据库名称、实例名、端口号等参数。如下图所示:
5)数据库文件所在位置
通过选择或输入确定数据库控制、数据库日志等文件的所在位置,并可通过右侧功能按钮,对文件进行添加或删除。如下图所示:
6)数据库初始化参数
可输入数据库相关参数,如簇大小、页大小、日志文件大小、选择字符集、是否大小写敏感等。如下图所示:
注意实际环境中,簇大小建议选择 32页,页大小选择 32K,日志大小选择 2048M,字符集和大小写敏感需要和应用厂商对接后,再进行选择。
7)口令管理
用户在数据库初始化实例时,需设置数据库系统用户的密码,并保证密码强度,以保障数据安全性。如下图所示:
用户可输入 SYSDBA,SYSAUDITOR 的密码,如果安装版本为安全版,将会增加 SYSSSO 用户的密码设置。
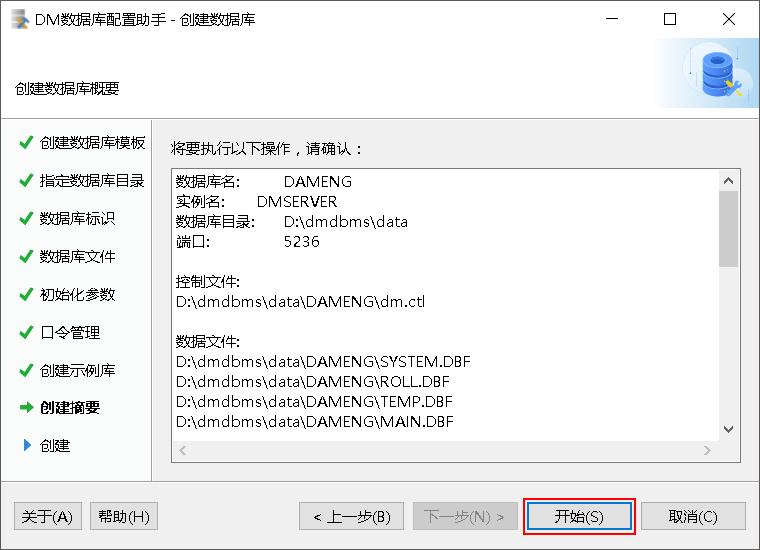
8)创建数据库摘要
在安装数据库之前,将显示数据库配置工具设置的相关参数。如下图所示:
9)安装初始化数据库
安装过程如下图所示:
10)安装结束
安装结束时,点击完成即可。如下图所示:
1.3.3 Linux 环境
Linux 环境初始化实例可通过两种方式:图形化方式和命令行方式,以下介绍详细步骤。
- 图形化方式
初始化实例的示例如下:设置页大小(PAGE_SIZE)为 32,日志大小(LOG_SIZE)为 2048,大小写(CASE_SENSITIVE)为敏感,字符集(CHARSET)为 GB18030,SYSDBA_PWD 和 SYSAUDITOR_PWD 为配置数据库 SYSDBA 用户和 SYSAUDITOR 用户的登录密码,需要用户自定义配置,且需保证一定的密码强度。
其它参数默认,如需更改其它参数,请参考安装路径 doc 目录下的《dminit 使用手册》。
1)选择操作方式
在创建数据库实例、删除数据库实例、注册数据库服务和删除数据库服务四种操作方式中,选择创建数据库实例选项,点击“开始”进入下一步。
2)创建数据库模板
系统提供三套数据库模板供用户选择:一般用途、联机分析处理和联机事务处理,用户可根据自身的用途选择相应的模板。通常选择“一般用途”如下图所示:
3)选择数据库目录
根据前期规划,通过浏览或是输入的方式选择数据库所在目录。如下图所示:
注意路径里的目录名由英文字母、数字和下划线等组成,不建议使用包含空格和中文字符等的路径。
4)输入数据库标识
可输入数据库名称、实例名、端口号等参数。如下图所示:
5)数据库文件所在位置
通过选择或输入确定数据库控制、数据库日志等文件的所在位置,并可通过右侧功能按钮,对文件进行添加或删除。如下图所示:
6)数据库初始化参数
可输入数据库相关参数,如簇大小、页大小、日志文件大小、选择字符集、是否大小写敏感等。如下图所示:
注意实际环境中,簇大小建议选择 32页,页大小选择 32K,日志大小选择 2048M,字符集和大小写敏感需要和应用厂商对接后,再进行选择。
7)口令管理
用户在数据库初始化实例时,需设置数据库系统用户的密码,并保证密码强度,以保障数据安全性。如下图所示:
8)创建数据库摘要
在安装数据库之前,将显示数据库配置工具设置的相关参数。如下图所示:
9)安装初始化数据库
安装过程如下图所示:
10)注册数据库服务
当安装进度完成时将会弹出对话框,提示使用 root 系统用户执行相关命令。用户可根据对话框的说明完成相关操作,之后可关闭此对话框,点击“完成”按钮结束安装。如下图所示:

11)安装结束
安装结束时,点击完成即可。如下图所示:
- 命令行方式
1)初始化过程
初始化实例的示例如下:设置页大小(PAGE_SIZE)为 32,日志大小(LOG_SIZE)为 2048,大小写(CASE_SENSITIVE)为敏感,字符集(CHARSET)为 GB18030,SYSDBA_PWD 和 SYSAUDITOR_PWD 为配置数据库 SYSDBA 用户和 SYSAUDITOR 用户的登录密码,需要用户自定义配置,且需保证一定的密码强度。
如需更改其它参数,请参考安装路径 doc 目录下的《dminit 使用手册》。
[dmdba@localhost bin]$ ./dminit PATH=/opt/dmdbms/data PAGE_SIZE=32 LOG_SIZE=2048 CHARSET=0 CASE_SENSITIVE=Y SYSDBA_PWD=****** SYSAUDITOR_PWD=******
initdb V8
db version: 0x7000c
file dm.key not found, use default license!
