一、前言
1.1 概念
实例状态监控是指对数据库实例资源活动状态进行监控,一旦发现相关风险或资源不足时,应当及时采取相应的解决措施,消除隐患。达梦数据库的实例状态监控主要包含以下内容:
- 会话监控
- 线程监控
- SQL 监控
- 内存资源监控
- 表空间监控
- 集群状态监控
- 检查点监控
- 作业运行状态监控
- 日志监控与分析
1.2 工具与术语
实例状态监控中常用的监控工具有:
- 达梦企业管理器 DEM:数据库管理工具 ( DEM )提供一个通过 WEB 界面来监控、管理并维护 DM 数据库的集中式管理平台。
- 开源运维监控工具 Prometheus:是由 SoundCloud 开发的开源监控报警系统和时序列数据库 ( TSDB ),既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。
- 达梦 SQL 日志分析工具 DMLOG:通过分析数据库的 SQL 日志文件,直观地反映 SQL 执行情况。
实例状态监控中可能使用到的相关术语:
- 会话 ( session ) :是通信双方从开始通信到通信结束期间的一个上下文( Context )。当连接到数据库用户时就建立了会话。相当于处理 SQL 语句的一个平台,是服务器对数据库连接用户记录的一种手段。
- 实例:一般是由一组正在运行的 DM 后台进程/线程以及一个大型的共享内存组成。简单来说,实例就是操作 DM 数据库的一种手段,是用来访问数据库的内存结构以及后台进程的集合。
- 线程:通过一定的同步机制对数据结构进行并发访问和处理,以完成客户提交的各种任务。
- 表空间:在 DM 数据库中,表空间由一个或者多个数据文件组成。DM 数据库中的所有对象在逻辑上都存在表空间中,而物理上都存储在所属表空间的数据文件中。
1.3 适用范围
本文中所涉及内容适用于 DM7 及 DM8 版本数据库产品。
二、会话监控
会话监控主要监控数据库中的活动会话,总会话以及其占最大连接数( max_sessions )的百分比。可以通过以下两种方式查询会话数。
方法一:SQL 方法查询会话数
--查询当前所有会话数
select count(*) from v$sessions;
--查看当前数据库中活动会话
select count(*) from v$sessions where state='ACTIVE';
--查看当前空闲会话
select count(*) from v$sessions where state='IDLE';
--结束会话
sp_close_session(sess_id);
方法二:操作系统命令查询会话数
--基于端口为 5236 的会话数查询
lsof -i:5236|grep dmserver|wc -l
netstat -nat|awk '{print $4}'|grep 5236|wc -l
查看当前活动会话时,若当前活动会话连接数量太大,则说明数据库当前可能存在以下异常情况:
- 当前业务繁忙,业务量太大;
- 当前系统中存在慢 SQL;
- 应用的重连机制存在缺陷。
查看当前非活动会话时,若当前非活动会话连接数量太大,说明数据库可能存在以下情况:
- 系统当前处于会话空闲期;
- 连接池会话上线设置过高;
- 应用释放连接机制存在异常。
三、线程监控
线程监控主要监控数据库中活动线程信息和等待线程信息。
- 监控当前系统中活动线程的信息。
SELECT * FROM V$THREADS;
- 监控当前正在等待的线程信息。
SELECT * FROM V$LATCHES;
四、SQL 监控
SQL 监控主要包括慢 SQL 及阻塞、死锁、有事务未提交的表等。更多 sql 监控详见 SQL 监控查询语句汇总。
4.1 慢 SQL 及阻塞监控
通过以下语句检查当前数据库中包含的慢 SQL 及阻塞语句:
SELECT
DS.SESS_ID "被阻塞的会话ID",
DS.SQL_TEXT "被阻塞的SQL",
