本章节主要介绍达梦数据库故障处理常见问题,为用户提供故障处理常见问题的分析和解决思路。除此之外,用户还可前往达梦技术社区参与更多问题讨论。
目录
- 数据库表数据误删,如何恢复
- 误删除 undo/redo 日志怎么办
- 如果有备份文件
- 如果没有备份文件
- 表空间的数据文件被删除了,想删除表空间,如何解决
- 超出全局 hash join 空间
- 数据库表被 truncate 后能否找回数据
- DM 数据库异常宕机原因排查
- 其他类型被强制转成科学计数法的格式
- 打开管理工具报错:Locking is not possible in the directory
- 控制文件 dm.ctl 被误删,启动报错:[code:-803]
- 数据文件 MAIN.dbf 或者自创表空间被误删
- 数据文件 ROLL.dbf,SYSTEM.DBF 被删后无法启动报错
- 误删除 TEMP.DBF 怎么处理
- undo 日志损坏
- redo 日志损坏,报错[-723][-717]
- 数据库页损坏
- 磁盘问题导致故障
- 磁盘空间不足导致故障:日志报错 out of space
- 使用 Manager 管理工具的时候,出现卡顿的情况
- 数据库卸载后,只剩数据 data 文件夹里面文件,如何修复
- 运行 dbms_repository_snapshot.create_snapshot() 生产快照的时候会卡住
- 在更新 /updte 数据的时候突然卡住,没有任何报错
- disql 执行语句后无法退出,Ctrl+C 也没用
- SESSIONS 视图中获取的 LAST_SEND_TIME 和 LAST_RECV_TIME 不准确
- 环境变量或者 dm_svc.conf 配置不合理导致 disql 登录不正常
- 管理工具 “编辑数据” 报错 “结果集不可更新”
- kettel 抽取 number 整数类型变为小数、插入 number 类型小数保留精度不对
- 数据库服务器通过管理工具连接本地数据库时,报错-703 服务器模式不匹配
- 达梦 manager 客户端登录提示网络通信异常
- sqlserver 创建 dblink 失败
- 启动数据库后应用一连接就 core 掉
- 使用 disql 工具操作数据库时提示:连接丢失
- 启动数据库报错:System information is invalid,please check ../DAMENG/SYSTEM.DBF or its mirror file
- vpn 环境下管理工具连接数据库报错:网络通信异常
- 数据库报错 IO timeout overtime 3 of IO_TIMEOUT
- DM6 数据库出现宕机现象
- 达梦 DSC 集群,其中一个节点宕机,另一节点正常提供服务
- linux 下数据库运行过程中误删除某个表空间数据文件,如何快速进行恢复
- 数据库服务无法启动,执行服务启动命令后提示:os_file_flush error desc:Read-only file system
- 数据库服务突然中断
- 服务无法启动,前台启动报错:非法指令(核心已转储)
- 启动 dmwatcher 报错:fail to read ini file
- 数据库版本升级后,DmAPService 服务启动失败报错
- isql 或管理工具登录 DM6 数据库失败
- 管理工具返回结果集太大,中断加载,显示不全
- 数据库 roll.dbf 损坏需要替换
- perf top 异常热点 lock_release_check_savepoints
- DMMPP 主备集群登录后查询表报错:MPP 站点信息不匹配
- 使用低版本的 bin 目录启动集群失败
- Windows 平台 Manager 调试带绑定变量参数语句时,SRVLOG 中始终缺少[SEL]标签执行信息
- DM6 数据库分离后的数据库附加时提示“数据库未正常分离”
- 达梦 8 在程序中报错:“执行环境堆栈空间不足 -7059”
- 数据库版本升级时报错:Upgrade is not allowed, please startup with original dmserver
- uos 系统中 core 文件不完整或无法查找到位置
- 实例日志常见异常信息汇总
- DSC 环境下某节点服务重启后数据库服务无法 open
- 数据库运行日志报错:pwrite error
- 达梦数据库启动报错:结构需要清理
- 数据库日志报错:"[FATAL]: os_io_low read error!"
正文
数据库表数据误删,如何恢复
首先确定是什么时候做的操作?数据库是否有备份?有备份的情况下数据可以恢复到任意时间点。如果没有备份一般是无法恢复的。
数据库系统必须保证即使发生故障,也可以保障数据的完整性和一致性。支持故障恢复的技术主要是日志,日志以一种安全的方式记录数据库系统变更的历史信息,一旦系统出现故障,数据库系统可以根据日志将系统恢复至故障发生前的某个时刻。数据库系统的日志分为两种类型:
- REDO 日志,在数据被修改后记录它的新值。
- UNDO 日志,在数据被修改前记录它的旧值。
另外,当服务器处于归档模式时,如果数据库发生故障,通过备份文件和归档日志可以恢复到指定时间点。具体方法可以参考《DM 备份与还原》手册(手册位于数据库安装路径 /dmdbms/doc/special 文件夹下)。
误删除 undo/redo 日志怎么办
分以下两种情况:
如果有备份文件
如果有备份文件,可以重新初始化一个新的数据库(初始化参数要和原库一样,比如页大小、大小写敏感、字符集等,这些可以在 DM 数据库安装路径,../data/DAMENG 目录下以 dminit+日期时间.log 命名的文件中查询),然后将备份文件和归档日志文件拷贝到新的环境,然后再进行备份 + 归档的还原操作。
如果没有备份文件
如果没有备份,可以通过修改永久魔术值的方式来恢复,但是这种情况下有可能丢失数据。方法如下:
- 重新初始化一个新的数据库,(初始化参数要和原库一样,比如页大小、大小写敏感、字符集等,这些可以在 DM 数据库安装路径,../data/DAMENG 目录下以
dminit+日期时间.log命名的文件中查询)。 - 将步骤 (1) 中重新初始化的数据库中
DAMENG01.log、DAMENG02.log文件拷贝到当前丢失 REDO 日志的库目录下。 - 使用 dmmdf 工具获取 SYSTEM.DBF 的 db_magic,并记录下来。
[root@dmyanshi2 bin]# ./dmmdf /data/DAMENG/SYSTEM.DBF 1
1 db_magic=1394176795
2 next_trxid=34742179
Please input which parameter you want to change(1-2), q to quit: q
- 使用 dmmdf 工具设置 DAMENG01.log 文件的 db_magic,设置为步骤 (3) 中记录的值。
[root@dmyanshi2 bin]# ./dmmdf /data/DAMENG/DAMENG01.log 2
1 sig = DMRLOG
2 ver = 7001
3 chksum = 0
4 dbversion = 0x70008
5 sta = 1
6 n_magic = 7
7 db_magic = 1411700695
8 clsn_fil = 0
9 cur_fil_id = 0
10 next_seq = 0
11 arch_seq = 0
12 len = 67108864
13 free = 4096
14 clsn = 0
15 clsn_off = 4096
16 arch_lsn = 0
You can only reset sta(5) or db_magic (7) or clsn (14).
Please input the num which one you want to change, q to quit: 7
Input the new value: 1394176795
1 sig = DMRLOG
2 ver = 7001
3 chksum = 0
4 dbversion = 0x70008
5 sta = 1
6 n_magic = 7
7 db_magic = 1394176795
8 clsn_fil = 0
9 cur_fil_id = 0
10 next_seq = 0
11 arch_seq = 0
12 len = 67108864
13 free = 4096
14 clsn = 0
15 clsn_off = 4096
16 arch_lsn = 0
Do you want to quit and save the change to file (y/n): y
Save to file success!
- 重新启动数据库即可。
表空间的数据文件被删除了,想删除表空间,如何解决
数据文件被删除,那这部分的数据是丢失的,数据库无法正常启动。处理方式是将控制文件转成文本文件,在控制文件中把对应表空间信息删除,再把文本文件转成控制文件,删除对应的数据文件,最后启动数据库即可。
具体操作如下:
- 将控制文件转换成文本文件
切换到数据安装路径如:/opt/dmdbms/bin/bin 执行 ./dmctlcvt help 可以查看到 dmctlcvt 工具的具体情况,如下图所示:
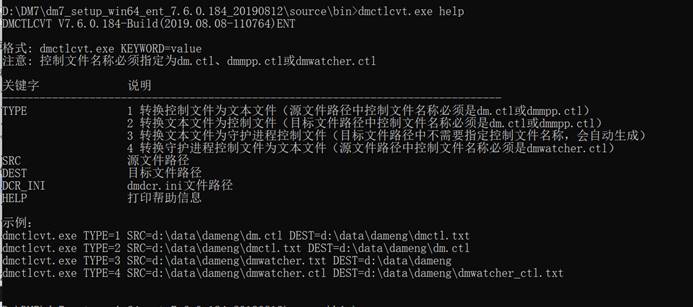
将 dm.ctl 文件转换成 dm.txt 文件,如下所示:
./dmctlcvt TYPE=1 SRC=/opt/dmnew/data/DAMENG/dm.ctl DEST=/opt/dmnew/data/DAMENG/dmctl.txt
- 删除掉 dmctl.txt 中被删除的数据库文件指定的路径。
- 将 dmctl.txt 生成 .dm.ctl 文件执行以下操作:
./dmctlcvt TYPE=2 SRC=/opt/dmnew/data/DAMENG/dmctl.txt DEST=/opt/dmnew/data/DAMENG/dm.ctl
超出全局 hash join 空间
首先我们讲一个故事:
你是上帝视角【1】,你给了小明 100 个棒槌【2】,这个时候来了 10 个叫做小花的人,小花可以去仓库里拿面粉做包子,但是做一次包子,需要借用小明的棒槌,假如每一个小花借用 10 个棒槌,如果同时来了 11 个小花,前 10 个小花都能借到棒槌,第 11 个小花去找小明借棒槌的时候,小明就告诉她:超出我的棒槌个数了,小花做包子失败。这句话翻译一下就是:数据库服务器报错超出全局 hash join 空间,应用请求在数据库执行失败。
但是,每一个小花根据自己的工作量,需要的棒槌个数并不一定必须是 10 个。也就是说,只有来的小花把棒槌都借用完,小明才会报错。但是小明也不是一直会报错,只要有任何一个小花,事情做完了,把借用的棒槌还回来,小明就又可以支撑新的小花。
上面这个故事,对应两个参数,如下图所示:

(图片来源:《DM 系统管理员手册》dm.ini 的介绍,手册位于数据库安装路径 /dmdbms/doc 文件夹下。)
- 小明一共有多少个棒槌,由
HJ_BUF_GLOBAL_SIZE设置,默认值是500。 - 一个小花最多可以借多少个棒槌,由
HJ_BUF_SIZE设置,默认值是50。
还有一个参数控制小明一次给小花多少个棒槌(比如小明要给小花 10 个棒槌,可以是一次给 1 个给 10 次,也可以是一次给 5 个给两次,这两种代价是不一样的)。一次给多少个,取决于以下参数:

(图片来源:《DM 系统管理员手册》dm.ini 的介绍,手册位于数据库安装路径 /dmdbms/doc 文件夹下。)
好了,我们回到问题,如果遇到小明报错了怎么办呢?
- 解决方法一
很多情况下,小花实际上只需要 1 个棒槌、一分钟内就能把事情做完,结果她却用了 10 个棒槌,一天都没有把事情做完,占用的这 10 个棒槌也一直没有还给小明。
换句话说就是要优化语句,消除掉这些不聪明的小花。遇到这个问题的优先核心方法是:找出不聪明的小花,让她变聪明——找到慢语句,进行优化。
- 解决方法二
扩大小明的棒槌个数,增大 HJ_BUF_GLOBAL_SIZE 数值。
或者是减小单个小花可以借用的棒槌上限,改小 HJ_BUF_SIZ 数值。(有人会问,小花要 10 个棒槌,现在你给她设置成 5 个,她还能干活么?答案是可以,哪怕限制小花最多只能借用 1 个棒槌,她也可以干活,只是工作时间会久一点。同样的,也不是一次性给的越多越好,如果本身只需要 5 个,一次性给了 10 个,也没有意义,工作效率并不会提高。)
如果确认系统中预期的 SQL 均是符合预期的计划,效率均没有问题,确实需要高并发,就必须提高 HJ_BUF_GLOBAL_SIZE/HJ_BUF_SIZ 的比值。可以通过调大 HJ_BUF_GLOBAL_SIZE 数值或适当调小 HJ_BUF_SIZ 数值来解决,也可以通过同时调大这两个参数值并保持较高的 HJ_BUF_GLOBAL_SIZE/HJ_BUF_SIZ 的比值来解决。
注意修改数据库参数的方式: Sp_set_para_value(1,’参数名字’,参数值);--当成 SQL 执行;对于动态参数,直接修改后,立即生效;如果是静态参数,如此修改,会报错:无法修改静态配置参数。 Sp_set_para_value(2,’参数名字’,参数值);--当成 SQL 执行;对于动态参数或者静态参数都可以用,修改后,需要重启数据库服务后才生效。
数据库表被 truncate 后能否找回数据
不能找回,truncate 删除表数据是不可逆的。只能看能否通过备份 + 归档日志的方式,将数据库还原到指定时间点的方式来找回该表的数据。
DM 数据库异常宕机原因排查
当数据库运行过程中发生异常宕机后,需要结合数据库运行日志联合分析原因。如果怀疑是因 SQL 导致的问题,可以通过 DM 提供的 dmrdc 命令行工具抓取到数据库宕机时服务器所有会话线程对应的 SQL 语句,使用格式为:./dmrdc sfile=src_file dfile=dest_file。
例如生成 core 文件为 core.19456,则应该执行:./dmrdc sfile=core.19456 dfile=core_19456.txt。
待分析完成后,我们可以根据生成的 core_19456.txt,查看到数据库服务器所有会话线程对应的 SQL 语句,其中 SQL 语句前面的中括号数值表示对应线程号,对应堆栈信息中的 LWP 号。我们可以使用 gdb 命令 配合 thread apply all bt 打印出所有线程堆栈,一般导致宕机的 SQL 在【Thread 1】上,我们可以在测试环境中尝试重现宕机现象,如果能够重现则可以将此问题交由达梦技术工程师来处理。

其他类型被强制转成科学计数法的格式
其他类型被强制转成科学计数法的格式 / 比如 100 变成 1E+2% / 10 变成 1。
【解决方法】:
可访问达梦云适配中心下载试用,下载最新版数据库,安装的时候选择驱动,将现在的出现问题的驱动换成最新的驱动。
打开管理工具报错:Locking is not possible in the directory
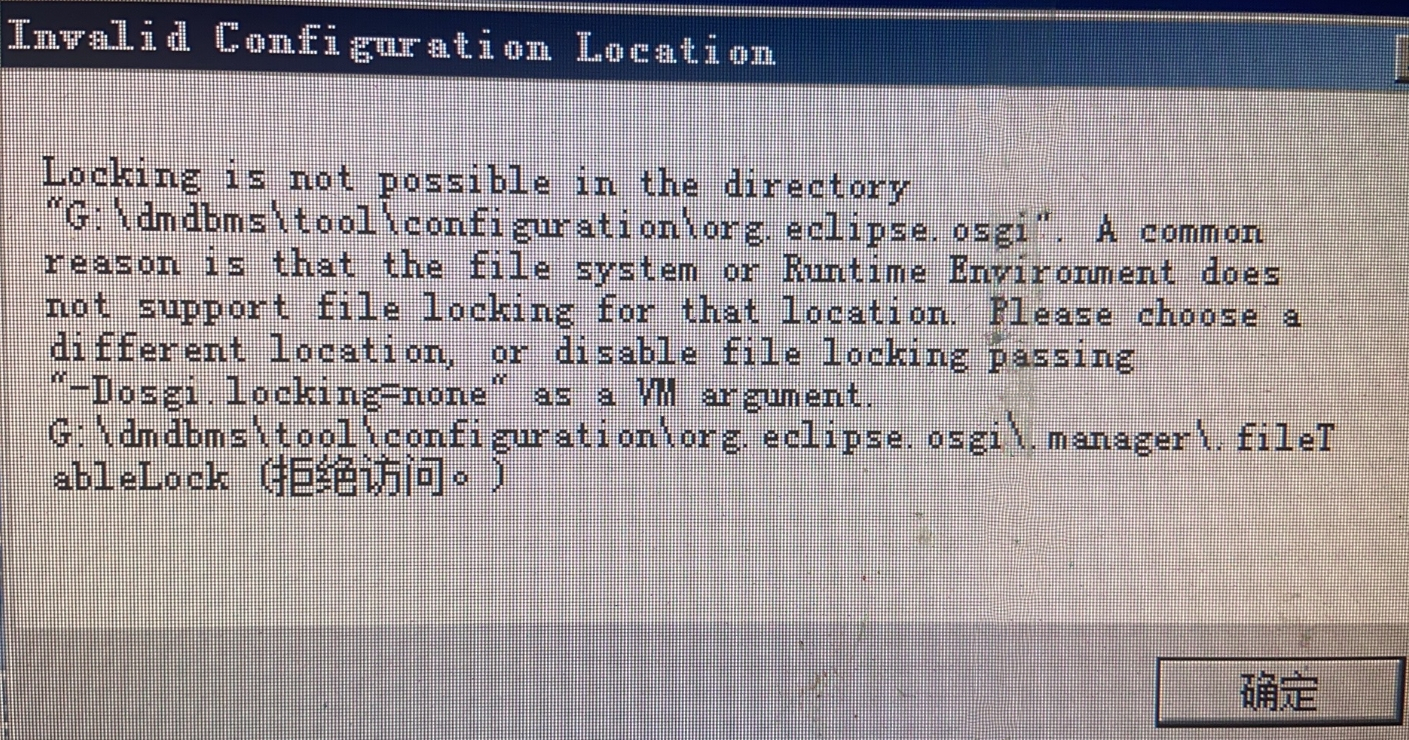
【问题解决】:
有如下两种解决方法:
方法 1:
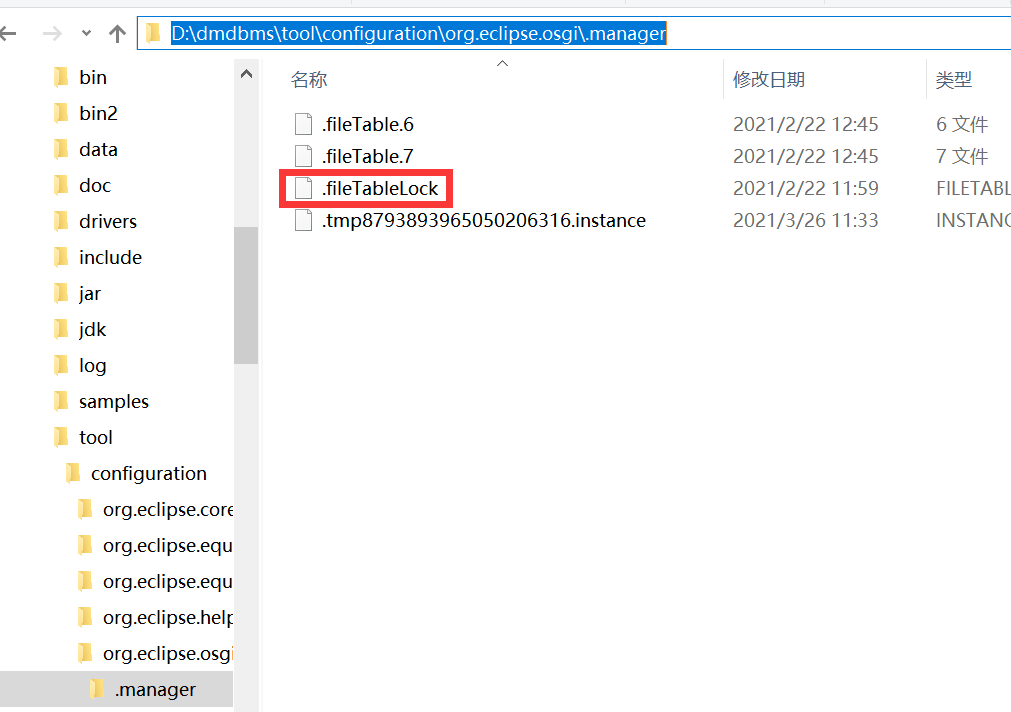
可以尝试删除安装目录下的 .fileTableLock 文件 ,再次打开达梦管理工具时会自动生成一个这个 lock 文件。
举例:如下是安装目录,找到 tool 目录下对应的 fileTableLock 文件,删除后再启动管理工具。
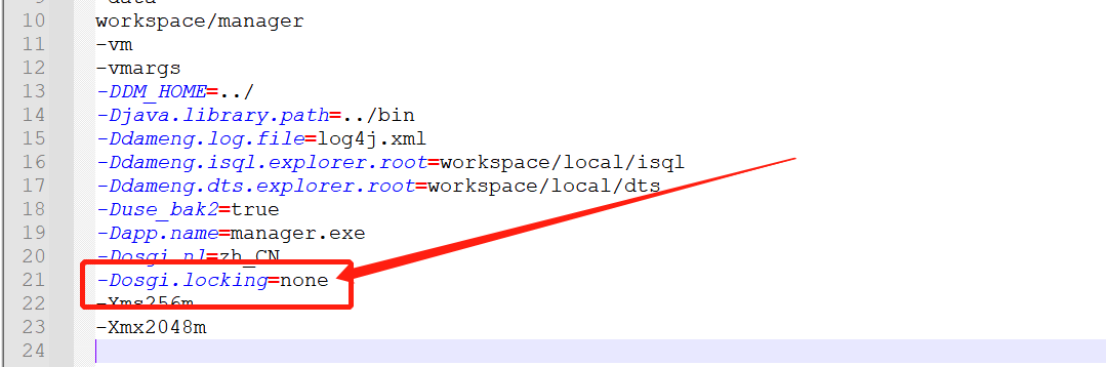
方法 2:
打开位于../tool 目录下的 manager 配置文件,manager.ini 添加参数 -Dosgi.locking=none,并保存生效。
控制文件 dm.ctl 被误删,启动报错:[code:-803]
【问题详情】:
Read ini error,name:CTL_PATH,value:xxxxxx
[invalid ini config value]
nsvr_ini_file_read failed,
[code:-803]
启动数据库报错如下:
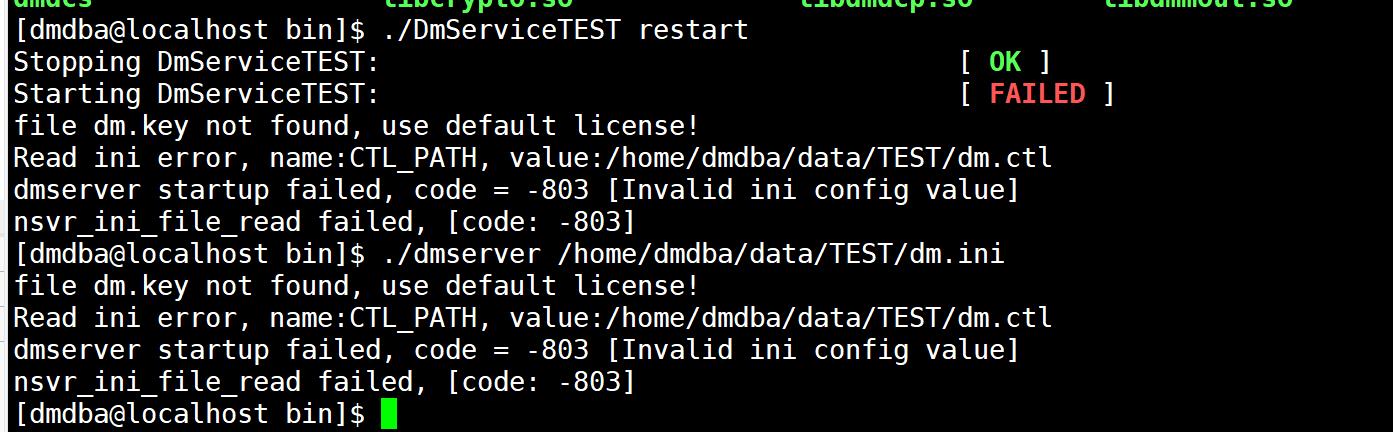
【解决方法】:
1)通过 ctl_bak 找回,用最近的一个 dm_xxx.ctl 改名启动

