本章节主要对达梦数据库集群安装部署常见问题进行分析和处理,以下提供达梦数据库集群安装部署常见问题的分析和解决思路供用户参考。除此之外,用户还可前往达梦技术社区参与更多问题讨论。
目录
- 后台服务的方式启动了监视器,如何查看集群中各节点的状态
- 达梦共享集群是采用裸设备还是共享文件系统?有什么配置要求
- 启动主备集群时数据库一直处于 mount 状态
- 读写分离集群部署时正常,但重启了数据库服务后,导入数据后,发现读库无数据
- DSC 环境中数据库正常运行,但通过 DmServiceDsc1 status 获取不到数据库运行状态
- 搭建 mpp 主备时,如何使用 MPP 类型为 LOCAL 方式设置 OGUID 值
- 创建好主备集群后,备机无法连接
- 两套主备集群如何共用一台监视器
- 初始化实例时报错 create rlog file +DMLOG/log/DSC1_log02.log failed, code: -7013.
- MPP 登录查询只有一个实例
- MPP 集群启动服务报错:MAL sys initialization failed
- 创建 SOCKET 连接失败
- DSC 集群配置都正确,但启动集群时报错
- DEM 部署达梦数据守护集群提示:没有到主机的路由
- 主备集群中 dmwatcher 服务报错:Segmentation fault (core dumped)
- MPP 变更表结构后,查询表报错:site info mismatch
- 安装 DSC 集群时报错:”[code : -11041] ASM connection exception“
- DSC 集群启动 asm 服务报错:"[code: 12000]实例已经启动"
- 读写分离集群应用启动异常
- DPC 集群启动 MP 日志报错:“can't find self config in mp.ini”
- 回滚表空间不足
- DSC 集群 CSS 启动报错:dmcss startup failed
正文
后台服务的方式启动了监视器,如何查看集群中各节点的状态
【问题解决】
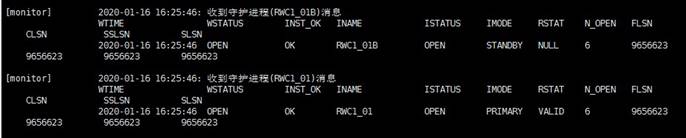
如果设置的是确认监视器(确认监视器只能启动一个)并且已经启动了,那么可以配置一个非确认监视器进行查看各节点状态,使用 ./dmmonitor /opt/dmdbms/bin/dmmonitor.ini 命令进行查看,结果如图所示:
监视器的配置方法如下(可根据需求进行修改参数值):
MON_DW_CONFIRM = 0 #为 0 是非确认监视器,为 1 是确认监视器
MON_LOG_PATH = ../log #监视器日志文件存放路径
MON_LOG_INTERVAL = 60 #每隔 60s 定时记录系统信息到日志文件
MON_LOG_FILE_SIZE = 512 #单位 MB,范围 1~2048 MB
MON_LOG_SPACE_LIMIT = 2048 #日志文件总占用 2048 MB
[GRWC1_01]
MON_INST_OGUID = 45331 #组 GRWC1_01 的唯一 OGUID 值
MON_DW_IP = 192.168.1.1:5436 #IP 对应 MAL_HOST,PORT 对应 MAL_DW_PORT
MON_DW_IP = 192.168.1.2:5436
实例各字段信息
| 命令 | 含义 |
|---|---|
| CLSN | 系统当前 LSN,指当前数据库最新产生的 LSN 值。 |
| SSLSN | 备库收到的主库发送过来日志的次大 LSN,主库的 SSLSN 和 CLSN 相等。 |
| SLSN | 备库收到的主库发送过来日志的最大 LSN,主库的 SLSN 和 CLSN 相等。 |
| INST_OK | 守护进程认定的实例状态,OK 或 Error。 |
| INAME | 实例名称。 |
| ISTATUS | 数据库实例状态,包括 Startup/After/Redo/Mount/Open/Suspend/Shutdown 这几种状态。 |