DS.TRX_ID "被阻塞的事务ID",
(CASE L.LTYPE WHEN 'OBJECT' THEN '对象锁' WHEN 'TID' THEN '事务锁' END CASE ) "被阻塞的锁类型",
DS.CREATE_TIME "开始阻塞时间",
SS.SESS_ID "占用锁的会话ID",
SS.SQL_TEXT "占用锁的SQL",
SS.CLNT_IP "占用锁的IP",
L.TID "占用锁的事务ID"
FROM
V$LOCK L
LEFT JOIN V$SESSIONS DS
ON
DS.TRX_ID = L.TRX_ID
LEFT JOIN V$SESSIONS SS
ON
SS.TRX_ID = L.TID
WHERE
L.BLOCKED = 1
上述 SQL 语句中,“占用锁的会话 ID ”表示该会话占用这个对象的锁,且事务一直没有提交。导致“被阻塞的会话 ID ”无法对该对象上锁。可以参考以下解决方式:
方式一:杀掉占用锁的会话,释放锁。
SP_CLOSE_SESSION ( 占用锁的会话 ID );
方式二:杀掉被阻塞的会话。
SP_CLOSE_SESSION ( 被阻塞的会话 ID );
4.2 查询死锁历史事务信息
select
dh.trx_id ,
sh.sess_id,
wm_concat(top_sql_text)
from
V$DEADLOCK_HISTORY dh,
V$SQL_HISTORY sh
where
dh.trx_id =sh.trx_id
and dh.sess_id=sh.sess_id
group by
dh.trx_id, sh.sess_id;
4.3 有事务未提交的表查询
SELECT b.object_name, c.sess_id, a.*
FROM v$lock a, dba_objects b, v$sessions c
WHERE a.table_id = b.object_id AND ltype = 'OBJECT' AND a.trx_id = c.trx_id;
五、内存资源监控
内存资源监控主要监控 DM 数据库所占内存情况。DM 数据库使用的内存大致等于 BUFFER + MPOOL,在进行内存资源监控时,一般需关注 v$bufferpool 和 v$mem_pool 相关信息。
5.1 查询内存总量
select
(select sum(n_pages) * page()/1024/1024 from v$bufferpool)||'MB' as BUFFER_SIZE,
(select sum(total_size)/1024/1024 from v$mem_pool)||'MB' as mem_pool,
(select sum(n_pages) * page()/1024/1024 from v$bufferpool)+(select sum(total_size)/1024/1024 from v$mem_pool)||'MB' as TOTAL_SIZE
from dual;
以上查询结果中,字段含义如下:
- BUFFER_SIZE:系统缓冲区大小,以 M 为单位。推荐值:系统缓冲区大小为可用物理内存的 60%~80%。有效值范围(8~1048576)。
- MEM_POOL:共享内存池大小,以 M 为单位。共享内存池是由 DM 管理的内存。有效值范围:32 位平台为(642000),64 位平台为(6467108864)。
- TOTAL_SIZE:BUFFER_SIZE 和 MEM_POOL 的总和。
内存不足常见原因有如下两种情况:
- memory_target 设置为 0,导致会话使用的内存未释放,可以考虑修改 memory_target 参数。
- 会话执行的 sql 消耗大量的内存,可以根据以下 sql 找到最占用内存的 sql,再进行 sql 优化。
SELECT "SESSID", MAX_MEM_USED||'KB',SQL_TXT FROM V$SQL_STAT