2)详情参考:文件误删除或损坏
数据文件 MAIN.dbf 或者自创表空间被误删
【问题详情】:


【解决方法】:
详细解答请参考:文件误删除或损坏
数据文件 ROLL.dbf,SYSTEM.DBF 被删后无法启动报错
【问题详情】:


【解决方法】:
详细解答请参考:文件误删除或损坏
误删除 TEMP.DBF 怎么处理
TEMP.DBF 被删后,重启数据库会自动生成一个新的。

undo 日志损坏
【恢复方法】:
undo 损坏优先选择“备份 + 归档”恢复,从实例日志获取故障时间;无备份归档的情况下,可以选择跳过 ROLL.DBF 启动数据库临时启动数据库(危险操作,可能破坏事务的原子性)。修改 dm.ini 参数 PSEG_RECV 为 0 。
注意PSEG_RECV 参数释意: 系统故障重启时,对活动事务和已提交事务的处理方式。 0:跳过回滚活动事务和 PURGE 已经提交事务的步骤。 1:回滚活动事务并 PURGE 已经提交事务; 2:延迟 PURGE 已提交事务,延迟回滚活动事务; 3:回滚活动事务,延迟 PURGE 已提交事务。
redo 日志损坏,报错[-723][-717]
【问题详情】:
举例:下面是断电后导致 redo 损坏的一个报错信息;
日志:Read rfil ['/data/dmdbms/data/DAMENG/DAMENG02.log'] from offset[67042304] failed,code [-723]
前台:main rfil [/data/dmdbms/data/DAMENG/DAMENG01.log]'s grp collect 0 invalid recv_pwr record.
【恢复方法】:
若备份归档文件都存在:
redo 损坏优先选择“备份 + 归档”恢复,从实例日志获取故障时间;
无备份归档的情况下,可以选择替换 redo 日志临时启动数据库(危险操作,可能会丢失一部分数据),然后将数据迁移出来。
若无法使用备份归档恢复下,替换 redo 启动数据库步骤:
- 命令模拟 redo 日志损坏
dd if=dminit20210203144245.log of=TEST01.log
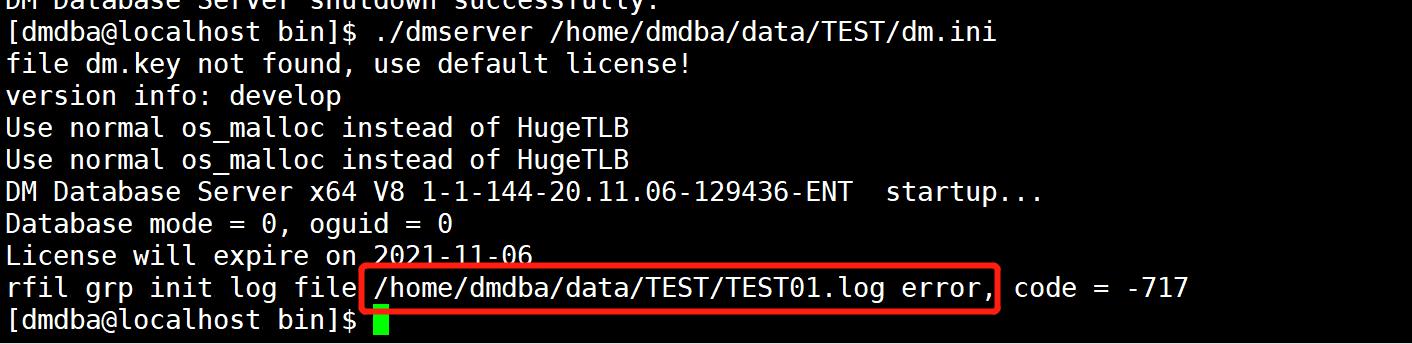
- 查看初始化日志,观察初始化参数,重新初始化一个新的实例并前台启动一次
./dminit path=/home/dmdba/data/dmdbms port_num=5237 db_name=TEST SYSDBA_PWD=****** SYSAUDITOR_PWD=******
./dmserver /home/dmdba/data/dmdbms/TEST/dm.ini
- 查看故障库的 db_magic 值和 pemnt_magic 值
./dmmdf type=1 file=/home/dmdba/data/TEST/SYSTEM.DBF

备注:db_magic:数据库魔数;pemnt_magic:数据库永久魔数
- 修改新库的 db_magic 值和 pemnt_magic 值并保存
./dmmdf type=2 file=/home/dmdba/data/dmdbms/TEST/TEST01.log


- 将修改后的 redo 挪到故障库下,尝试启动数据库
故障库:mv TEST01.log TEST01.log_old
新库:cp TEST01.log /home/dmdba/data/TEST/
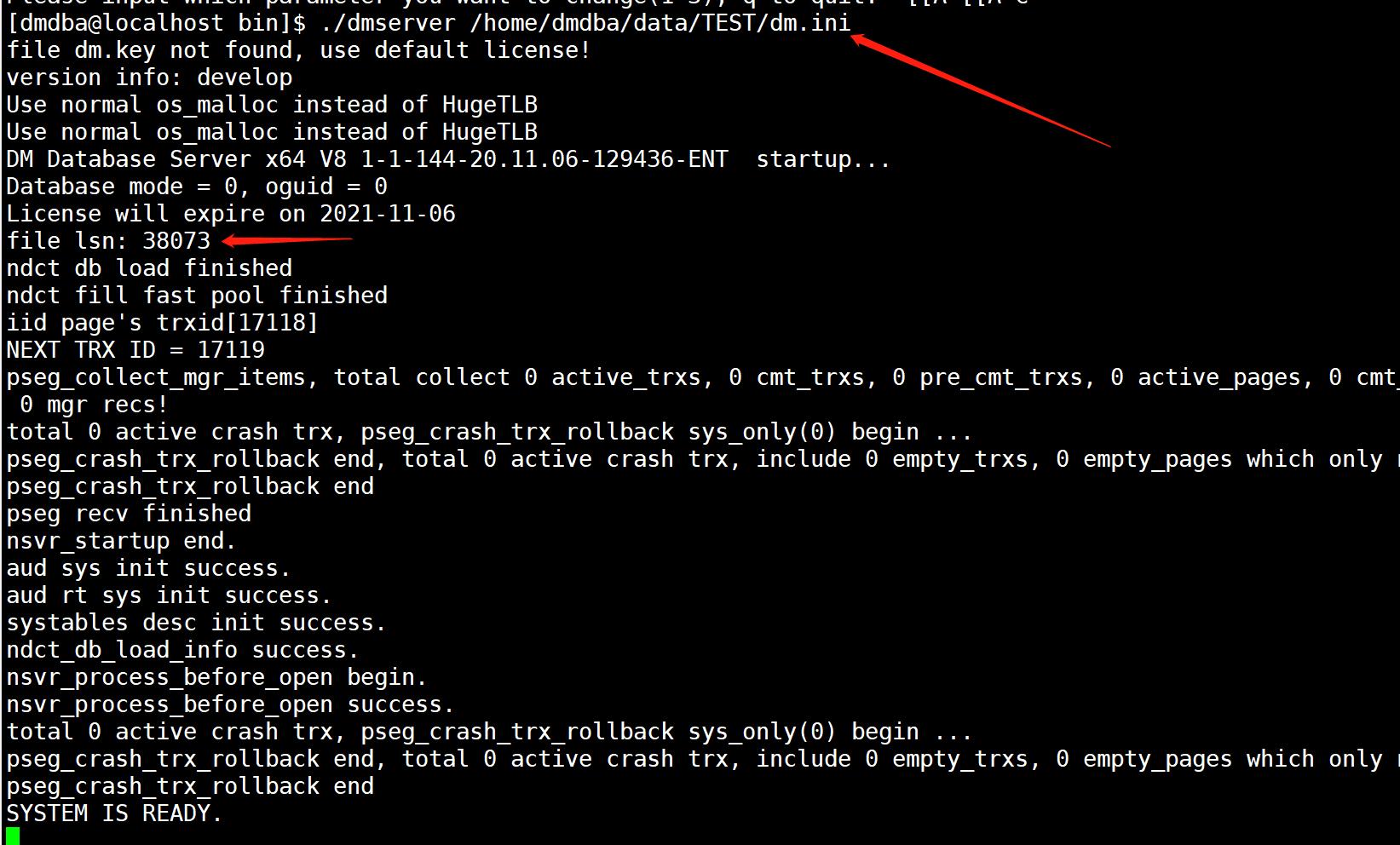
- 此时已经启动起来的数据库仍然存在隐患,应立即完成数据的迁移工作,防止再次发生宕机事故。
迁移方式采用 DTS 或逻辑导出导入。
在新的库上需要和故障库创建相同的用户及密码,并为每个用户指定表空间,分配数据文件。
--在已暂时启动的故障库
--查询用户名,用户默认表空间,表空间所在路径
select username,DEFAULT_TABLESPACE,profile from dba_users;