| IMODE | 数据库实例模式,包括 Normal/Primary/Standby 这三种模式。 |
| N_OPEN | 表示实例的 Open 次数,主库每 Open 一次,该值对应加 1,并产生日志同步到备库重做,主备库数据一致的情况下,N_OPEN 数值也应该一致。 |
| FLSN | 文件 LSN,指已经写入联机日志文件的最大 LSN 值。 |
| RSTAT | 此字段对备库有效,表示主库到备库的归档状态,可能为 Valid/Invalid/Unknown,对于本地守护类型的备库,此字段为 NULL,对于主库本身,此字段值为 Valid。该字段值要从备库对应的主库实例上取,如果当前没有活动主库或者备库无法确认对应的主库,则该字段显示为 Unknown。 |
达梦共享集群是采用裸设备还是共享文件系统?有什么配置要求
【问题解决】
达梦采用自己开发的 ASM 文件管理系统,ASM 是基于裸设备的,也可以支持裸设备部署。
配置要求:
物理存储需要映射到 2 个数据库服务器上,且支持双写。存储是用阵列,不是走的 nfs,gfs 之类的网络存储,所以不需要第三台服务器,支持不同的存储设备,如 SAN 存储等。好建 vg_lv,然后通过多路径映射。
网络方面要求双网卡,一般建议是 4 口,做双口绑定。配置心跳网 IP 和业务网 IP。
启动主备集群时数据库一直处于 mount 状态
【问题描述】
启动主备集群后通过 disql 登录主库数据库时提示“主库库处于配置状态”,通过 disql 登录备库提示“备库处于配置状态”,主备库都无法执行建表、插入数据、查询数据等数据库基本操作命令。通过登录监视查看发现主备数据库实例状态(ISTATUS)为 mount 状态。
【问题分析】
主备数据库一直处于 mount 状态,可能是由于防火墙问题,网络问题,LSN 不一致,数据库魔数相同,key 文件不支持集群使用等问题导致。可以通过查看数据库实例日志和守护进程日志详细分析数据库状态为 mount 的原因。
【问题解决】
- 查看防火墙是否关闭。
---查看防火墙是否关闭
--1、查看防火墙状态
[root@localhost dmdba]# systemctl status firewalld
如下截图显示表示防火墙已关闭。
--如果防火墙未关闭需要关闭防火墙
---关闭防火墙
[root@localhost dmdba]#systemctl stop firewalld
--禁止防火墙开机自启
[root@localhost dmdba]#systemctl disable firewalld
2.检查主备机器检查心跳网络及端口是否互通。
ping ip
--出现消息打印表示网络通畅
telnet IP 端口
--例如出现如下显示表示网络端口互通
[root@dmdba]# telnet 10.10.10.1 5235
Trying 10.10.10.1...
Connected to 10.10.10.1.
Escape character is '^]'.
Connection closed by foreign host.
若因网络问题导致主备集群启动后数据库一直处于 mount 状态,请联系有关方面检查并恢复网络通信。
- 通过监视器查看守护进程状态是否正常。
正常情况下守护进程状态 WCTLSTAT 为 VALID、WSTATUS 为 OPEN,LSN 相近。进入数据库安装目录下的 bin 目录通过以下命令启动监视器查看守护进程状态 WCTLSTAT 是否为 VALID、WSTATUS 是否为 OPEN 及 LSN 是否一致或者相差过大。
./dmmonitor dmmonitor.ini
- 检查主备数据库魔数是否一致,主备数据库魔数应该保持不一致。
若因主备集群数据库魔数问题导致集群启动后数据库一直处于 mount 状态,请及时联系达梦数据库技术支持工程师解决。
V$RLOG 视图可以显示日志的总体信息。通过该视图可以了解系统当前日志事务号 LSN 的情况、归档日志情况、检查点的执行情况等。