order by MAX_MEM_USED DESC;
5.2 查看所有内存池的使用信息
内存池使用信息可通过以下两种方式查询:
方法一:查询内存池使用信息的 sql 语句如下所示,单位是 M。
select
name, --内存池名称
is_shared, --是否是共享的
is_overflow, --是否用到了备份池
org_size/1024.0/1024.0, --内存池初始大小
TOTAL_size/1024.0/1024.0, --内存池总大小(包括扩展的)
RESERVED_SIZE/1024.0/1024.0, --当前已分配大小(包括扩展的)
DATA_SIZE/1024.0/1024.0, --实际有效字节
EXTEND_SIZE, --每次扩展多少
TARGET_SIZE, --目标大小
N_EXTEND_NORMAL , --TARGET范围内累计扩展次数
N_EXTEND_EXCLUSIVE --超过TARGET累计扩展次数
from v$mem_pool
order by TOTAL_size desc;
查询结果可以参考如下:
(1)N_EXTEND_EXCLUSIVE 如果长期大于 0,说明长期从池外扩展,可能存在内存泄露,需要重点关注。
(2)若使用到备份池,则需要保持高度关注。
(3)内存池创建的线程号 creator 可以与 session 的 thrd_id 关联,查看对应的某个会话的内存使用情况,查看方法可以参考 单个会话内存使用情况。
(4)若 RESERVED_SIZE 比 org_size 小,说明内存池非常空闲,可以减小对应的初始内存,避免浪费。
(5)若 TOTAL_size 比 TARGET_SIZE 大,说明内存池不够,经常向池外申请,需要把对应参数调大。
方法二:可以通过 v$sysstat 视图监控内存的使用情况。
select name ,stat_val/1024.0/1024.0 from v$sysstat where CLASSID=11 ;
以上查询结果中,字段含义如下:
- memory pool size in bytes:内存池总的大小。
- memory used bytes:内存池使用的内存大小。
- memory used bytes from os:内存池从操作系统分配的大小。
5.3 单个会话内存使用情况
SELECT
A.CREATOR ,
B.SQL_TEXT ,
SUM(A.TOTAL_SIZE)/1024.0/1024.0 TOTAL_M, --当前总量(包括扩展)
SUM(A.DATA_SIZE) /1024.0/1024.0 DATA_SIZE_M --实际使用量
FROM
V$MEM_POOL A,
V$SESSIONS B
WHERE
A.CREATOR = B.THRD_ID
GROUP BY
A.CREATOR,
B.SQL_TEXT
ORDER BY
TOTAL_M DESC;
5.4 内存增长过快分析
(1)通过查询内存的使用,确定增长范围。
select
(select sum(n_pages) * page()/1024/1024 from v$bufferpool)||'MB' as BUFFER_SIZE,
(select sum(total_size)/1024/1024 from v$mem_pool)||'MB' as mem_pool,
(select sum(n_pages) * page()/1024/1024 from v$bufferpool)+(select sum(total_size)/1024/1024 from v$mem_pool)||'MB' as TOTAL_SIZE
from dual;
在启动前查询上述语句,记录初始值。然后在内存增长的时候,再查询上述语句。
(2)打开 MEMORY_LEAK_CHECK。
alter system set 'MEMORY_LEAK_CHECK'=1 ;