License will expire on 2025-09-18
Normal of FAST
Normal of DEFAULT
Normal of RECYCLE
Normal of KEEP
Normal of ROLL
log file path: /opt/dmdbms/data/DAMENG/DAMENG01.log
log file path: /opt/dmdbms/data/DAMENG/DAMENG02.log
write to dir [/opt/dmdbms/data/DAMENG].
create dm database success. 2025-04-03 11:10:57
注意1、实际环境中,簇大小建议选择 32页,页大小选择 32K,日志大小选择 2048M,字符集和大小写敏感需要根据实际业务需求进行设置。
2、用户在初始化时,需设置数据库系统用户初始密码,并保证一定的密码强度,以保障数据安全性。
2)创建实例服务
[dmdba@dmdsc03 ~]$ su - root
密码:<输入密码>
[root@~]# /opt/dmdbms/script/root/dm_service_installer.sh -t dmserver -dm_ini /opt/dmdbms/data/DAMENG/dm.ini -p DMSERVER
Created symlink /etc/systemd/system/multi-user.target.wants/DmServiceDMSERVER.service → /usr/lib/systemd/system/DmServiceDMSERVER.service.
创建服务(DmServiceDMSERVER)完成
3)启动实例服务
[dmdba@dmdsc03 ~]$ /opt/dmdbms/bin/DmServiceDMSERVER start
Starting DmServiceDMSERVER: [ OK ]
二、数据库实例配置
2.1 实例参数优化调整
实例参数优化可通过手动方式和自动方式进行调整。为增强参数优化的适用性,降低参数修改的过程风险,建议使用达梦数据库提供的 AutoParaAdj.sql 脚本进行实例参数优化。
AutoParaAdj.sql 脚本详细内容和具体使用步骤见:参数自动优化脚本工具-DM8.zip
注意脚本执行成功后,须重启数据库使参数修改生效。
2.2 开启本地归档
2.2.1 归档概述
在达梦数据库归档模式下,数据库会同时将重做日志写入联机日志文件和归档日志文件中分别进行存储。采用归档模式会对系统的性能产生影响,然而,当系统一旦出现介质故障,如磁盘损坏时,利用归档日志,系统可被恢复至故障发生的前一刻, 也可以还原到指定的时间点,而如果没有归档日志文件,则只能利用备份进行恢复。因此,系统在归档模式下运行会更安全,当出现故障时,丢失数据的可能性更小。