--主备数据库都通过 v$rlog 视图查看 LSN 和魔数
select * from v$rlog;
--DB_MAGIC为数据库魔数,主备不一致;PMNT_MAGIC 为永久魔数主备数据库一致,LSN主备相近或一致。
- 检查数据库所用的 key 是否正确支持集群使用。
通过以下命令可以查询到 key 的授权信息,其中参数 CLUSTER_TYPE 规定了 key 授权使用的集群类型,格式为字符串“XXXX”,每一位上 0 表示禁止,1 表示授权使用第 1 个字符:表示数据守护;第 2 个字符:表示 MPP;第 3 个字符:表示读写分离;第 4 个字符:表示 DSC。例如,“0010” 表示授权该可作为读写分离集群的节点使用。
--主备数据库都需要确认key授权信息。
select * from SYS."V$LICENSE"
如下 key 表示支持数据守护集群、MPP 集群、读写分离集群、DSC 集群。
如果 key 授权中显示不支持集群使用需联系达梦商务(400 991 6599 转 1 号商务线)申请对应授权集群使用的 key 来替换旧 key。key 替换步骤如下:
--主备数据库都需要替换新key
--1、进入达梦数据库安装目录的bin 目录。
--2、将旧的dm.key 重命名为old.key,拷贝新的dm.key到 达梦数据库安装目录的bin 目录下。
mv dm.key old.key
--3、使用 系统管理员用户 登录数据库,执行以下命令。
SP_LOAD_LIC_INFO();
--4、执行以下命令检查新的 key 是否已生效。
select * from v$license;
读写分离集群部署时正常,但重启了数据库服务后,导入数据后,发现读库无数据
【问题分析】
主要从以下几点进行排查:
- 启动监视器查看集群节点的状态;
- 使用 tip 命令打印当前守护系统的运行状态;
- 检查防火墙问题,特别是要注意是否设置了防火墙永久关闭。
DSC 环境中数据库正常运行,但通过 DmServiceDsc1 status 获取不到数据库运行状态
【问题描述】
数据库实例正常,但通过 DmServiceDsc1 status 查取不到数据库状态:

【问题解决】
查看数据库版本为:1-2-18-21.06.07-141116-10013-SEC Pack2
检查 DSC 集群 dmdcr.ini 文件的配置,如下:

dmdcr.ini 文件格式需要按以下要求修改:
- dm.ini 不需要写“path=”;
- DCR_INI 必须为大写。
修改后的 dmdcr.ini 文件如下图所示:

重新启动集群,重新注册服务,即可通过 DmServiceDsc1 status 获取数据库状态。
搭建 mpp 主备时,如何使用 MPP 类型为 LOCAL 方式设置 OGUID 值
【问题解决】
在连接时添加扩展选项 mpp_type,例如:
./disql SYSDBA/*****@192.168.10.21:5236#"{mpp_type=local}"
创建好主备集群后,备机无法连接
【问题描述】
创建好主备集群并配置 dm_svc.conf 文件后,在登录备机时发现通过服务名或者 IP 都无法连接到备机。
【问题分析】
该故障是在配置了 dm_svc.conf 文件之后产生,可能与 dm_svc.conf 文件的配置方式有关,如配置了 LOGIN_MODE=(1) 表示只连主库。
【问题解决】
考虑是 dm_svc.conf 文件 LOGIN_MODE 参数配置问题。dm_svc.conf 配置文件的内容分为全局配置区和服务配置区。全局配置区在前,服务配置区在后,以“[服务名]”开头,可配置除服务名外的所有配置项。服务配置区中的配置优先级高于全局配置区。以下介绍 dm_svc.conf 文件 LOGIN_MODE 参数不同配置时的登录情况:
一、当 dm_svc.conf 的参数 LOGIN_MODE=(1) 全局配置时,内容如下:
[root@dmdb01 ~]# cat /etc/dm_svc.conf
###全局配置区