数据库页损坏
- 如果数据库仍可以启动
实例正常启停一次,然后执行下列语句:
./dmdbchk path=/home/dmdba/data/TEST/dm.ini
bin 目录下会生成一个 dbchk_err.txt,可能会记录有一些索引或者表错误,可以重建再做 dmdbchk 。
- 如果实例不能启动
关闭 IGNORE_FILE_SYS_CHECK 参数
备注IGNORE_FILE_SYS_CHECK 参数说明: 默认 0,检查文件系统。1,不检查文件系统。
磁盘问题导致故障
【问题描述】:
os_file_flush error!handle:3,code:30,desc:Read-only file system/error 请联系存储厂商进行处理。
磁盘空间不足导致故障:日志报错 out of space
日志报错:
tablespace 7 fail to extend.Please check disk space or extend attribute of data files.
tablespace 6 fail to extend.Please check disk space or extend attribute of data files.
ARCH_DEST[/opt/dmdbms/data/DAMENG/arch] will be out of space.
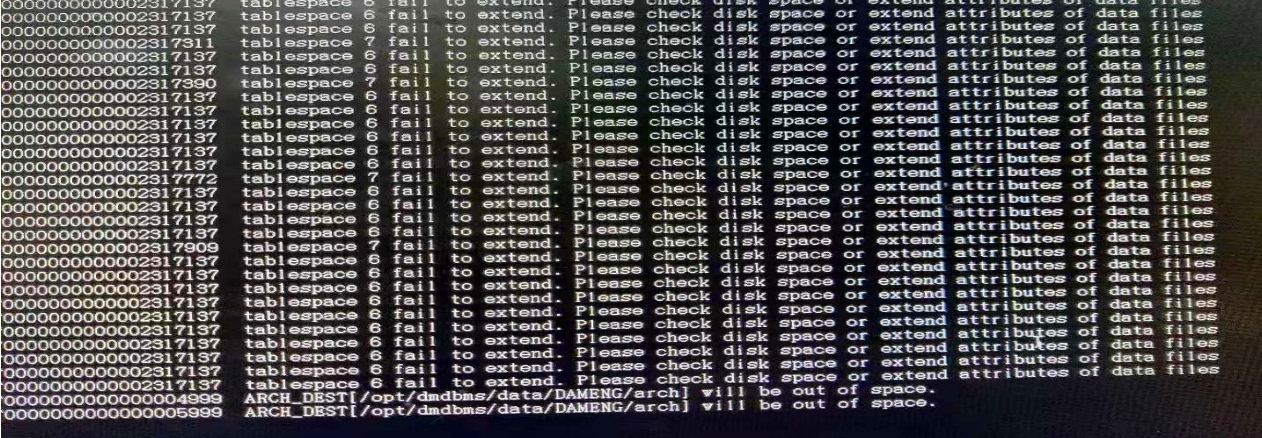
【问题解答】:
- 通过 df -h 查看当前归档文件所在目录(以/dmarch 为例)的空间使用情况;
- 查看定时删除备份有没有执行?--如果没删,可以删除。
- 查看 dmarch.ini 配置文件中的 ARCH_SPACE_LIMIT 参数设置,确认归档日志使用空间的大小限制是否超过/dmarch 的大小。此时分为两种情况:
情况一:ARCH_SPACE_LIMIT 设置的值大于/dmarch 的最大值;
此时考虑三种方法:
(1)进入/dmarch,备份归档日志到其他空闲磁盘,然后删除比较旧的归档日志使/dmarch 的可使用空间大于 10% 左右(谨慎操作)。
(2)备份 dmarch.ini,同时修改 ARCH_SPACE_LIMIT 的值到/dmarch 总大小的 90% 左右,使归档日志可以正常写入而不至于写满。
(3)对/dmarch 的空间进行扩容。
情况二:ARCH_SPACE_LIMIT 设置的值小于/dmarch 的最大值。
此时考虑是否其他应用占用了归档空间。进入/dmarch 确认是哪些非归档日志文件占用空间,确认占用的应用,挪走其他非归档日志文件,释放空间,同时修改其他应用对此空间的使用。
注意(1)导致归档日志空间被写满的原因有比较多种,当归档日志空间被非当前数据库实例使用,而导致数据库归档日志被写满无法启动,此种情况需要判断是什么应用占用了这个空间,然后确认是否可以直接删除或者将其备份到其他地方后删除。做完此步骤后,还需将数据库的归档日志空间独立出来,以免后续再次出现类似情况。 (2)ARCH_SPACE_LIMIT 设置大于归档日志空间所在磁盘的最大容量。此种情况下,建议备份历史的归档日志后,删除部分归档日志,腾出空间,同时将 ARCH_SPACE_LIMIT 的值调整到归档日志空间磁盘大小的 90% 左右,或者在对归档日志使用的目录进行扩容后,再进行重启数据库。
使用 Manager 管理工具的时候,出现卡顿的情况
应用出现卡顿一般是由于阻塞造成。但是 Manager 管理工具如果产生阻塞的事务,一般只是报错锁超时,或者当前窗口执行的语句一直在执行状态。
Manager 管理工具出现卡顿的情况,常见于两种场景:
- 打开管理工具的机器的内存或 CPU 资源不足;
- 旧版本客户端在执行耗时很长的 SQL 或执行耗时很长的操作时,可能会存在卡顿的情况。
数据库卸载后,只剩数据 data 文件夹里面文件,如何修复
重新安装数据库,安装时不用重新初始化库,将 data 目录全部拷贝到新安装的数据库安装目录下,只需要通过工具重新注册数据库服务,然后正常启动数据库即可。
运行 dbms_repository_snapshot.create_snapshot() 生产快照的时候会卡住
快照的表空间默认只有 10 GB。
使用命令:CALL SP_INIT_AWR_SYS(0); 可以清理一下 AWR 环境,扩大 AWR 报告的表空间数据文件上限或者加一个数据文件,如下命令操作:
alter tablespace "SYSAUX" datafile 'SYSAWR.DBF' autoextend on maxsize 102400;
alter tablespace "SYSAUX" add datafile 'SYSAWR_APPEND.DBF' size 128 autoextend on;
在更新 /updte 数据的时候突然卡住,没有任何报错
可能原因:update/ 更新同一行语句需要提交之后才能修改,默认行锁。
- 提交或回滚产生阻塞的事务
只需要在发生阻塞的会话下提交或回滚事务,锁自然会被释放,阻塞解决。
- 关闭产生阻塞的会话
我们也可以使用系统过程 SP_CLOSE_SESSION(SESS_ID) 来关闭对应的会话。
disql 执行语句后无法退出,Ctrl+C 也没用
exit 退出,或者 kill 掉 disql 进程。
V$SESSIONS 视图中获取的 LAST_SEND_TIME 和 LAST_RECV_TIME 不准确
【问题描述】:
尝试通过 V$SESSIONS 中的 LAST_RECV_TIME 和当前系统时间来计算当前活动会话的执行时间,发现连接的 LAST_SEND_TIME 和 LAST_RECV_TIME 返回值不正确,均为 1970-01-01 08:00:00.000000

【解决方法】:
- 查看 ENABLE_MONITOR 参数的配置值
SELECT PARA_NAME,PARA_VALUE FROM V$DM_INI WHERE PARA_NAME='ENABLE_MONITOR';

- 使用管理员用户连接数据库,动态修改 ENABLE_MONITOR 参数值,开启系统监控功能;
SP_SET_PARA_VALUE(1,'ENABLE_MONITOR',1);

- 新建数据库连接,查看新建会话的 LAST_SEND_TIME 和 LAST_RECV_TIME
SELECT CREATE_TIME,LAST_SEND_TIME,LAST_RECV_TIME FROM V$SESSIONS;

环境变量或者 dm_svc.conf 配置不合理导致 disql 登录不正常
【问题描述】:
- 现象 1:disql sysdba/*****@192.168.xx.xx:5236 登录本地服务器,未提示已登录,执行 SQL 报 “未连接”,需要 login,相同命令登录远程服务器正常,远程客户端登录本服务器也正常,切换到 dm 的 bin 目录下执行 ./disql sysdba/****@192.168.xx.xx:5236 任何服务器均可登录成功。
【解决方法】:
- 说明客户端和服务端均可以正常使用,区别就是使用了环境变量的方式登录本地异常;检查环境变量,对比其他节点,改成一样,问题解决了。
- 总结:环境变量在初始安装后,额外添加或者修改的项目,确保知悉其影响,不合适的配置可能会导致 disql 登录异常
【问题描述】:
- 现象 2:运行./disql 登录任意 ip:port 或者是服务名,均持续卡住无返回,其他节点上客户端均正常
【解决方法】:
- 检查 dm_svc.conf 文件,配置如下:
TIME_ZONE=(480)
LANGUAGE=(cn)
LOGIN_MODE=(2) # 只连主机
LOGIN_STATUS=(4) # 只连OPEN状态
SWITCH_TIMES=(1000) #无法建立符合要求的连接时,循环遍历服务名列表的次数
SWITCH_INTERVAL=(1000) #无法建立符合要求的连接时,两次遍历间的时间间隔
#DO_SWITCH=(1)
DB_ALIVE_CHECK_FREQ=(10000)
DB_ALIVE_CHECK_TIMEOUT=(10000)
SOCKET_TIMEOUT=(20000)
DWHW=(192.168.104.31:45236,192.168.104.32:45236)
将其中非默认的全局参数全部还原(删除)后,恢复正常。
总结:该文件中 SWITCH_TIMES 和 SWITCH_INTERVAL、LOGIN_MODE 建议保持默认,不要随意调整,以上值不合理,会导致连接迟迟无法成功建立。另外,上面是全局配置,不建议在这里修改参数,建议在下面新建需要的别名的专用参数。
管理工具 “编辑数据” 报错 “结果集不可更新”
【问题描述】
使用管理工具“编辑数据”功能按钮,提示:”结果集不可更新,请确认查询列是否出自同一张表,并且包含值唯一的列“。如图:
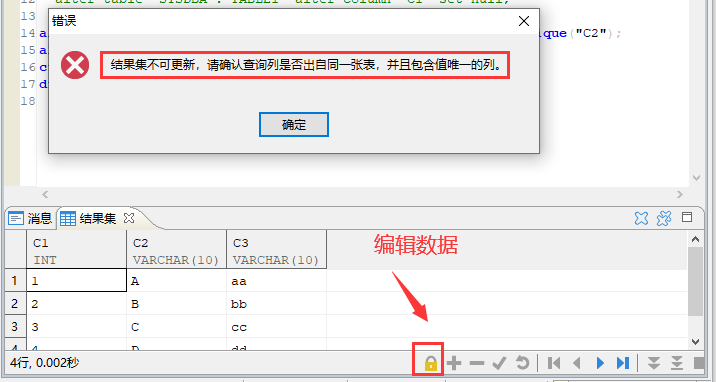
【解决方法】
主要有三种处理方法:
第一种:添加主键约束
alter table "SYSDBA"."TABLE1" add constraint PK_C1 primary key("C1");
第二种:添加唯一约束
alter table "SYSDBA"."TABLE1" add constraint "CONS_UNQ_C2" unique("C2");
第三种:创建唯一索引
create unique index "IDX_UNQ_C1" on "SYSDBA"."TABLE1"("C1");
kettel 抽取 number 整数类型变为小数、插入 number 类型小数保留精度不对
如果连接类型使用【generic database】,获取整数类型的方法为 getDouble,导致结果变为小数。
例如:数据库中数据为 1922,但通过 kettel 的抽取结果为 1922.0
该问题是由于 kettel 的通用数据源中获取数据的方法存在问题,可通过使用 Oracle 的连接来绕过,连接类型选择 Oracle,jdbc 的 url 以及驱动类均配置为 Oracle。将 dm8-oracle-jdbc16-wrapper.jar 与 DmJdbcDriver.jar 一起放入 lib 目录。
数据库服务器通过管理工具连接本地数据库时,报错-703 服务器模式不匹配
【问题描述】:
连接数据库时报错,提示服务器模式不匹配。如下图所示:
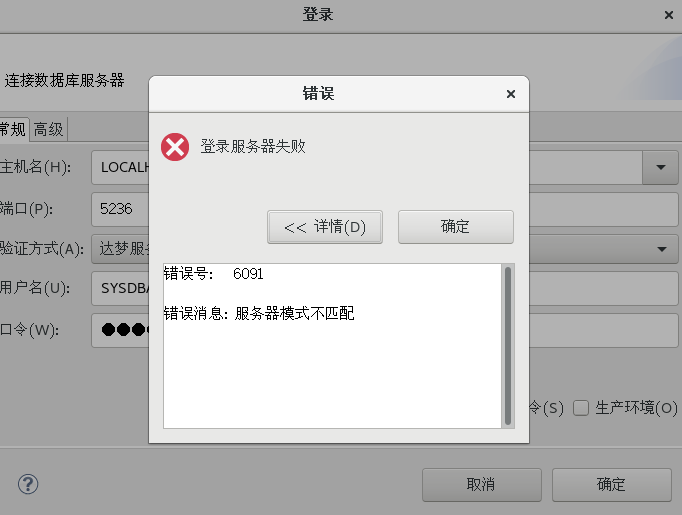
【解决方法】:
检查客户端的 dm_svc.conf 是否配置全局参数 LOGIN_MODE=(1)。
当 LOGIN_MODE 配置成 1 时,连接单机库无法登陆,会抛出“服务器模式不匹配”的报错,去掉此参数即可;通常 LOGIN_MODE=1 为主备集群配置,但需配置集群连接时,将此参数配置成局部参数即可,示例如下:将 LOGIN_MODE=(1)移到[DM_DW]下面
TIME_ZONE=(480)
LANGUAGE=(cn)
DM_DW=(192.168.10.11:5236,192.168.10.12:5236)
[DM_DW]
LOGIN_MODE=(1)
拓展:LOGIN_MODE 参数描述:指定优先登录的服务器模式。0:优先连接 Primary 模式的库,Normal 模式次之,最后选择 Stantby 模式;1:只连接主库;2:只连接备库;3:优先连接 Standby 模式的库,Primary 模式次之,最后选择 Normal 模式;4:优先连接 Normal 模式的库,Primary 模式次之,最后选择 Standby 模式。
达梦 manager 客户端登录提示网络通信异常
- 检查网络;
- 检查数据库服务是否启动;
- 检查防火墙是否开启;
- 检查网络是否有对端口做限制;
sqlserver 创建 dblink 失败
【问题说明】:
windows 环境下,sqlserver 创建链接服务(dblink)连接 DM(安装在 windows 上),ODBC 测试连接成功,信息填写正确,但 sqlserver 创建链接服务时,报未发现数据源名称且未找到数据库驱动。
【解决方法】:
由于 windows 文件权限问题导致,未使用 administrator 或对应用户安装时,需要在 DM 安装目录 bin 下手动加入 USERS 用户组。
具体操作为:右键 DM 的 bin 目录,属性-安全中,用户及用户组下点编辑-添加,输入 USERS 添加。之后可以正常创建 sqlserver 至 DM dblink。
启动数据库后应用一连接就 core 掉
【问题分析】:
需要根据 core 文件具体分析:
- 数据库中某张表损坏:可使用 dmdbchk 的方式检查数据文件是否损坏,若表有问题可采用先将有问题的表备份,之后删除重建的方法解决。
正常关闭 /home/test/dmdbms 目录下的数据库后,用以下语句检查数据文件:
./dmdbchk PATH=/home/test/dmdbms/dm.ini
- 索引损坏:可以采用直接重建索引的方法解决。
使用 disql 工具操作数据库时提示:连接丢失
【问题解决】:
这种情况很可能是数据库突然挂死,查看数据库服务进程是否还在:
ps -ef |grep dms
然后去安装目录下的../log 文件夹下查数据库实例日志,根据日志信息具体分析。
启动数据库报错:System information is invalid,please check ../DAMENG/SYSTEM.DBF or its mirror file
【问题描述】:
启动数据库失败,具体报错信息如下:

【问题解决】:
这是 SYSTEM.DBF 文件损坏了,可通过备份来修复数据库,基于备份进行库级还原和归档恢复到最新状态。
具体方法可以参考《DM 备份与还原》手册(手册位于数据库安装路径 /dmdbms/doc 文件夹下)。
vpn 环境下管理工具连接数据库报错:网络通信异常
【问题描述】:
telnet 端口正常,数据库服务已启动,利用 VPN,管理工具连接报错:网络通信异常。
【问题解决】:
由于使用 vpn 连接,因此在 manager.ini 追加参数,修改为只支持 IPV4。
-Djava.net.preferIPv4Stack=true
数据库报错 IO timeout overtime 3 of IO_TIMEOUT
【问题描述】:
数据库日志记录: check page IO timeout overtime 3 times of IO_TIMEOUT,please check disk.
如下图所示:

【问题解决】:
出现该报错的原因是磁盘故障导致写 redo 一直写不进去,等待了 IO_TIMEOUT*3 次以后还是失败,直接 halt。
可通过调整 dm.ini 中 IO_TIMEOUT 参数值,将其放大(IO_TIMEOUT 参数为动态参数),并检查磁盘的故障问题。
DM6 数据库出现宕机现象
【问题描述】:
DM6 版本数据库服务启动后,运行一段时间后数据库 core 了,且数据库宕机时数据库日志中断。
【问题解决】:
通过以下步骤进行排查:
1.进入数据库主目录,输入以下命令查看数据库堆栈信息;
gdb dmserver core.**** 依次输入以下命令:
bt
f 0
p *ctl
堆栈内容显示:Cannot access memory at address 0x0 就可以确定为缓冲区不够了,导致的数据库宕机。
2.查看当前执行的 SQL 语句;
依次输入 bt
f 6
p stmt->sess->sqls
3.确定为执行某 SQL 时缓冲区内存不足,造成数据库宕机故障。
4.根据服务器可分配的内存来合理调整配置文件(dm.ini)中 buffer 和 max_buffer 的值,dm6 数据库 buffer 的计算公式为:
占用的内存(单位 G)=(buffer * pagesize)/1024/1024。Buffer 的推荐值,系统缓冲区大小为可用物理内存的 60%~80%,有效值范围(100-16777216)。
达梦 DSC 集群,其中一个节点宕机,另一节点正常提供服务
【问题解决】:
出现该问题是由于宕机节点使用的操作系统信号量被清除,导致该节点进程异常中止,重新启动数据库可正常运行,但后期仍会不定时出现宕机现象。
解决方案为修改 /etc/systemd/logind.conf 配置文件中的 RemoveIPC 参数,将 # 注释去掉,并修改 yes 为 no。
linux 下数据库运行过程中误删除某个表空间数据文件,如何快速进行恢复
【问题解决】:
数据库运行中误删除了某个表空间数据 dbf 文件,不用停止或重启数据库,尽快进行以下操作:
- SYSDBA 登录数据库调用存储过程 SP_TABLESPACE_PREPARE_RECOVER(tablespace_name)尝试进行表空间恢复;
- 查找文件副本,首先找到数据库 dmserver 服务 pid(命令:ps - ef|grep pid),操作系统执行 ls /proc/pid/fd -l 找到带有 deleted 字样的 dbf 文件;
- 将文件 cp 到原数据文件存放位置,给用户权限;
- SYSDBA 登录数据库调用系统过程 SP_TABLESPACE_RECOVER(ts_name)完成文件修复。
数据库服务无法启动,执行服务启动命令后提示:os_file_flush error desc:Read-only file system
【问题分析】:
报错截图如下:
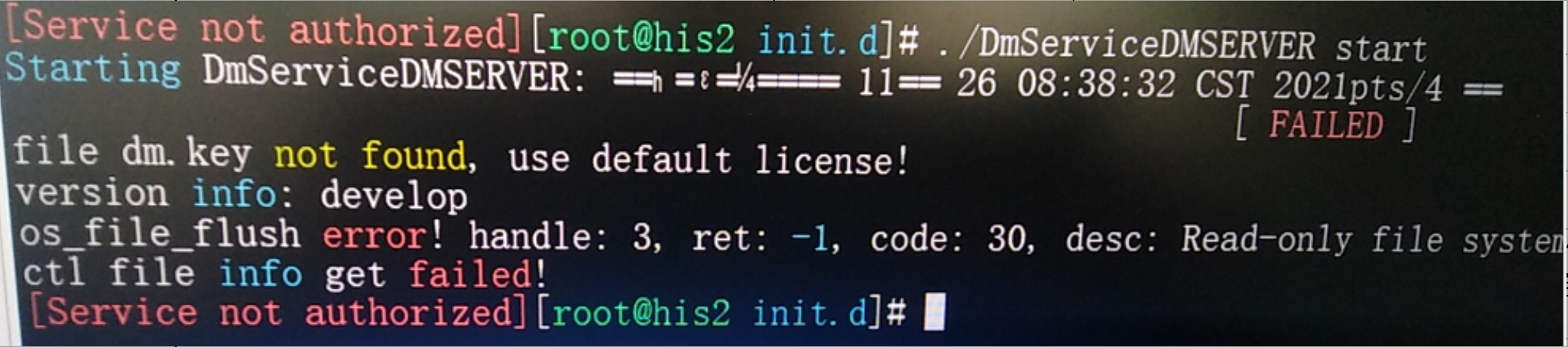
此问题多出现在具备磁盘阵列的数据库环境上,数据文件存储在磁盘整上,当阵列链路出现过中断或者阵列掉电重启的情况下会造成文件系统只读。数据库服务启动后在进行数据文件变更操作出现此问题。可以尝试重新挂载文件系统,然后重启数据库服务。
数据库服务突然中断
【问题分析】:
可检查 bin 下没有 core 文件产生,分析 core 文件,或检查数据库运行日志没有告警或报错信息。
例如:当数据库服务突然中断,检查查看操作系统日志/var/log/messages.debug 会发现明显的报错,Out of Memory: Kill process 类似的错误信息。如下图所示:
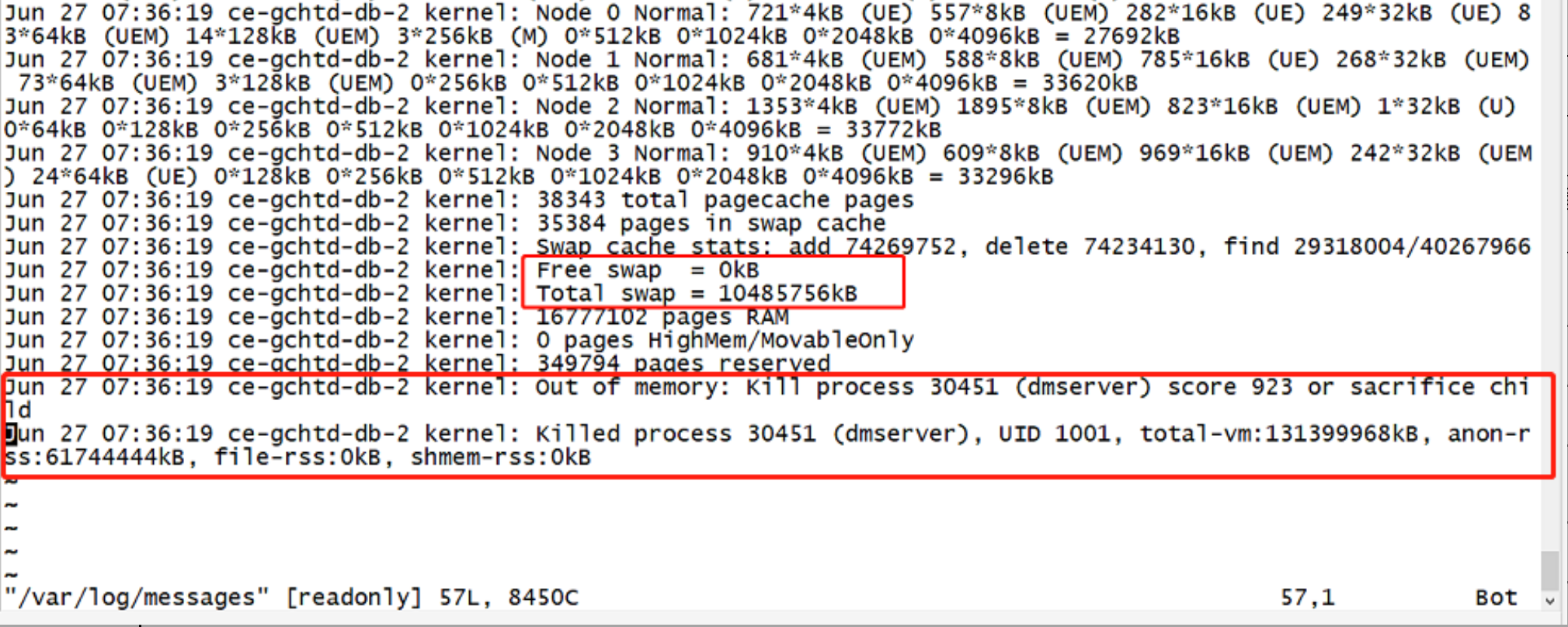
此时表示数据库因内存不足而出现服务中断。应查看内存使用情况 free -g ,适当调整数据库 buffer、memory_target、recycle 等参数。
服务无法启动,前台启动报错:非法指令(核心已转储)
【问题描述】:
服务无法启动,前台启动报错为:非法指令(核心已转储)