2.2.2 开启方法
开启数据库归档可通过两种方式实现。方式一:通过 SQL 命令方式开启归档;方式二:通过修改数据库配置文件方式开启归档。下面详细介绍这两种配置方式。
数据库归档目录位置:/dmarch。
| 参数名称 | 默认值 | 推荐值 | 说明 |
|---|---|---|---|
| ARCH_FILE_SIZE | 128 | 2048 | 本地单个归档文件最大值(单位:M)。 |
| ARCH_SPACE_LIMIT | 0 | 102400 | 归档大小上限,0 表示无限制(按数据量的 1/5 保留,例如 500G 数据,保留 100G 归档)。 |
方法一:SQL 命令方式开启归档
登录数据库执行如下 SQL 语句:
ALTER DATABASE MOUNT;
ALTER DATABASE ARCHIVELOG;
ALTER DATABASE ADD ARCHIVELOG 'DEST=/dmarch, TYPE=LOCAL, FILE_SIZE=2048, SPACE_LIMIT=102400';
ALTER DATABASE OPEN;
方法二:修改数据库配置文件方式开启归档
##修改数据库实例的 /dmdata/DAMEGN/dm.ini文件中 ARCH_INI 参数值
vi /dmdata/DAMENG/dm.ini
##将 ARCH_INI 值改为 1,保存后退出
ARCH_INI = 1 #开启归档功能
##新增文件dmarch.ini
vi /dmdata/DAMENG/dmarch.ini
##新增如下内容
[ARCHIVE_LOCAL1]
ARCH_TYPE = LOCAL
ARCH_DEST = /dmarch
ARCH_FILE_SIZE = 2048
ARCH_SPACE_LIMIT = 102400
##最后重启数据库完成归档配置
注意1. 相关路径及归档大小上限参数需按照实际要求配置,建议以生产环境每日增量数据的 1 至 2 倍设置归档上限;
2. 不论使用以上哪种方法,均需要对数据库进行 mount 或重启操作。
2.3 配置 SQL 日志
2.3.1 SQL 日志概述
SQL 日志内容包含系统各会话执行的 SQL 语句、参数信息、错误信息等。SQL 跟踪日志主要用于分析错误和分析性能问题,基于跟踪日志可以对系统运行状态有一个分析,比如,可以挑出系统现在执行速度较慢的 SQL 语句,进而对其进行优化。