DMDW=(10.1.1.1:5236,10.1.1.2:5236)
TIME_ZONE=(+480) #表示+8:00 时区
LOGIN_ENCRYPT=(0)
DIRECT=(Y)
LANGUAGE=(cn)
LOGIN_MODE=(1) #只连主库
不同方式登录如下:
- 利用 ./disql 连数据库时
---用./disql 连接IP登备库时。
. [dmdba@dmdb02:/home/dmdba/dmdbms/bin]$./disql SYSDBA/*****@10.1.1.2
报错:[-70019]:没有匹配的可登陆服务器。
---用./disql 连接服务名登录时。
[dmdba@dmdb02:/home/dmdba/dmdbms/bin]$./disql SYSDBA/*****@DMDW
登录成功:服务器[10.1.1.1:5236]:处于主库打开状态。
- 利用管理工具连数据库时
(1) 用达梦管理工具连接备库 IP 时,登录失败。
(2) 用达梦管理工具连接服务名登录时,连接成功,处于主机模式。
二、当 dm_svc.conf 的参数 LOGIN_MODE=(1) 局部配置时,内容如下:
[root@dmdb01 ~]# cat /etc/dm_svc.conf
### 全局配置区
DMDW=(10.1.1.1:5236,10.1.1.2:5236)
TIME_ZONE=(+480) #表示+8:00 时区
LOGIN_ENCRYPT=(0)
DIRECT=(Y)
LANGUAGE=(cn)
[DMDW]#局部配置
LOGIN_MODE=(1) #只连主库
不同方式登录如下:
- 利用 ./disql 连数据库时
---用./disql 连接 IP 登备库时
[dmdba@dmdb02:/home/dmdba/dmdbms/bin]$./disql SYSDBA/*****@10.1.1.2
登录成功,服务器[10.1.1.2 :5236]:处于备库打开状态。
---用./disql 连接服务名登录时。
[dmdba@dmdb01:/home/dmdba/dmdbms/bin]$./disql SYSDBA/*****@DMDW
登录成功,服务器[10.1.1.1:5236]:处于主库打开状态
- 利用管理工具连数据库时
(1) 用达梦管理工具连接备库 IP 时,连接成功,处于备机模式;
(2) 用达梦管理工具连接服务名登录时,连接成功,处于主机模式。
总结 :
1.当在全局配置区配置 LOGIN_MODE=(1) 时,用 IP 登陆备库时拒绝连接,而连接服务名时则会连接到主库。
2.当在局部配置区配置 LOGIN_MODE=(1) 时,用 IP 登录备库可行,而连接服务名时也会连接到主机。
3.一般情况下建议在局部配置 LOGIN_MODE,不建议在全局配置 LOGIN_MODE。
如果系统管理员需要登录备机进行相关操作可以修改 dm_svc.conf 的内容,重启客户端重新登录备库。在完成相关操作后注意将 dm_svc.conf 文件内容改回,防止人为的备库误操作对集群造成破坏。
注意当修改 dm_svc.conf 内容后,需要重启客户端,修改的配置才能生效。
两套主备集群如何共用一台监视器
【问题解决】
1.两套主备集群如果要共用一台监视器,要求主备守护组名和主备 OGUID 均相同。
2.当两台主备共用一台监视器,但守护组名不一样,OGUID 相同时,会出现报错:无法在不同组中配置相同的 OGUID 值。如下图所示:

3.当主备守护组名不一样和主备 OGUID 不同时,也会报错,监视器一直刷新报错的数据库信息。
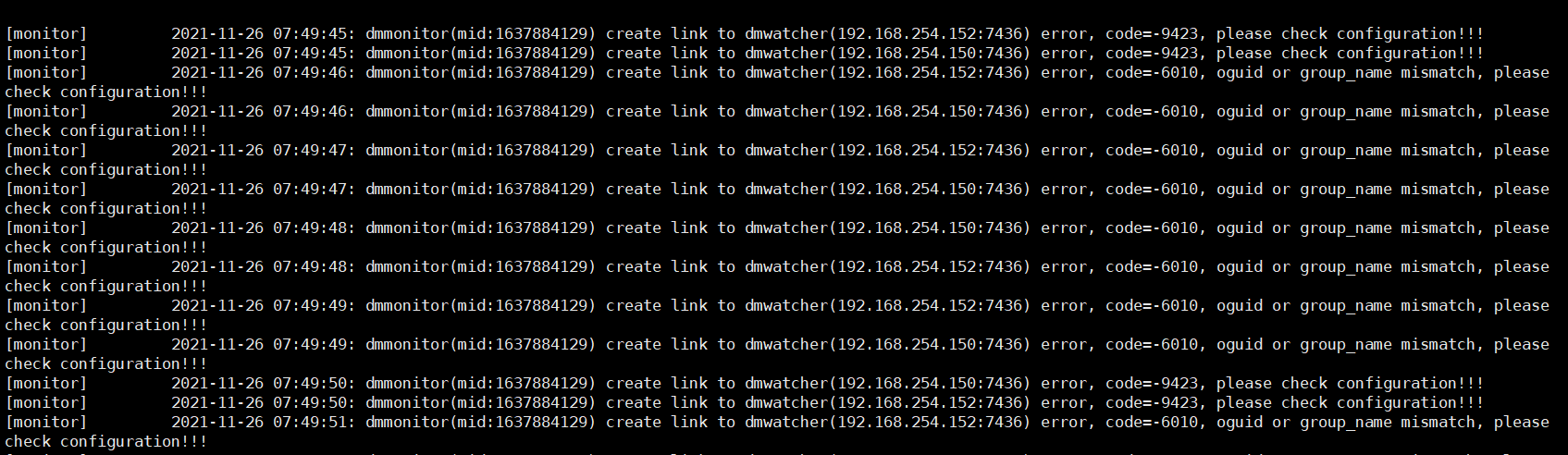
因此,当两套主备主备守护组名和主备 OGUID 不同时,不能共用一个 monitor.ini 文件,但可以在同一台机器配置两个 monitor.ini 文件。
初始化实例时报错 create rlog file +DMLOG/log/DSC1_log02.log failed, code: -7013.