(3)查询 V$MEM_REGINFO 视图,关注 REFNUM 字段,若该字段值很大,则说明存在内存堆积的情况。
select * from V$MEM_REGINFO ORDER BY REFNUM DESC;
以上查询结果中,字段含义如下:
- fname 指定该内存池的内存来源文件。
- lineno 指定相关内容在文件中的行数。
5.5 监控 BUFFER 状态
select
name, --缓冲区名称
n_pages, --页数
free, --空闲页数目
N_DISCARD64 --淘汰的页数
from v$bufferpool
查询结果可以参考如下:
(1)如果 free 较大,说明该缓冲区空闲,可以适当的调整降低 buffer 缓冲区参数值。
(2)如果 free 项为 0,或者 N_DISCARD64 非零,表示该缓冲区经常淘汰,说明对应的缓冲区参数太小,导致频繁淘汰,需要调整对应的缓冲区的参数。
5.6 查询缓存信息
(1)查询缓存池信息。
SELECT * FROM V$SCP_CACHE;
包括计划、SQL 语句和结果集缓存的信息,可以查看缓存项的状态和时间戳,如下图所示:
(2)查询缓冲区中缓冲项的相关信息。
SELECT * FROM V$CACHEITEM;
(3)记录缓存的 SQL 和执行计划。
在 ini 参数 USE_PLN_POOL 不为 0,且没有使用结果缓存集的情况下,V$CACHEITEM 用于记录缓存的 SQL 和执行计划。
SELECT SUM(ITEM_SIZE)/1024/1024 缓存池大小_M FROM V$CACHEITEM;
由于 SQL 缓存池可以最大动态的增长至 CACHE_POOL_SIZE 的三倍大小,所以如果 CACHE_POOL_SiZE 设置不合理,可能会造成使用较多的虚拟内存,增加较大的系统负担。
5.7 查询缓冲区命中率
数据缓冲区是 DMSERVER 在将数据页写入磁盘之前以及从磁盘上读取数据页之后,数据页所存储的地方。
数据缓冲区设定得太小,会导致缓冲页命中率低,磁盘 IO 频繁;将其设定得太大,又会导致操作系统内存本身不够用。
select
name 缓冲池名称,
sum(page_size)*sf_get_page_size 缓冲池大小_G,
sum(rat_hit) /count(*) 命中率
from
v$bufferpool
group by name;
六、表空间监控
表空间监控主要监控数据库表空间使用率。需要注意以下内容:
- 表空间监控主要关注业务表空间、ROLL 表空间和 TEMP 表空间;
- 不同业务数据使用独立表空间,建议不要使用 MAIN 表空间;
- 可以根据实际业务需求对表空间设置阈值上限。
6.1 查看表空间的使用情况
SELECT Upper(F.TABLESPACE_NAME) "表空间名",
D.TOT_GROOTTE_MB "表空间大小(M)",
D.TOT_GROOTTE_MB - F.TOTAL_BYTES "已使用空间(M)",
To_char(Round(( D.TOT_GROOTTE_MB - F.TOTAL_BYTES ) / D.TOT_GROOTTE_MB * 100, 2), '990.99')
|| '%' "使用比",
F.TOTAL_BYTES "空闲空间(M)",
F.MAX_BYTES "最大块(M)"
FROM (SELECT TABLESPACE_NAME,
Round(Sum(BYTES) / ( 1024 * 1024 ), 2) TOTAL_BYTES,
Round(Max(BYTES) / ( 1024 * 1024 ), 2) MAX_BYTES
FROM SYS.DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) F,
(SELECT DD.TABLESPACE_NAME,