打开 SQL 日志会对系统的性能会有较大影响,一般用于查错和调优的时候才会打开,默认情况下系统是关闭 SQL 跟踪日志的。若需要 SQL 跟踪日志但对日志的实时性没有严格的要求,又希望系统有较高的效率,可以设置 sqllog.ini 参数 SQL_TRACE_MASK 和 MIN_EXEC_TIME 只记录关注的相关记录,减少日志总量;设置 sqllog.ini 参数 ASYNC_FLUSH 打开 SQL 日志异步刷盘功能,以提高系统性能。
2.3.2 开启 SQL 日志
- 创建 SQL 日志存放目录。
su - dmdba
mkdir -p /data/dmdbms/log/logcommit
- 检查 SVR_LOG 参数。
select * from v$parameter where name like ‘SVR_LOG%’;
- 修改实例路径下 sqllog.ini 文件如下:设置 sql 日志为异步,按照文件大小进行切换,每个 1024M,20 个文件循环写。如果内存充足(≥32G),参数 BUF_TOTAL_SIZ、BUF_SIZE 和 BUF_KEEP_CNT 建议做如下调整。
(1)参数 BUF_TOTAL_SIZE 值由 10240 修改为 1024000;
(2)参数 BUF_SIZE 值由 1024 修改为 10240;
(3)参数 BUF_KEEP_CNT 值由 6 修改为 20。
cd /data/dmdata/DAMENG
vi sqllog.ini
BUF_TOTAL_SIZE = 1024000 #SQLs Log Buffer Total Size(K)(1024~1024000)
BUF_SIZE = 10240 #SQLs Log Buffer Size(K)(50~409600)
BUF_KEEP_CNT = 20 #SQLs Log buffer keeped count(1~100)
[SLOG_ALL]
FILE_PATH = /data/dmdbms/log/logcommit #sql 日志生成路径
PART_STOR = 0
SWITCH_MODE = 2
SWITCH_LIMIT = 1024 #每个日志文件 1024M
ASYNC_FLUSH = 1
FILE_NUM = 20 #循环收集 20 个可以根据实际情况做调整
ITEMS = 0
SQL_TRACE_MASK = 1
MIN_EXEC_TIME = 0
USER_MODE = 0
USERS =
- 执行调用存储过程生效配置文件,并开启 SQL LOG 日志。
SP_REFRESH_SVR_LOG_CONFIG();
sp_set_para_value(1,'SVR_LOG',1);
--检查 SVR_LOG 参数。
select * from v$parameter where name like ‘SVR_LOG’;
- 检查日志生成情况。
ls /data /logcommit
2.4 数据库备份