【问题描述】
搭建 DSC 集群时,执行初始化语句之后报错,报错截图如下:

【问题解决】
出现该报错考虑是否是 log_size 设置过大导致,将 log_size 的值调小后,重新运行初始化语句。
MPP 登录查询只有一个实例
【问题描述】
普通 MPP 集群上登录其中一个节点,执行如下语句查询实例时,发现查询结果只显示一个实例。
select * from v$instance;
服务器[LOCALHOST:5236]:处于普通打开状态
登录使用时间 : 5.789(ms)
SQL> select instance_name from v$instance;
行号 INSTANCE_NAME
---------- -------------
1 DMMPP1
【问题分析】
正常情况下 MPP 中登录其中一个节点,执行如下语句查询实例时,应显示集群中所有节点对应的实例。
select * from v$instance;
服务器[LOCALHOST:5236]:处于普通打开状态
登录使用时间 : 5.789(ms)
SQL> select instance_name from v$instance;
行号 INSTANCE_NAME
---------- -------------
1 DMMPP1
2 DMMPP2
若出现只能查询到当前节点对应实例的问题,则考虑可能是集群通信出现问题,应检查所有 MPP 节点的 dm.ini 配置文件中的 MAL_INI 参数是否为 1,如果不是 1 则修改为 1。
【问题解决】
检查所有 MPP 节点的 dm.ini 配置文件中的 MAL_INI 参数是否为 1。如果参数 MAL_INI 不为 1 时,调整该参数值为 1,重启数据库即可。
cd /dm/dmdata/dmmpp/
vim dm.ini
##修改 MAL_INI 和 MPP_INI 的值为 1
MAL_INI = 1 #dmmal.ini
MPP_INI = 1 #dmmpp.ini
MPP 集群启动服务报错:MAL sys initialization failed
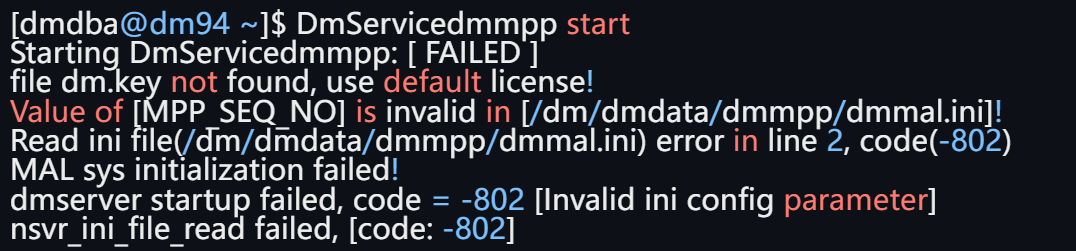
【问题描述】
MPP 集群启动服务报错如下图:
【问题分析】
根据报错信息:“Value of [MPP_SEQ_NO] is invalid [/dm/dmdata/dmmpp/dmmal.ini]! Reade ini file(/dm/dmdata/dmmpp/dmmal.ini) error in line 2,code(-802)”可以判断此报错可能是由于 dmmal.ini 配置文件错误导致。
【问题解决】
- 根据报错信息,检查 dmmal.ini 文件配置,修正 dmmal.ini 文件。
cd /dm/dmdata/dmmpp
vim dmmal.ini
##如下配置信息请根据实际情况配置检查修改正确
MAL_CHECK_INTERVAL = 60 #MAL 链路检测时间间隔
MAL_CONN_FAIL_INTERVAL = 60 #判定 MAL 链路断开的时间
[MAL_INST1]
MAL_INST_NAME = EP01 #实例名,和 dm.ini 中的 INSTANCE_NAME 一致