服务日志中出现 FATAL 致命错误:Redo log try flush over space;code -5,dm_sys_halt now!

【问题解决】:
日志报错的含义为“日志环被冲破”。随着业务规模和数据量的增长,事务中所包含的 DML 操作引起的变化量会持续增长,若某一时间点,进行一个或多个长事务,事务中包含有大量的 DML 或 DDL 操作,就会引发 redo 日志容量不足的问题,即冲破日志环。可参考如下步骤解决:
- 完整备份故障时刻实例数据;
- 尝试调大 RLOG_RESERVE_SIZE 参数, 或者增加在线日志大小和个数;
- 如果数据库已无法启动报错,源实例中修改 dm.ini 中参数 RLOG_CHECK_SPACE=0(日志刷盘时,不检查日志空间是否溢出)后启动服务即可。启动后第一时间备份数据,迁移至新的环境。
启动 dmwatcher 报错:fail to read ini file
【问题描述】:
[dmdba@localhost bin]$ ./dmwatcher /soft/dsc/config/dsc0_config/dmwatcher.ini
DMWATCHER[4.0] V8
Invalid [arch_name] or the file contains unrecognized characters!
Read ini file(/soft/dsc/config/dsc0_config/dmarch.ini) error in line 1, code(-104)
Read dm.ini(/soft/dsc/config/dsc0_config/dm.ini) failed, code = -104!
fail to read ini file
【问题解决】:
从报错信息来看,需核实对应的配置文件。除了核实该文件是否存在、文件权限是否正确之外,还需要核实配置文件中是否存在全角的空格。
若配置文件内容及权限没有问题,则需注意文件中全角和半角符合的问题,建议将配置文件是复制到 notepad 中去看,一定要设置“显示空格和制表符”的选项,便于排查。