Round(Sum(DD.BYTES) / ( 1024 * 1024 ), 2) TOT_GROOTTE_MB
FROM SYS.DBA_DATA_FILES DD
GROUP BY DD.TABLESPACE_NAME) D
WHERE D.TABLESPACE_NAME = F.TABLESPACE_NAME
ORDER BY 2 desc;
临时表空间经常过大,说明内存设置过小或存在大量中间结果集存放,需要视情况进行优化。
注意为了不影响磁盘空间的使用,可以通过 ini 参数 TEMP_SIZE 配置大小、TEMP_SPACE_LIMIT 设置上限、存储过程 SP_TRUNC_TS_FILE 来收缩 TEMP 表空间文件(生产环境请谨慎使用)。
6.2 查看表空间与数据文件对应关系
SELECT TS.NAME, DF.PATH FROM V$TABLESPACE AS TS, V$DATAFILE AS DF WHERE TS.ID = DF.GROUP_ID;
6.3 UNDO 与 REDO 信息查询
监控数据库的 REDO 以及 UNDO 日志、日志是否正常切换以及 UNDO 日志的空间是否增长过快的情形,同时监控数据库中待 Purge 的事务数是否在不停的增长。
- UNDO:用于取消或回滚事务。
select * from dba_data_files where tablespace_name='ROLL';
当对数据进行修改时,数据库会产生 undo 信息,若数据出现丢失,可采用 rollback 请求回滚,可以利用这些 undo 信息将数据回滚到修改前的状态。但是生产环境建议根据数据分区所在磁盘空间和业务系统来限制 ROLL 文件的大小上限,防止发生大操作导致 ROLL 文件被撑大直至磁盘写满导致发生宕机风险,具体设置 ROLL 文件大小上限的方法如下,例如将回滚文件大小上限设置为 500GB。
alter tablespace "ROLL" datafile 'ROLL.DBF' autoextend on maxsize 512000;
ROLLBACK 的时间和 TRANSACTION 的大小有直接关系。因为 ROLLBACK 必须物理上恢复数据。回滚段存在于 undo 表空间中,在数据库中可以存在多个 undo 表空间,但同一时刻只能使用一个 undo 表空间。
UNDO 日志空间是否增长过快,查看已使用 roll 表空间的大小,命令如下:
select
a.tablespace_name space_name ,
total /1024/1024/1024 "总大小(G)" ,
free /1024/1024/1024 "可使用(G)" ,
(total -free) /1024/1024/1024 "已使用(G)",
round((total -free)/total, 4)*100 "使用率"
from
(
select
tablespace_name,
sum(bytes) free
from
dba_free_space
group by
tablespace_name
)
a,
(
select
tablespace_name,
sum(bytes) total
from
dba_data_files
group by
tablespace_name
)
b
where
a.tablespace_name = b.tablespace_name
ORDER BY
"使用率" DESC;
查看待 Purge 的事务数( OBJ_NUM )是否在不停的增长,命令如下:
select * from v$purge;
- REDO:重做日志包含所有数据产生的历史改变记录,是在线或归档重做日志文件中记录的信息。
SELECT * from v$rlogfile;
一旦因为掉电或其他意外丢失数据,可以利用这些 redo 来重做事务。产生 REDO 越多,意味着该系统业务越繁忙。REDO 日志是否正常切换可通过查看归档文件是否在持续生成来检查,命令如下:
select * from V$ARCHIVED_LOG ORDER BY FIRST_CHANGE# DESC;
6.4 TEMP 临时表空间
当数据库查询的临时结果集过大,缓存已经不够用时,临时结果集就可以保存在 TEMP.DBF 文件中,供后续使用。系统中用户创建的临时表也存储在临时文件中。
数据库管理员在运维过程中需要监控 TEMP.DBF 的文件大小,防止临时表空间文件过大导致数据文件所在磁盘空间被撑满引发宕机风险。当数据库服务重启后,TEMP.DBF 会自动恢复到初始大小。
七、集群状态监控
集群状态监控主要监控数据库集群状态是否正常。
以 DSC 为例,数据库状态监控实现方法:调用数据库集群状态监控工具 dmcssm 工具,检查整体集群 CSS、ASM、Dmserver 进程状态是否是 OK 状态。命令如下:
cd $DM_HOME/bin
./dmcssm dmcssm.ini
DSC 监控主要关注各控制节点的实例系统状态( inst_status )、实例的集群状态( vtd_status )、实例在集群内是否正常( is_ok )和实例是否活动( active )。正常情况下,inst_status、vtd_status、is_ok 和 active 的值如上图所示,若存在异常项,需及时排查相关问题。
八、检查点监控
定时对数据库的检查点进行监控,当检查点未能正常刷新时,需要人工干预,排查处理。
查看检查点相关视图,LAST_BEGIN_TIME 与 LAST_END_TIME 字段时间能持续更新,代表检查点能正常刷新,命令如下:
select * from V$CKPT;
九、作业运行状态监控
9.1 DM 作业功能
本章节主要介绍 DM 数据库的作业运行操作,以及作业执行状态监控展示。DM 的作业系统为用户提供了创建作业,并对作业进行调度执行以完成相应管理任务的功能。可以让这些重复的数据库任务自动完成,实现日常工作自动化。
用户通过作业可以实现对数据库的操作,并将作业执行结果以通知的形式反馈到操作员。通过为作业创建灵活的调度方案可以满足在不同时刻运行作业的要求。
9.2 创建定时全备作业
9.2.1 打开归档
详细方法可以参考开启本地归档。需要注意的是, dm.ini 的默认目录为 /opt/dmdbms/data/DAMENG,实际目录以项目实际情况为准。
9.2.2 创建作业
创建代理环境,使用图形化界面创建作业的时候 DM 数据库会创建一个 sysjob 的模式,选择代理右键-> 创建代理环境,在作业处右键选择【新建作业】,如下图所示:

例如我们需要每周日对 DAMENG 数据库进行全库备份,如下图所示:
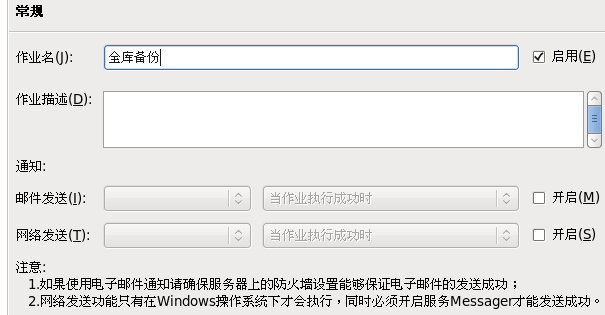
9.2.3 编辑作业步骤
选择【添加】,填写作业步骤相关信息,如下图所示:

9.2.4 编辑作业调度
选择【新建作业调度】,填写相关信息,如下图所示:
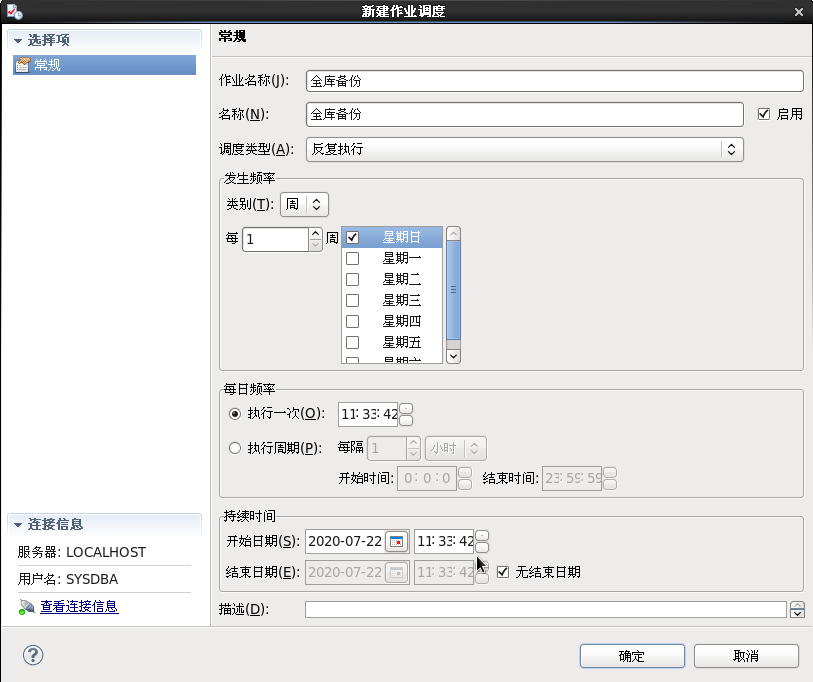
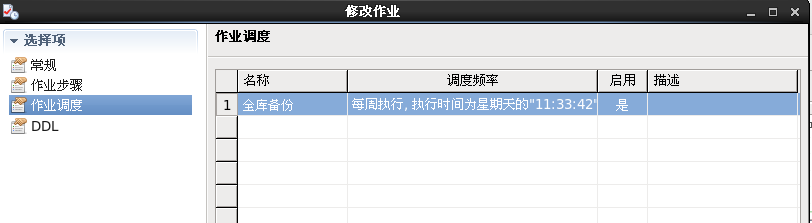
9.2.5 查看作业状态
在创建的作业右键【查看作业历史信息】。错误类型、错误码和错误信息下没有显示内容则表示创建成功,若有失败作业,则错误信息下会记录详细信息。
9.3 定时删除全备备份
9.3.1 新建作业
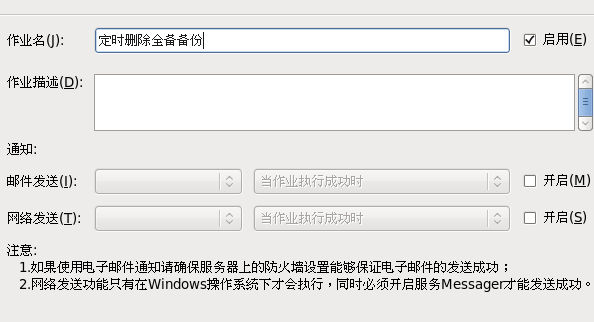 1. 设置作业步骤
1. 设置作业步骤
只保留 7 天的备份,具体请根据实际情况设置,如下图所示:
2. 设置作业调度
例如每周末凌晨一点执行删除全备备份,如下图所示:

3. 查看作业状态
如下图所示,表示无报错信息,记录有开始时间和结束时间,作业执行成功。

9.3.2 命令行查看作业运行状态
除了通过图形化界面查看作业执行状态之外,我们还可以使用命令行查看。执行结果可以看到作业运行的状态和具体时间,执行用户和执行步骤等是否符合要求。