2.4.1 备份概述
达梦数据库中的数据存储在数据库的物理数据文件中,数据文件按照页、簇和段的方式进行管理,数据页是最小的数据存储单元。任何一个对达梦数据库的操作,其根本都是对某个数据文件页的读写操作。因此,DM 备份的本质就是从数据库文件中拷贝有效的数据页保存到备份集中,这里的有效数据页包括数据文件的描述页和被分配使用的数据页。
数据库备份可按照实际需求进行手动备份或设置定时备份。手动备份详细内容可参考数据库安装目录 doc 路径下《DM8 备份与还原》手册。以下主要详细介绍定时备份相关内容。
2.4.2 设置定时备份
达梦数据库提供定时备份功能。在设置定时备份前,应依据实际业务需求和数据量大小,采用不同的备份策略,达梦数据库常用备份策略包括全量备份 + 删除和全量备份 + 增量备份 + 删除。可使用命令行或图形化方式设置定时备份。
1. 全量备份 + 删除(推荐使用)
此备份策略适用于数据量小于 100G 的场景下。注意开启数据库归档,确定备份路径。
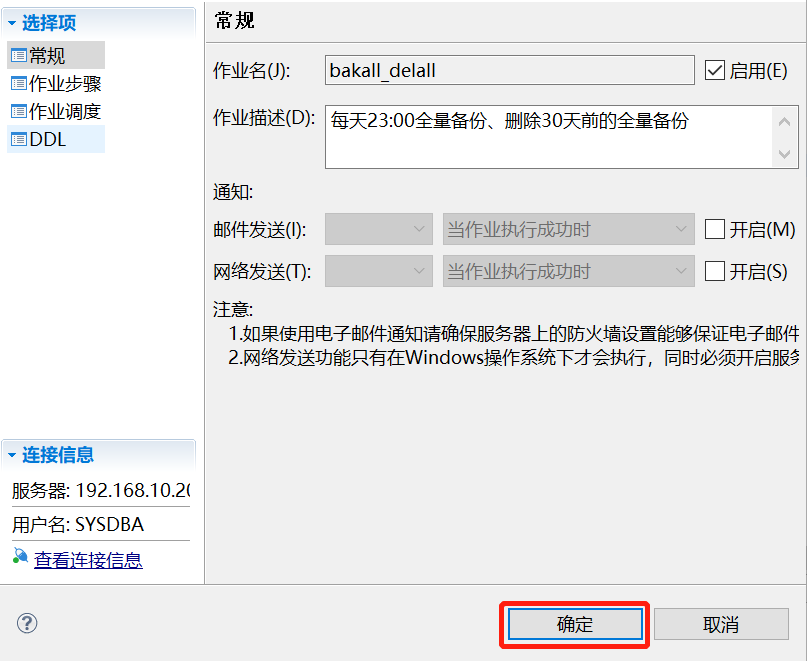
例如设置每天 23:00 全量备份、删除 30 天前的全量备份。备份路径为 /opt/dmdbms/data/DAMENG/bak。
注意DM8 数据库中,使用命令行配置备份任务时,注意 SP_ADD_JOB_STEP 的 SUCC_ACTION 和 FAIL_ACTION 参数可能存在一定差异,详细可参考达梦数据库安装目录 doc 路径下《作业系统使用手册》。
方式一:命令行配置备份任务
call SP_INIT_JOB_SYS(1);
call SP_CREATE_JOB('bakall_delall',1,0,'',0,0,'',0,'每天 23:00 全量备份、删除 30 天前的全量备份');
call SP_JOB_CONFIG_START('bakall_delall');
call SP_ADD_JOB_STEP('bakall_delall', 'bakall', 6, '01020000/opt/dmdbms/data/DAMENG/bak', 3, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_STEP('bakall_delall', 'delall', 0, 'SF_BAKSET_BACKUP_DIR_ADD(''DISK'',''/opt/dmdbms/data/DAMENG/bak'');
CALL SP_DB_BAKSET_REMOVE_BATCH(''DISK'',SYSDATE-30);', 1, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakall_delall', 'bakall_delall_time01', 1, 1, 1, 0, 0, '23:00:00', NULL, '2019-01-01 01:01:01', NULL, '');