MAL_HOST = 192.168.131.159 #MAL 系统监听 TCP 连接的 IP 地址
MAL_PORT = 5337 #MAL 系统监听 TCP 连接的端口
MAL_INST_HOST = 192.168.131.120 #实例的对外服务 IP 地址
MAL_INST_PORT = 15236 #实例的对外服务端口,和 dm.ini 中的 PORT_NUM 一致
[MAL_INST2]
MAL_INST_NAME = EP02
MAL_HOST = 192.168.131.169
MAL_PORT = 5337
MAL_INST_HOST = 192.168.131.121
MAL_INST_PORT = 15236
- 重启数据库
[dmdba@dm94 ~]$ DmServicedmmpp start
Starting DmServicedmmpp: [ OK ]
创建 SOCKET 连接失败
情景一:在 DSC 集群中配置 dm_svc.conf 文件后,通过服务名字符串的方式登录数据库提示报错:“创建 SOCKET 连接失败”。
【问题描述】
disql 中通过服务名字符串的方式登录数据库报错:“comm_inet_server_connect_port cannot get the address information, servername is DSCDW1, port is 5236.[-70028]:创建 SOCKET 连接失败.”
完整报错如下:
[dmdba@ bin]$ ./disql SYSDBA/*****@DSCDW1
comm_inet_server_connect_port cannot get the address information, servername is DSCDW1, port is 5236.
[-70028]:创建 SOCKET 连接失败.
dm_svc.conf 中配置如下:
TIME_ZONE=(+480)
LANGUAGE=(cn)
DW1=(192.168.146.21:5236,192.168.146.22:5236)
[DW1]
LOGIN_MODE=(1)
SWITCH_TIMES=(300)
SWITCH_INTERVAL=(200)
DSCDW1=(192.168.146.11:5236,192.168.146.12:5236)
[DSCDW1]
LOGIN_MODE=(1)
SWITCH_TIMES=(60)
SWITCH_INTERVAL=(1000)
EP_SELECTOR=(1)
AUTO_RECONNECT=(1)
【问题解决】
dm_svc.conf 中服务名的全局配置必须在"[服务名]"的服务配置(局部变量)之前,存在多个服务名的情况下,也必须遵循。比如多个服务名 DW1、DSCDW1,那么 DW1、DSCDW1 服务名的配置信息必须在所有服务名配置[DW1]、[DSCDW1] 之前,正确的 dm_svc.conf 如下:
[dmdba@ ~]$ cat /etc/dm_svc.conf
TIME_ZONE=(+480)
LANGUAGE=(cn)DW1=(192.168.146.21:5236,192.168.146.22:5236)