select * from sysjob.sysjobs;
select * from sysjob.sysjobhistories;
select * from sysjob.sysjobschedules;
select * from sysjob.sysjobsteps;
十、日志监控与分析
数据库日志监控和分析作为数据库故障诊断的重要手段之一。
本节主要对达梦数据库的实例运行日志,SQL 日志,dmap 辅助进程日志,备份日志等日志文件进行分析讲解,了解数据库日志常见的异常信息,同时介绍达梦常见的接口日志开启方法。
10.1 日志中信息记录分类
达梦数据库日志主要有 INFO、WARNING、ERROR 和 FATAL 四类信息。
- INFO(正常):用于打印程序应该出现的正常状态信息, 便于追踪定位;
- WARNING(告警):表明系统出现轻微的不合理,一般不影响运行和使用;
- ERROR(错误):表明出现了系统错误和异常,无法正常完成目标操作;
- FATAL(致命):表明发生了严重的错误,会导致数据库宕机,服务停止。
一般在进行数据库日志监控时,主要关注以下内容:
- WARNING、ERROR 和 FATAL 类信息监控。
- INFO 类信息中涉及实例重启的信息。
在 Linux 环境中查看相关信息,可参考如下命令:数据库日志监控实现方法:通过 cat 命令进行数据库日志定期检查,过滤日志当中包含 ERROR、WARNING 信息的记录,并输出信息至前台监控显示界面,命令如下:
cd $DM_HOME
cd log
ls -ltr *.log
##检查日志中是否有错误信息
cat xxxx.log |grep ‘\[ERROR’
##检查日志中是否有警告信息
cat xxxx.log |grep ‘\[WARNING’
##检查数据库是否重启过
cat xxxx.log |grep ‘SYSTEM READY
10.2 实例运行日志
实例运行日志记录了数据库服务启动,刷检查点,写归档、刷盘等一系列实例的运行过程,按月生成,一般默认命名为 “dm_实例名称_月份.log”。
针对该日志的分析,可了解以上过程的运行状态,通过检查点刷盘,也可以分析业务的繁忙程度,作为调整内存、检查点参数的依据。
主要日志信息解读:
更多实例日志监控内容可参考:实例日志常见异常信息汇总。
通过 grep 筛选检查具有 ERROR 或者 FATAL 关键字的日志,并将结果输出至文件中:
##查看错误日志定位相关数据库报错
cat dm_DMSERVER_202203.log | grep "ERROR" >1.log
10.3 SQL 日志
SQL 日志开启步骤请参照 配置数据库 SQLLOG 日志 章节。
注意(1)如果需要开启 SQL 日志,则必须配置日志切换模式 SWITCH_MODE 和 FILE_NUM,防止日志无限增长导致磁盘撑爆;
(2)同步日志会影响系统效率,生产环境建议设置为异步日志;
(3)在设置 SQL 过滤规则 SQL_TRACE_MASK 时,建议只设置需要记录的 SQL 掩码,生产环境不要直接设成 1。
SQL 日志记录了数据库服务器从客户端接收到的 SQL 请求语句,包括 SQL 语句对应的时间戳、用户名、事务号、SQL 文本和执行时间等信息。如下图所示:
我们将日志中如下记录进行举例说明:
2022-03-23 15:04:06.926 (EP[0] sess:0000000059587140 thrd:6956 user:SYSDBA trxid:2574604 stmt:00000000595AB938 appname:manager.exe ip:127.0.0.1) [SEL] select COMMENT$ from SYS.SYSCOLUMNCOMMENTS where SCHNAME='SYSDBA' and TVNAME='T11' and COLNAME='STRIP' EXECTIME: 0(ms).