call SP_JOB_CONFIG_COMMIT('bakall_delall');
方式二:图形化配置备份任务
(1)创建备份任务,定义作业名。在左侧导航栏中,找到代理选项,右键新建代理任务,新建成功后,点击代理的下拉菜单,找到作业选项,右键新建作业,配置好作业名和作业描述。如下图:

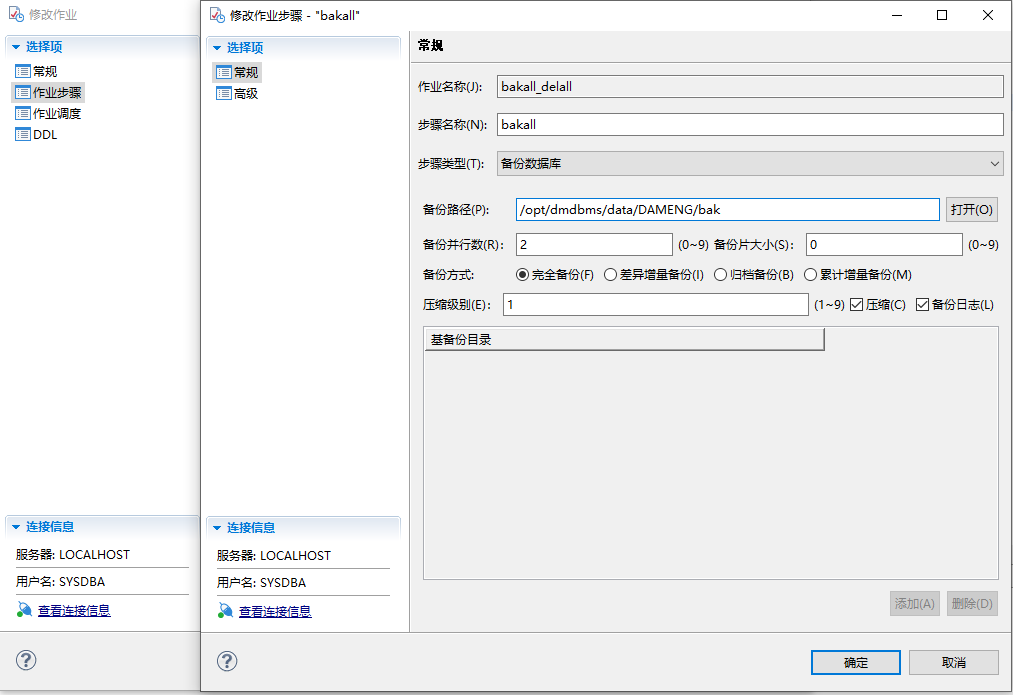
(2)添加备份规则。在作业步骤点击添加后,在步骤类型中选择备份数据库,备份方式选择完全备份和压缩选项,添加好备份路径。如下图:
(3)添加备份保留规则。备份规则配置好后,添加一个 sql 脚本,将备份保留策略添加进去,可选择保留 30 天,具体保留时间可以和用户商议后进行修改。如下图:

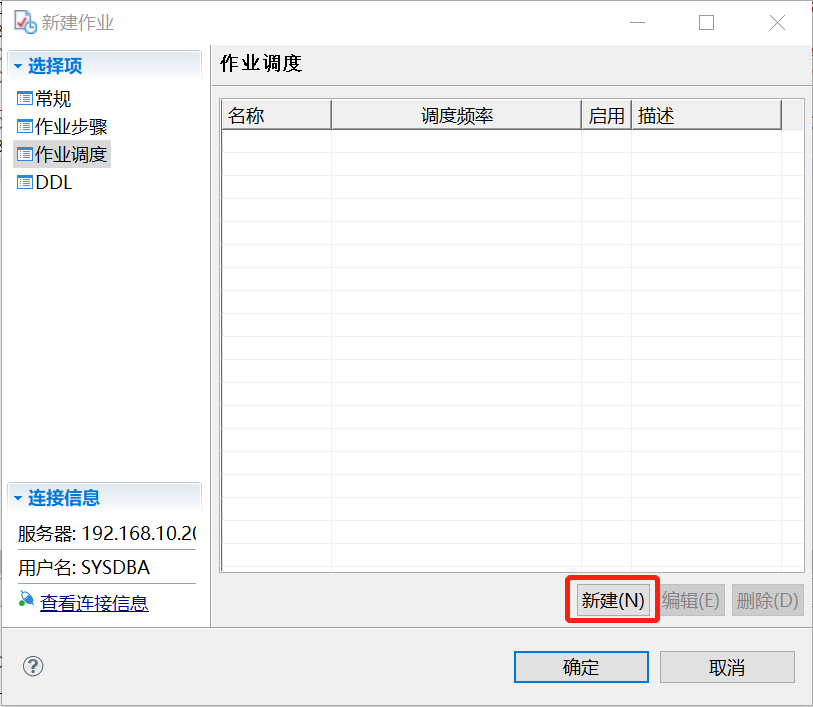
(4)添加作业调度。在作业步骤选择项配置完成后,选择作业调度选择项,在右侧导航栏中,选择新建按钮,如下图:
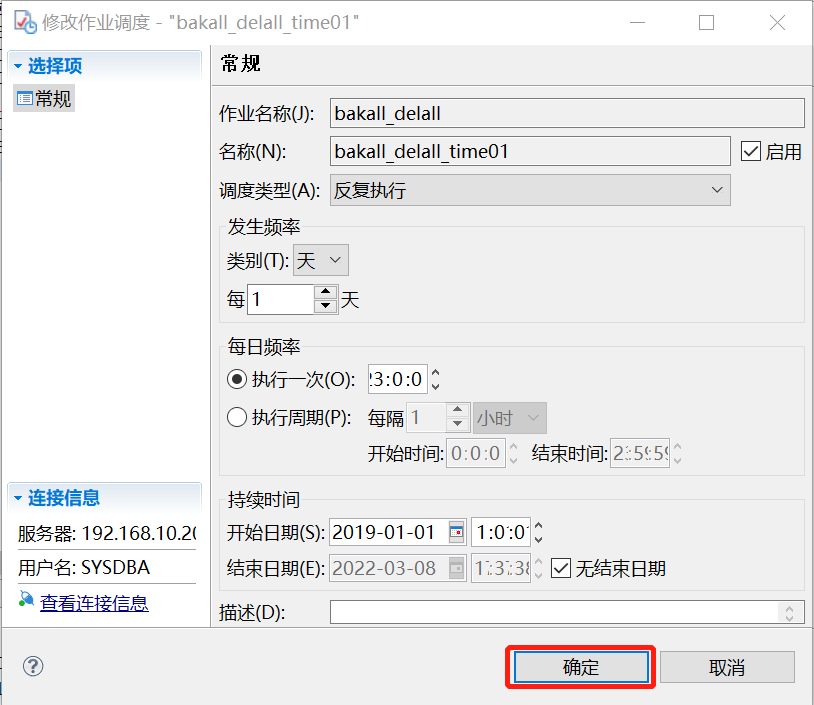
(5)配置作业调度规则。此配置项中,可以配置调度类型,每天的全量备份的话,调度类型选择反复执行,频率为每天,执行时间为每天的 23 点,配置好后,点击确认即可。具体备份执行时间,可依据用户现场实际要求而定。
(6)配置完成。所有配置完成后,点击页面的确定按钮,即可完成配置。如下图:
2. 全量备份 + 增量备份 + 删除
此备份策略适用于数据量大于 100G 并且小于 3T 的场景下。注意开启数据库归档,确定备份路径。
例如:设置每月第一个周六 23:00 全量备份。每天(除周六) 23:00 增量备份、删除 30 天前的增量备份、删除 40 天前的全量备份。全量备份路径为 /opt/dmdbms/data/DAMENG/bak/all,增量备份路径为 /opt/dmdbms/data/DAMENG/bak/add。
方式一:命令行配置备份任务
--设置 2 分钟后自动进行一次全量备份
call SP_INIT_JOB_SYS(1);
call SP_CREATE_JOB('bakall_one',1,0,'',0,0,'',0,'执行一次全量备份');
call SP_JOB_CONFIG_START('bakall_one');