设置“显示空格与制表符”:
注意配置文件尽量不要使用从 windows 上拷贝复制文件,同时检查空格和换行符。
数据库版本升级后,DmAPService 服务启动失败报错
【问题描述】
数据库版本升级后,DmAPService 服务启动失败,报错信息如下:
---脚本服务启动报错
[root@MI8SE-liuzhenbindeMI bin]# ./DmAPService start
Starting DmAPService: touch: cannot touch '_REPLACE_SELF_DM_HOME/log/dmsvc_sh.log': No such file or directory
chown: cannot access '_REPLACE_SELF_DM_HOME/log/dmsvc_sh.log': No such file or directory
./DmAPService: line 412: _REPLACE_SELF_DM_HOME/log/dmsvc_sh.log: No such file or directory
su: user does not exist
[ FAILED ]
cat: _REPLACE_SELF_DM_HOME/log/DmAPService.log: No such file or directory
---系统服务启动报错
[root@MI8SE-liuzhenbindeMI bin]# systemctl start DmAPService
Job for DmAPService.service failed because the control process exited with error code.
See "systemctl status DmAPService.service" and "journalctl -xe" for details.
[root@MI8SE-liuzhenbindeMI bin]# systemctl status DmAPService.service
● DmAPService.service - DM Assistant Plug-In Service(DmAPService).
Loaded: loaded (/usr/lib/systemd/system/DmAPService.service; enabled; vendor preset: disabled)
Active: failed (Result: exit-code) since Sat 2022-01-22 11:04:56 PST; 7s ago
Process: 17659 ExecStart=/soft/dmdbms/bin/DmAPService start (code=exited, status=1/FAILURE)
Main PID: 6129 (code=dumped, signal=SEGV)
Jan 22 11:04:56 MI8SE-liuzhenbindeMI systemd[1]: Starting DM Assistant Plug-In Service(DmAPService)....
Jan 22 11:04:56 MI8SE-liuzhenbindeMI DmAPService[17659]: mkdir: cannot create directory ‘_REPLACE_SELF_DM_HOME’: Permission denied
Jan 22 11:04:56 MI8SE-liuzhenbindeMI DmAPService[17659]: chown: cannot access '_REPLACE_SELF_DM_HOME/log': No such file or directory
Jan 22 11:04:56 MI8SE-liuzhenbindeMI DmAPService[17659]: mkdir: cannot create directory ‘_REPLACE_SELF_DM_HOME’: Permission denied
Jan 22 11:04:56 MI8SE-liuzhenbindeMI DmAPService[17659]: chown: cannot access '_REPLACE_SELF_DM_HOME/bin/pids': No such file or directory
【问题分析】
该报错是由于升级数据库版本直接替换 bin 目录,导致 DmAPService 脚本中 DM_HOME 环境变量信息变化。
【问题解决】
手动修改 DmAPService 脚本中 DM_HOME 环境变量,默认为 “_REPLACE_SELF_DM_HOME”,修改为数据库实际安装路径,如 "/opt/dmdbms"。
isql 或管理工具登录 DM6 数据库失败
【问题解决】:
可按照如下顺序进行排查:
1、检查数据库服务是否正常,是否有内存转储文件产生。
2、检查数据库进程 cpu 是否陷入循环。
3、检查是否有 io 等待。
4、检查内存使用是否正常。
5、检查数据库运行日志是否正常,检查点是否已固定频率刷新。
6、检查追踪日志内容正常刷新。
7、检查链接数是否充足:使用 netstat -ap|grep xxx|wc -l 检查,对比 ini 中最大连接数设置。若确认问题为连接数不足,则根据 netstat 命令结果,找到对应应用程序,沟通后由对应厂家停止应用进程,重新登录数据库即可。
管理工具返回结果集太大,中断加载,显示不全
【问题描述】
管理工具查询宽表报错:结果集如果过大,停止加载结果集
【问题分析】
报错的原因是由于结果集列较多,客户端 jvm 内存不足导致结果集无法正常加载。
【问题解决】
进入客户端安装目录下的 tool 目录,找到 manager.ini,增加或修改 jvm 如下配置内容。
-Xms256m
-Xmx2048m
-Xms 为最小分配的堆内存,默认为 256;
-Xmx 为最大分配的堆内存,manager.ini 中默认配置为 2048m;
根据客户端机器配置及结果集大小,适当扩大参数配置,即可正常加载结果集
数据库 roll.dbf 损坏需要替换
【问题解决】:
当数据库出现以上问题时,可通过以下步骤进行解决:
1、修改数据库 dm.ini 参数 PSEG_RECV=0 后重启数据库。其中修改参数 PSEG_RECV=0 后,可跳过回滚启动数据库;
2、正常停止数据库,将 roll.dbf 文件 mv 至其他目录;
3、按照该库参数初始化一个新数据库,并进行正常启停操作;
4、将新数据库生成的 roll.dbf 拷贝至原数据库的原 roll.dbf 路径;
5、修改原数据库 dm.ini 参数 PSEG_RECV=1 后启动数据库。
perf top 异常热点 lock_release_check_savepoints
【问题分析】:
如下图所示:
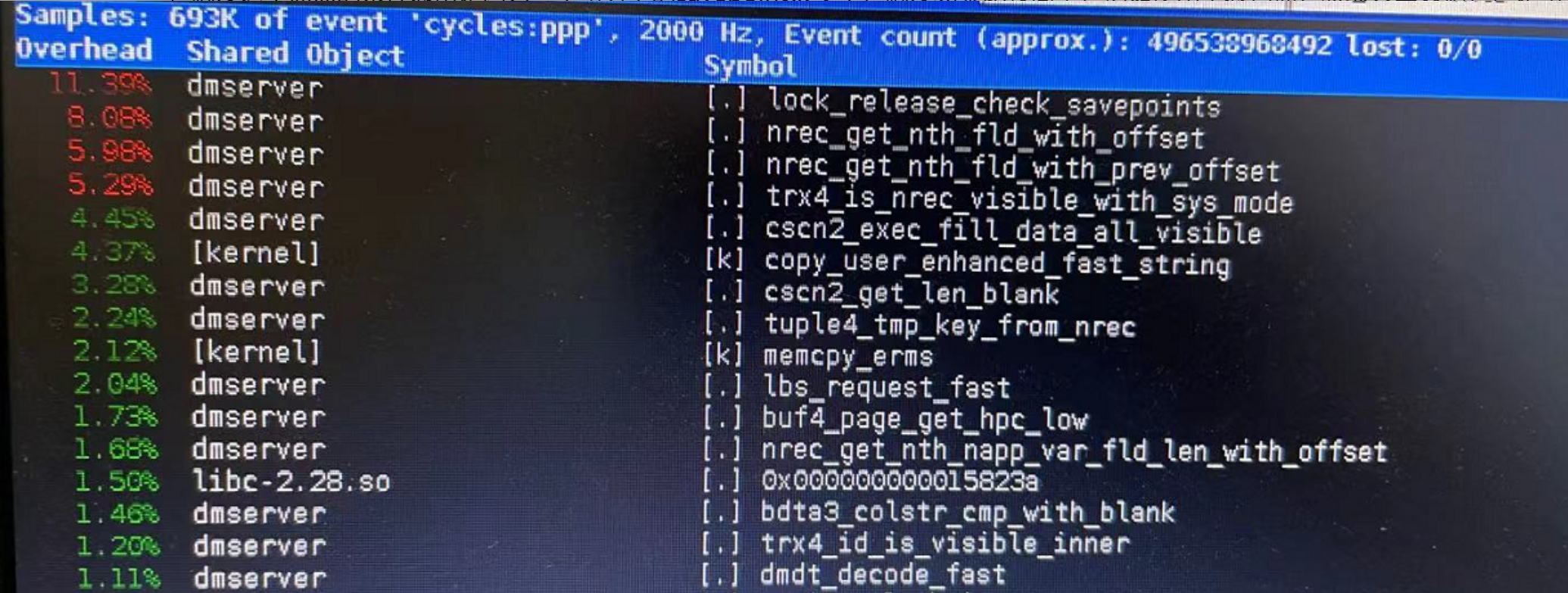
触发这个热点的条件通常是因为一个事务上的 savepoint 太多了,触发场景比较简单,例如使用全表扫描,获取大量数据,但是事务一直不提交,并且不获取全部数据,这样每次前 100 行就会加一个 savepoint,这样会导致事务的 savepoint 残留。
savepoint 的产生机制:对于每一个 SQL 命令,可以参考 java 的 try catch 机制。
1、首先我们创建一个 savepoint p1;
2、然后 try {
lock dict objects;
SQL statment;
}
3、当出现异常时 catch {
rollback to savepoint p1;
remove savepoint p1;
send message;
}
当我们的热点函数中出现 savepoint 时,可以通过视图来查询:
Select a.trx_id,a.sess_id,datediff(ss,a.last_recv_time,sysdate)ss,sf_get_session_sql(a.sess_id),b.savepoint_cnt,b.ins_cnt,b.del_cnt,b.upd_cnt,b.upd_ins_cnt
from v$sessions a,v$trx b
where a.trx_id = b.id
找到对应的事务后再针对性的进行分析处理。
DMMPP 主备集群登录后查询表报错:MPP 站点信息不匹配
【问题解决】:
问题原因:该表的表结构在每个节点上不一致,有些节点有这张表,有些节点没有这张表。可通过以下步骤解决:
1.用 MPP 局部登录,登录每一个节点看是否有这个表;
2.备份该表的数据;
3.在有这个表的节点 MPP 局部登录后执行:SP_SET_SESSION_LOCAL_TYPE (1);,并删除该表 drop table tab_name;。
4.再全局登录 DMMPP 重新创建该表,最后将数据导入。
使用低版本的 bin 目录启动集群失败
【问题描述】:
某环境 DM8 数据库中,前期使用替换 bin 目录的方式升级主备集群环境(从 8.1.2.84 升级到 8.1.2.94),运行一段时间后,想测试能否使用低版本的 bin 目录来启动主备集群。具体测试步骤如下:
-
将测试环境中的 bin 目录替换为低版本的 bin。
[dmdba@dmdb01 dmdbms]$ mv bin bin_new94 [dmdba@dmdb01 dmdbms]$ mv bin_bak0531/ bin [dmdba@dmdb03 dmdbms]$ mv bin bin_new94 [dmdba@dmdb03 dmdbms]$ mv bin_bak0531/ bin -
启动主备集群。
然而,使用低版本的 bin 目录启动主备集群后,使用非确认监视器发现:集群状态异常,主库自动关闭,备库也处于 mount 状态。
报错信息如下:
(1)监视器信息。
(2)检查 dm_DW1_01_202206.log 日志:发现是:Server DM8_DCT_VERSION mismatch, version of data is 41, server version is 38. 版本错误导致的。
(3)检查 dm_dmwatcher_DW1_01_202206.log 日志发现主备节点状态异常。
【问题解决】:
-
使用 dmctlcvt 工具分析 DM8_DCT_VERSION 版本。
[dmdba@dmdb01 bin]$ ./dmctlcvt TYPE=1 SRC=/dm8/dmdbms/data/DAMENG/dm.ctl DEST=/dm8/dmdbms/data/DAMENG/dm.txt DMCTLCVT V8 convert ctl to txt success! -
执行
more dm.txt发现 DM8_DCT_VERSION=41,如下图
- 修改 DM8_DCT_VERSION 从 41 改成 38。
-
重新生成 ctl 控制文件。
[dmdba@dmdb01 bin]$ ./dmctlcvt TYPE=2 SRC=/dm8/dmdbms/data/DAMENG/dm.txt DEST=/dm8/dmdbms/data/DAMENG/dm.ctl DMCTLCVT V8 convert txt to ctl success! -
重新启动主备集群,检查集群运行状态正常。
- 使用非确认监视器检查。
- 使用 disql 检查集群状态和数据库版本。
Windows 平台 Manager 调试带绑定变量参数语句时,SRVLOG 中始终缺少[SEL]标签执行信息
【问题描述】:
通过 Windows 平台 Manager 调试带绑定变量的 SQL 时,后台 SVRLOG 中始终缺少[SEL]标签的执行步骤,导致该条目中相应 EXEC TIME 一并丢失,但前台正确返回结果集,SRVLOG 如下图所示:
【问题分析】:
- 通过 disql 执行相同命令后台捕获正常。
- 通过 Linux 端 Manager 执行相同命令后台捕获正常。
考虑为 Windowds 平台 java 自身高速缓存导致其在没有发生变化的情况下跳过了执行步骤。
【问题解决】:
- 关闭客户端,并删除 workspace 下 manager 中生成的.metadata 目录。
- 找到 Windows 平台对应客户端路径下的 jre 控制面板工具。
- 依次执行临时 Internet 文件设置中的删除文件,并取消 “将临时文件保存在我的计算机上”选项后确定。
- 重新启动 Manager 执行测试,此时后台 SVRLOG 可以正确捕获完整流程。
DM6 数据库分离后的数据库附加时提示“数据库未正常分离”
【问题解决】:
此问题主要是由于 linux 下数据文件与数据库安装所使用的用户和组不一致导致。如果不一致,在附加时会出现报错:数据库未正确分离。将所要附加的数据库数据文件权限修改正确后,即可正常进行附加。
达梦 8 在程序中报错:“执行环境堆栈空间不足 -7059”
【问题解决】:
出现该报错可以同时从以下两个方面进行优化:
一、数据库层面调整
调整参数 VM_STACK_SIZE = 1024。
参数 VM_STACK_SIZE 表示系统执行时虚拟机堆栈大小,以 KB 为单位,堆栈的空间是从操作系统中申请的,有效值范围(64~256*1024),默认 256,该参数为静态,修改后需重启数据库生效。
二、程序调整
一般程序中出现“堆栈空间不足”或者“堆栈空间溢出”报错,可能原因如下:
- 有太多活动的 Function、Sub 或 Property 过程调用。
解决办法:检查过程的嵌套是否太深,尤其是递归过程,即自己调用自己的过程。确保递归能终止,使用 “调用” 对话框来查看活动的过程 (在堆栈上)。
- 本地变量需要更多可用的本地变量空间。
解决办法:试着在模块级别中声明某些变量。可以在静态过程,即在 Property、Sub 或 Function 关键字前加上 Static,声明所有变量,或可以在过程内使用 Static 语句来声明各个 Static 变量。
- 有太多定长字符串。
解决办法:定长字符串在过程中可快速访问,比可变长度字符串使用更多堆栈空间,因为字符串数据本身要放在堆栈上。可试着重新定义一些定长字符串成为变长字符串。当声明一变长字符串时,只有字符串描述符 (非数据本身) 会放在堆栈上。可以在没有堆栈空间的模块层次上定义字符串。在模块层次申明变量是缺省为 Public,所以在模块上所有过程皆可见到字符串。
- DoEvents 函数调用的嵌套太多。
解决办法:利用“调用” 对话框,在堆栈上查看正在活动的过程。
- 代码引起了事件层叠。
解决办法:所谓事件层叠就是引起一个事件,此事件会调用已在堆栈上的事件过程。事件层叠和不能中止的递归过程调用是相似的,但不太明显,因为是由 Visual Basic 所调用,而不是在代码中调用。使用“调用” 对话框来查看那些正在活动的过程 (在堆栈上)。显示“调用” 对话框,在“调试” 窗口中选取过程框右边的“调用”按钮或选择“调用” 命令。详细信息,可选取有问题的项目,并按下 F1 键。
数据库版本升级时报错:Upgrade is not allowed, please startup with original dmserver
【问题描述】:
主备在进行数据库版本升级时,出现报错:Upgrade is not allowed, please startup with original dmserver(sys_version:V7.1.8.18, db_version:0x7000C) and shutdown normally, then try again!
【问题分析】:
升级时出现该报错是因为新版本主备数据库服务没有正常停止(mount 下停止数据库时,有对数据文件的修改操作没有写入到数据文件导致数据文件写坏)。此时需要通过备份还原或者 cp 方式,重新还原正常的数据文件,以获取新版本可用的数据文件。
【问题解决】:
方法一:拷贝旧环境下正常的数据文件,并在新版本的 bin 目录下启动主备集群即可。
方法二:将故障的新版本主备集群修改为单机库后,通过备份还原重新搭建主备集群。
uos 系统中 core 文件不完整或无法查找到位置
【问题描述】
当程序出错而异常中断时,OS 会把程序工作的当前状态存储成一个 core 文件,保存了进程异常时的内存、寄存器、堆栈等数据。core 文件是分析内存错误的有用的文件,一般情况下(有时候代码编译的时候没有包含 debug 信息或者栈空间被破坏,会看不到具体的位置信息),结合 gdb 命令与 core 文件,可以知道导致 core 的具体的代码位置。
在进行操作系统中运维的时,可能遇见 core 文件生成不完整或者 不明确 core 文件生成位置等问题。此时可参照如下方法解决。
【问题解决】
- 通过
ulimit -c查询 coredump 开启状态。
结果为 0 表示 coredump 为关闭状态,非 0 时表示 coredump 为开启状态。注意 core 文件限制的太小也可能导致不 core 文件生成失败。建议 core 文件设置为 1024 以上,或者不限制其大小,单位 KB。
- 开启 coredump 或调整 core 文件大小限制。
可根据需要选择临时配置(即时生效,重启失效)或永久配置(重新登录用户或重启后永久生效)的方法。
- 临时配置
##临时配置:设置为固定大小,单位为 KB
unlimit -c {$size} size
##临时配置,不限制 core 文件大小
unlimit -c unlimited
- 永久配置。