该条信息解读如下:
- 2022-03-23 15:04:06.926 表示该条 SQL 被记录下来的时间;
- sess:0000000059587140 表示该 SQL 对应的 session_id 为 0000000059587140;
- thrd:6956 表示该 SQL 对应的线程 id 为 6956;
- user:SYSDBA 表示执行该 SQL 时所使用的的数据库登录用户为 SYSDBA;
- trxid:2574604 表示该 SQL 对应事务的 trx_id 为 2574604;
- stmt:00000000595AB938 表示该 SQL 对应的会话句柄号为 00000000595AB938;
- appname:manager.exe 表示发出该 SQL 请求对应的应用名称,如果为 NULL 表示应用代码中没有填充应用名称值;
- ip:127.0.0.1 表示发出该 SQL 请求的客户端机器的 IP 地址;
- [SEL] 表示该 SQL 所属类型,SEL 表示该 SQL 为查询语句;
- select COMMENT$ from SYS.SYSCOLUMNCOMMENTS where SCHNAME='SYSDBA' and TVNAME='T11' and COLNAME='STRIP' 表示该 SQL 对应的 SQL 语句完整文本信息;
- EXECTIME: 0(ms)表示该 SQL 的执行耗时;
此外,达梦提供达梦 SQL 日志分析工具 DMLOG。该工具通过分析数据库的 SQL 日志文件,直观地反映 SQL 执行情况。
10.4 dmap 辅助进程日志
damp 辅助日志是记录 DMAP 进程的运行情况的日志,dmap 辅助日志的位置和实例运行日志的位置相同,命名方式为 “dm_DMAP_日期.log”。
主要日志信息解读:
10.5 备份日志
备份日志,记录的是数据库备份情况的日志,主要用于记录数据库备份的过程信息,判断备份是否完成的日志,日志存放的位置和实例运行日志相同,命名格式为 “dm_BAKES_日期.log”。
主要日志信息解读:
可以通过和数据库运行日志一样的过滤关键词的方式来检查是否有报错信息。
10.6 接口日志
本节主要介绍 DPI/DCI 日志、ODBC 日志和 JDBC 日志的开启方法。
10.6.1 开启 DPI/DCI 日志
在 dm_svc.conf 中开启 DPI/DCI 接口日志,设置以下参数:
##打开 DCI 接口日志
DCI_TRACE=(1)
##打开 DPI 接口日志
DPI_TRACE=(1)
在程序工程目录下会生成 dmdci_trace.log、dpi_trace.log 日志。
DPI/DCI 日志格式类似,记录了调用 DPI/DCI 接口中各函数的名称,参数类型和参数值,返回值,以及调用时间等信息。
10.6.2 开启 ODBC 日志
在 odbcinst.ini 中开启 odbc 日志,主要增加如下参数:
[ODBC]
Trace=YES
TraceFile=/root/odbc.log
odbc 日志开启后的相关信息如图:
10.6.3 开启 JDBC 日志
在连接串中开启 jdbc 日志,例如:
String urlString = “jdbc:dm//192.168.239.128:5236?loglevel=all&logDir=/opt/log”;
其中:
- logLevel 记录 jdbc 日志级别,可选 off, error, warn, sql, info, all,默认为 off;
- logDir 表示日志目录,默认为 jvm 当前工作目录。
十一、参考
若以上内容无法解决您的问题,可以在 达梦技术社区 提问交流。