call SP_ADD_JOB_STEP('bakall_one', 'bakall', 6, '01020000/opt/dmdbms/data/DAMENG/bak/all', 1, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakall_one', 'bakall_one_time01', 1, 0, 0, 0, 0, NULL, NULL, SYSDATE()+0.0014, NULL, '');
call SP_JOB_CONFIG_COMMIT('bakall_one');
--设置全量备份
call SP_CREATE_JOB('bakall',1,0,'',0,0,'',0,'每月第一个周六23:00全量备份');
call SP_JOB_CONFIG_START('bakall');
call SP_ADD_JOB_STEP('bakall', 'bakall', 6, '01020000/opt/dmdbms/data/DAMENG/bak/all', 1, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakall', 'bakall_time01', 1, 4, 1, 7, 0, '23:00:00', NULL, '2019-01-01 01:01:01', NULL, '');
call SP_JOB_CONFIG_COMMIT('bakall');
--设置增量备份 + 删除备份
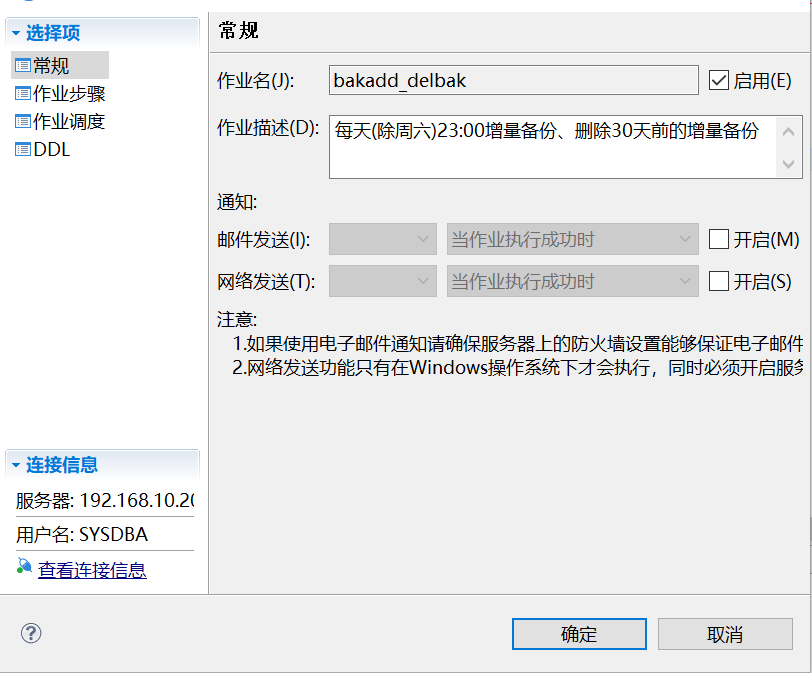
call SP_CREATE_JOB('bakadd_delbak',1,0,'',0,0,'',0,'每天(除周六)23:00增量备份、删除30天前的增量备份、删除40天前的全量备份');
call SP_JOB_CONFIG_START('bakadd_delbak');
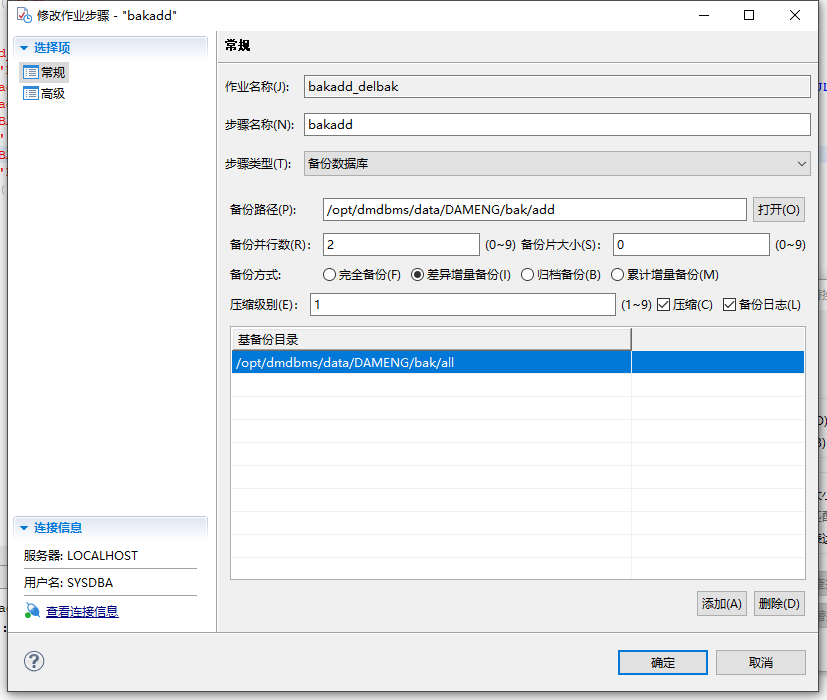
call SP_ADD_JOB_STEP('bakadd_delbak', 'bakadd', 6, '11020000/opt/dmdbms/data/DAMENG/bak/all|/opt/dmdbms/data/DAMENG/bak/add', 3, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_STEP('bakadd_delbak', 'delbak', 0, 'SF_BAKSET_BACKUP_DIR_ADD(''DISK'',''/opt/dmdbms/data/DAMENG/bak/add'');
CALL SP_DB_BAKSET_REMOVE_BATCH(''DISK'',SYSDATE-30);
SF_BAKSET_BACKUP_DIR_ADD(''DISK'',''/opt/dmdbms/data/DAMENG/bak/all'');