配置永久生效需要先检查 uos 操作系统版本,不同版本配置有些不同。版本包括 a,d,e 三个版本。
##查看版本
cat /etc/os-version
EditionName[zh-CN]= a/d/e
##当 uos 版本为 a 版或 e 版时,如下配置
* soft core unlimited
* hard core unlimited
##当 uos 版本为 d 版时,如下配置
* soft core unlimited
* hard core unlimited
root soft core unlimited
root hard core unlimited
- 配置 coredump 转储路径
在 /proc/sys/kernel/core_pattern 文件中配置 coredump 转储位置及格式化 core 文件名称。此外,若 /proc/sys/kernel/core_uses_pid 文件的内容配置为 1,即使 core_pattern 中没有设置 %p,最后生成的 coredump 文件名仍会加上进程 ID。根据实际情况,也可直接使用默认的配置,默认位置为用户家目录。以下提供查看 coredump 转储位置命令。
##查看 coredump 转储位置
root@uos:~#cat /proc/sys/kernel/core_pattern
/usr/lib/systemd/systemd -c oredump %P %u %g %s %t %c %h %e
参数含义如下:
%p ##insert pid into filename 添加 pid
%u ##insert current uid into filename 添加当前 uid
%g ##insert current gid into filename 添加当前 gid
%s ##insert signal that caused the coredump into the filename 添加导致产生 core 的信号
%t ##insert UNIX time that the coredump occurred into filename 添加 core 文件生成时的 unix 时间
%h ##insert host name where the coredump happened into filename 添加主机名
%e ## insert coredumping executable name into filename 添加命令名
coredump 转储路径同样可进行临时配置和永久配置。具体方法如下:
(1)临时配置
## 临时配置
echo 0 >/proc/sys/kernel/core_uses_pid
echo "/corefile/core-%p-%u-%g-%s-%t-%h-%e" >/proc/sys/kernel/core_pattern
(2)永久配置
##永久配置
cat << EOF >> /etc/sysctl.d/coredump.conf
kernel.core_uses_pid = 0
kernel.core_pattern = /corefile/core-%p-%u-%g-%s-%t-%h-%e
EOF
##使配置文件生效
sysctl -p /etc/sysctl.d/coredump.conf
- coredump 测试。通过发送以下的信号会触发 coredump,生成 core 文件来验证测试。
kill -s SIGSEGV $$
root@uos:~#ls /corefile/
core-20684-0-0-11-1659918209-uos-bash
实例日志常见异常信息汇总
【问题描述】
实例日志位于数据库安装路径 “../log” 文件夹下,一般默认命名为 “dm_实例名称_月份.log”。实例日志主要记录数据库运行过程中的 INFO、WARNING、ERROR 和 FATAL 四类信息:
(1)INFO(正常):用于打印程序应该出现的正常状态信息, 便于追踪定位;
(2)WARNING(告警):表明系统出现轻微的不合理,一般不影响运行和使用;
(3)ERROR(错误):表明出现了系统错误和异常,无法正常完成目标操作;
(4)FATAL(致命):表明发生了严重的错误,会导致数据库宕机,服务停止。
一般在进行数据库日志监控时,主要关注以下内容:
(1)WARNING、ERROR 和 FATAL 类信息监控。
(2)INFO 类信息中涉及实例重启的信息。
以下列举达梦数据库实例日志中需要注意的日志信息。
【问题解决】
1. WARNING 信息。通常该信息为警告信息,需引起注意,但不影响数据库服务运行。常见 WARNING 场景如下:
(1)库启动告警
##告警信息提示缺少部分动态库,不影响系统运行
2022-03-06 17:13:57.999 [WARNING] database p0000052532 T0000000000000052532 fail to load libgeos_c.so.1.13.3, /home/dmdba/dm/dmdbms/bin/libgeos_c.so.1.13.3:cannot open shared object file:No such file or directory
2022-03-06 17:13:58.002 [WARNING] database p0000052532 T0000000000000052532 fail to load libgeoj.so,/home/dmdba/dm/dmdbms/bin/libproj.so:cannot open shared object file:No such file or directory
该信息表示未找到相关动态库信息,需确认服务端动态库是否有缺失,并通过 ldd 进行动态库相关排查。
(2)网络延迟告警
2021-11-05 11:23:14.633 [WARNING] database P0000368487 T0000000000000368602 rraft_ send_thread,cmd:115,send message to BP15_B timeout, used 151(ms), send hb message used 151(ms)
该信息表示网络出现延迟,若持续出现延迟现象则需排查延迟原因。
(3)网络通信告警
[WARNING] database P0000006257 mian thread Failure occurs in data_recv_inet_onec,code 10
该信息表示网络通信告警。可以执行 sp_set_para_value(1,'COMM_TRACE',0); 关闭该项检查。
(4)消息告警
2018-10-09 10:04:00 [WARNING] database P0000003097 mian_thread comm_inet_msg_recv more msg too long to 1735290788
该信息表示应用发到数据库服务器消息有问题。排查应用到数据库的网络及发送消息。
(5)key 授权告警
2018-10-09 10:04:00 [WARNING] database P0000003097 mian_thread License will expire on 2019-04-30
该信息为表示 key 即将到期,需更换新的授权文件。
2. ERROR 信息。通常该信息为错误信息,可能会导致数据库宕机,停止服务。常见 ERROR 场景如下:
(1)存储问题错误
##数据库服务无法启动,执行服务启动命令后提示
os_file_flush error ! handle:3,ret:-1,code:30 ,desc:Read-only file system
数据库服务启动后在进行数据文件变更操作出现此问题。可以尝试重新挂载文件系统,然后重启数据库服务。
(2)文件写入错误
2019-10-21 12:11:23 [INFO] database P0000005642 main_thread SYSTEM IS READY.
2019-10-21 12:11:37 [FATAL] database P0000005642 main_thread Fatal error: desc is full while try alloc new page
2019-10-21 12:11:37 [FATAL] database P0000005642 main_thread dm_sys_halt now!!!
2019-10-21 12:11:37 [INFO] database P0000005642 main_thread total 2 rfil opened!
根据报错信息可以看出是 xx 空间满了之类的问题,也有可能是数据文件损坏。可通过排查以下内容:
排查一:检查表空间和操作系统磁盘空间;
排查二:重启后,利用 dbcheck 检查是否有数据文件损坏。
(3)实例启动错误
[buf4_fast_pool_init] malloc global_buf4_pool ctls failure
数据库实例在启动时,无法申请到足够多的内存资源。查看数据库实例所在服务器,根据实际可用内存,调整达梦数据库实例配置文件 dm.ini 中的 buffer 参数,使 buffer 所设数值小于实际可用内存。
(4)REDO 校验错误
[ERROR] database P0000002814 T0000000000000002814arch file(/dm8/data/DAMENG/DAMENG01.log) len check fail(file:/home/test/yx/trunk8_rel_ 2010/log/rfil.c,line:1219)
[ERROR] database P0000002814 T0000000000000002814 rfil grp init log file /dm8/data/DAMENG/DAMENG01.log error,code=-717
[ERROR] database P0000002814 T0000000000000002814 rlog4_init_low->rfil_grp_alloc failed,alloc_only=0!
需替换 REDO 日志文件并启动数据库。
(5)数据文件损坏错误
2021-08-06 15:57:44 [ERROR] DB check P0000003180 T0000140208147420960 nbtr_check_page error:page(5,0,152572) rec of slotno 1 is min or max rec,file :/home/fuxin/trunc/dta/nbtr5.c,line :1636
重启尝试恢复,如果数据文件有损坏,尝试检查数据文件损坏情况,进行恢复,或使用备份文件还原数据库。
(6)接口错误
[error]: database P0000002968 main_thread cmd 5 validate error!
该错误表示使用了错误的接口,消息非法,比如使用不兼容的 DPI 或是 JDBC 来连接数据库,导致服务器认为客户端发过来的 prepare 消息数据不对,无法通过格式校验。
(7)连接数超出限定值错误
[ERROR] database P0000006257 mian_thread Reached the max session limit.
该错误表示连接数超出限定值错误。dm.key 和 max_session 均存在最大连接数限制,且 key 的并发数和 max_session 中的最大连接数取最小值,若实际连接数超过限定值,则会出现此报错。
3. FATAL 信息。通常该信息为“致命错误”,会导致数据库宕机,服务停止。
(1)FATAL:磁盘故障
2021-04-11 23:37:19:475 [FATAL] database P0000023070 T0000000000000023104 check page io timeout overtime 3 times of io TIMEOUT.please check the disk
2021-04-11 23:37:19.475 [FATAL] database P0000023070 T0000000000000023104 code=-1.dm_sys halt now!!
该信息表示磁盘故障,导致写 redo 一直写不进去,等待了 IO_TIMEOUT*3 次以后还是失败,直接 halt。可考虑调整 dm.ini 中 IO_TIMEOUT 参数值(动态参数),并检查磁盘的故障问题。
(2)FATAL:数据文件损坏
2021-01-07 11:19:23 [INFO] database P0000003788 main_thread SYSTEM IS READY.
2021-01-07 11:22:32 [FATAL] database P0000003788 dm_sql_ thd Invalid xdec_length:0
2021-01-07 11:22:32 [FATAL] database P0000003788 dm_sql_ thd Invalid xdec_length
2021-01-07 11:22:32 [FATAL] database P0000003788 dm_sql_ thd dm_sys_halt now!!
2021-01-07 11:22:32 [FATAL] database P0000003788 dm_sql_ thd total 2 rfil opened!
该信息表示数据文件出现损坏,应及时检查数据文件损坏情况,进行恢复,或使用备份文件还原数据库。
(3)FATAL:索引损坏
[ERROR]: database P0000043976 main_thread INDEX [MES_WIP_COMP_PK1] ID33698687 is corrupt! line 4809 in file: /data/jq/trunk7_ent/op/nupd2.c
数据库中索引损坏,导致数据库宕机,需对该表进行重建。
(4)FATAL:dm_sys_halt
2021-01-07 11:22:32 [FATAL] database P000003788 dm_sql_thd dm_sys_halt now!!!
该信息表示达梦数据库 halt,应排查数据库日志或系统日志中导致数据库 halt 原因。
DSC 环境下某节点服务重启后数据库服务无法 open
【问题描述】
DSC 环境下,一个节点的虚拟机意外断电,该节点服务重启后数据库服务一直处于 startup 状态,无法 open。
【问题解决】
检查是否进行过参数修改。例如:修改了 BUFFER 等参数,没有重启 DSC 集群,此时一个节点宕机后,宕机的节点启动时 BUFFER 是修改过的值,与当前正在运行节点的参数值不一致,会造成该节点加入时服务无法正常启动。
数据库运行日志报错:pwrite error
【问题描述】
数据库运行日志报错:pwrite error 时排查方向有哪些?
【问题解决】
- 检查实例数据文件和归档文件所在磁盘是否可以正常读写,可通过创建新文件输入内容后保存测试。
- 检查实例数据文件和归档文件所在磁盘是否还有剩余空间,可通过 Linux 命令
df -h进行查看磁盘剩余空间。
达梦数据库启动报错:结构需要清理
【问题描述】
操作系统为 CentOS,虚拟机异常断电后,达梦数据库启动报错:“结构需要清理” 。
【问题分析】
在数据库安装的目录删除和创建文件等操作时同样报错:“结构需要清理”。通过检查 Linux 操作系统日志也发现了同样的报错信息。
在 Linux 操作系统中出现报错:"结构需要清理",说明磁盘文件出现问题,该问题一般是文件系统出错导致。
【解决办法】
卸载磁盘设备并修复文件系统后,数据库即可正常启动。如果磁盘是 ext4 格式就用 fsck.ext4 命令修复,如果磁盘是 xfs 格式就用 xfs_repair 命令修复。(使用此方法存在数据丢失风险,操作之前请做好相关备份)
例如:xfs 格式磁盘并修复。
挂载磁盘启动数据库。
注意使用此方法存在数据丢失风险,操作之前请做好相关备份,以免发生数据丢失,生产环境请谨慎操作。
数据库日志报错:"[FATAL]: os_io_low read error!"
【问题描述】
数据库日志报错:[FATAL]: os_io_low read error!,后续备份又报错:”-[8024] :数据文件读写出错“。
【问题分析】
从日志文件中可以推测为系统 IO 的读错误,首先排查数据盘的问题,在拷贝 TEMP.DBF 时出现报错如下:
[dmdba@bms-bosi-unit-acc DAMENG] $ cp TEMP.DBF ../TEMP_TEST.DBF
cp: error reading 'TEMP.DBF':lnput/output error
cp: failed tO extend ' .. /TEMP_TEST.DBF':lnput/output error
然后通过命令 tune2fs -l /dev/nvme0n1p2 | grep 'Filesystem state' 来查询数据盘是否有错误数据,结果如下:
[root@bms-bosi-unit-acc log]# tune2fs -l /dev/nvme0n1p2 | grep 'Filesystem state'
Filesystem state: clean with errors
确定该数据盘确实存在问题。
【解决办法】
需联系硬件厂商解决。