CALL SP_DB_BAKSET_REMOVE_BATCH(''DISK'',SYSDATE-40);', 1, 1, 0, 0, NULL, 0);
call SP_ADD_JOB_SCHEDULE('bakadd_delbak', 'bakadd_delbak_time01', 1, 2, 1, 63, 0, '23:00:00', NULL, '2019-01-01 01:01:01', NULL, '');
call SP_JOB_CONFIG_COMMIT('bakadd_delbak');
方式二:图形化配置备份任务
(1)创建备份任务,定义作业名。在左侧导航栏中,找到代理选项,右键新建代理任务,新建成功后,点击下拉菜单,找到作业选项,右键新建作业,配置好作业名和作业描述。如下图:
(2)添加作业步骤。在常规选择项设置好后,不用点击确定按钮,直接点击作业步骤选择项,点击添加按钮,进行作业步骤的添加操作。如下图:

(3)添加备份规则。在作业步骤点击添加后,在步骤类型中,选择备份数据库,备份方式选择增量压缩备份,选择好备份路径,在基备份目录中,选择全量备份所在的路径,如下图:
(4)添加备份保留规则。备份规则配置好后,在添加一个 sql 脚本,将备份保留策略添加进去,可选择保留 30 天,具体保留时间可以和用户商议后进行修改。如下图:

(5)添加作业调度。在作业步骤选择项配置完成后,选择作业调度选择项,在右侧导航栏中,选择新建按钮,如下图:
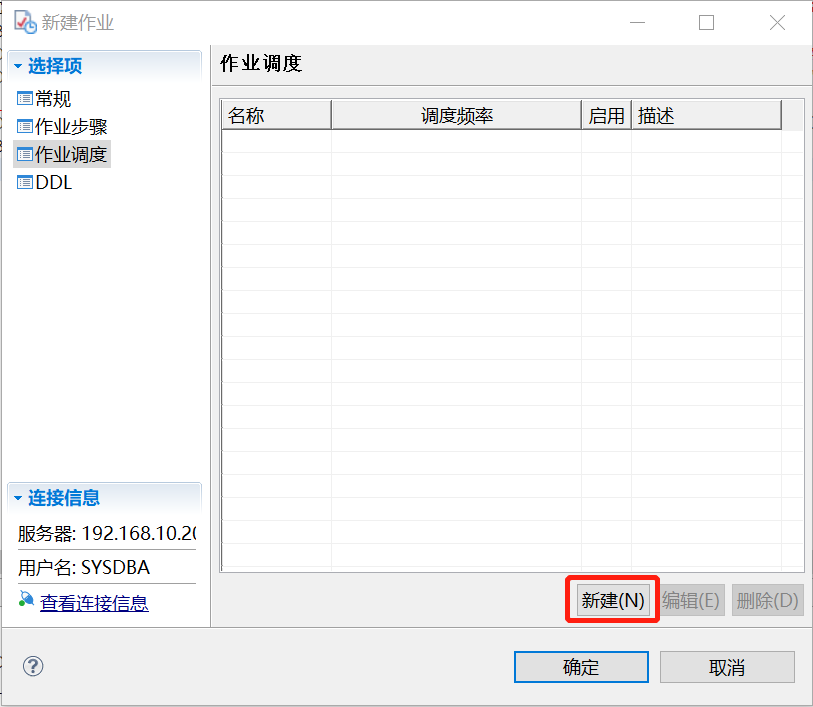
(6)作业调度规则。此配置项中,调度类型选择反复执行,因为是增量备份,所以建议要有基础的全量备份,并且增量备份的时间要避开全量备份的那一天,这里举例为每周的周一至周天(除周六 周六进行全量备份)进行增量备份,配置完成后点击确认即可。具体备份执行时间,可依据用户现场实际要求而定。如下图:
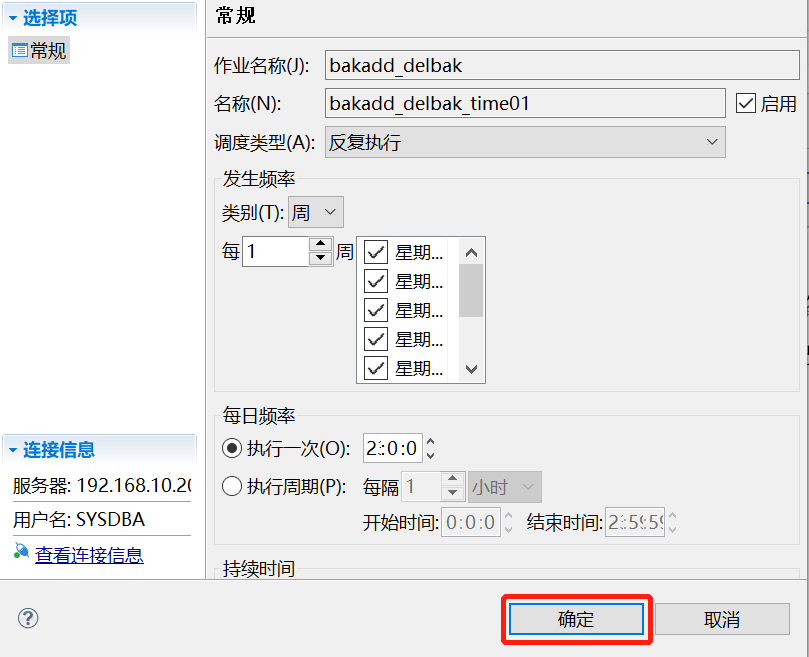
(7)配置完成。所有配置完成后,点击页面的确定按钮,即可完成配置。如下图:

2.4.3 常用备份参数
- 压缩
达梦支持对备份数据进行压缩,在执行备份时,可以指定不同的压缩级别,以获得不同的数据压缩比。默认情况下,备份是不进行压缩的。达梦共支持 9 个级别(1~9 级)的压缩处理,级别越高压缩比越高,但相应的压缩速度越慢、CPU 开销越大。考虑到备份效率及备份文件大小,建议压缩级别为 1。
- 并行
达梦数据库可以进行并行备份,用户可以在备份步骤中指定并行数。考虑到备份过程中对于数据库的压力以及有可能和业务同时进行,达梦共支持 10 个级别(0~9 级),建议选择 2,可在尽可能在不影响业务的情况下,尽快完成数据备份。