DSCDW1=(192.168.146.11:5236,192.168.146.12:5236)
[DW1]
LOGIN_MODE=(1)
SWITCH_TIMES=(300)
SWITCH_INTERVAL=(200)
[DSCDW1]
LOGIN_MODE=(1)
SWITCH_TIMES=(60)
SWITCH_INTERVAL=(1000)
EP_SELECTOR=(1)
AUTO_RECONNECT=(1)
情景二:在 MPP 集群中在客户端主机上配置 dm_svc.conf 文件后通过服务名字符串的方式登录数据库提示报错:“创建 SOCKET 连接失败”。
【问题描述】
dm8 客户端主机上配置 dm_svc.conf 文件使用服务名连接失败报错 “comm_inet_server_connect_port cannot get the address information, servername is DMMPP, port is 5236.[-70028]:创建 SOCKET 连接失败.”,配置内容如下:
使用服务名连接失败,使用 IP 连接成功。

【问题解决】
在客户端主机上需要配置 dm_svc.conf 文件时候,需要将 LOGIN_MODE 参数注释掉,改为以下配置即可,否则导致无法使用服务名连接数据库。

LOGIN_MODE 参数说明
| 参数 | 缺省值 | 描述 |
|---|---|---|
| LOGIN_MODE | 4 | 指定优先登录的服务器模式。 0:优先连接 PRIMARY 模式的库,NORMAL 模式次之,最后选择 STANTBY 模式;1:只连接主库;2:只连接备库;3:优先连接 STANDBY 模式的库, PRIMARY 模式次之,最后选择 NORMAL 模式;4:优先连接 NORMAL 模式 的库,PRIMARY 模式次之,最后选择 STANDBY 模式。 |
DSC 集群配置都正确,但启动集群时报错
【问题描述】
DSC 集群配置、软件环境、硬件环境以及网络都正确,但是启动集群的时候报一些莫名的错误。例如:ASM 磁盘无法连接、实例启动提示 dm.ctl 控制文件错误等。
【问题解决】
出现此问题可查看 DCR 中是否将节点标记成了故障,一旦标记后集群会认为该节点为故障节点无法正常启动。需要手动执行相关命令清除故障标记信息后方能正常启动。
查看 DCR 中节点是否故障:
---到 bin 目录下,进入 ASM 命令行模式
./dmasmcmd
---从asm磁盘中导出配置(这里的/dev/raw/raw1 为当前设备实际的 DCR 磁盘设备节点路径)
export dcrdisk ‘/dev/raw/raw1’ to ‘/tmp/dmdcr_cfg.ini’
---退出命令行模式
exit
---查看导出的配置信息
cat /tmp/dmdcr_cfg.ini
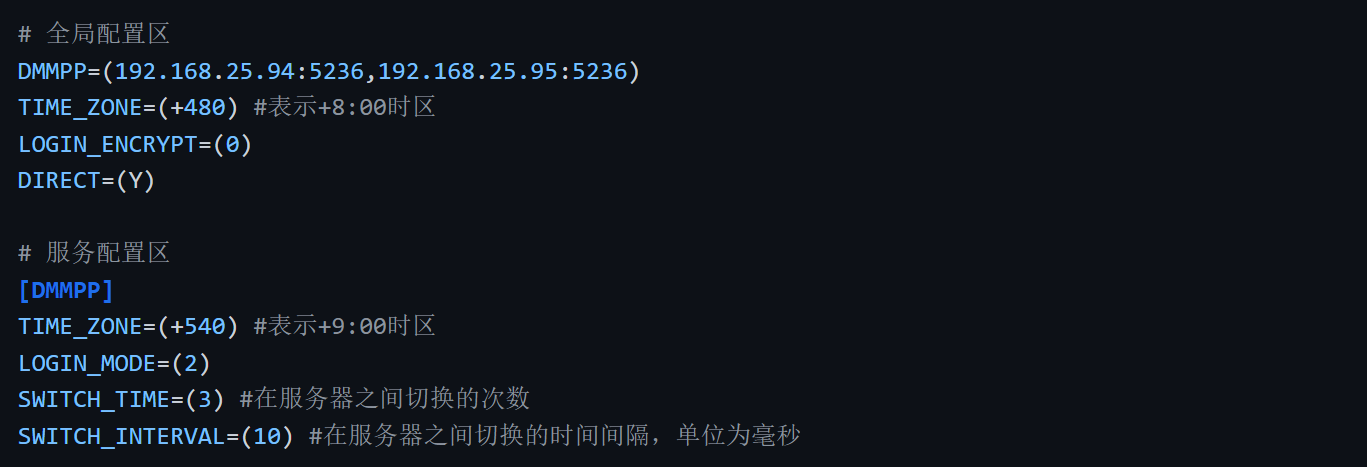
dmdcr_cfg.ini 文件中 DCR_GRP_N_ERR_EP 为故障节点个数,DCR_GRP_ERR_EP_ARR 为故障节点号。下图显示 ASM 和实例都标记了故障。我们需要手动清除后才能正常启动 DSC 集群。
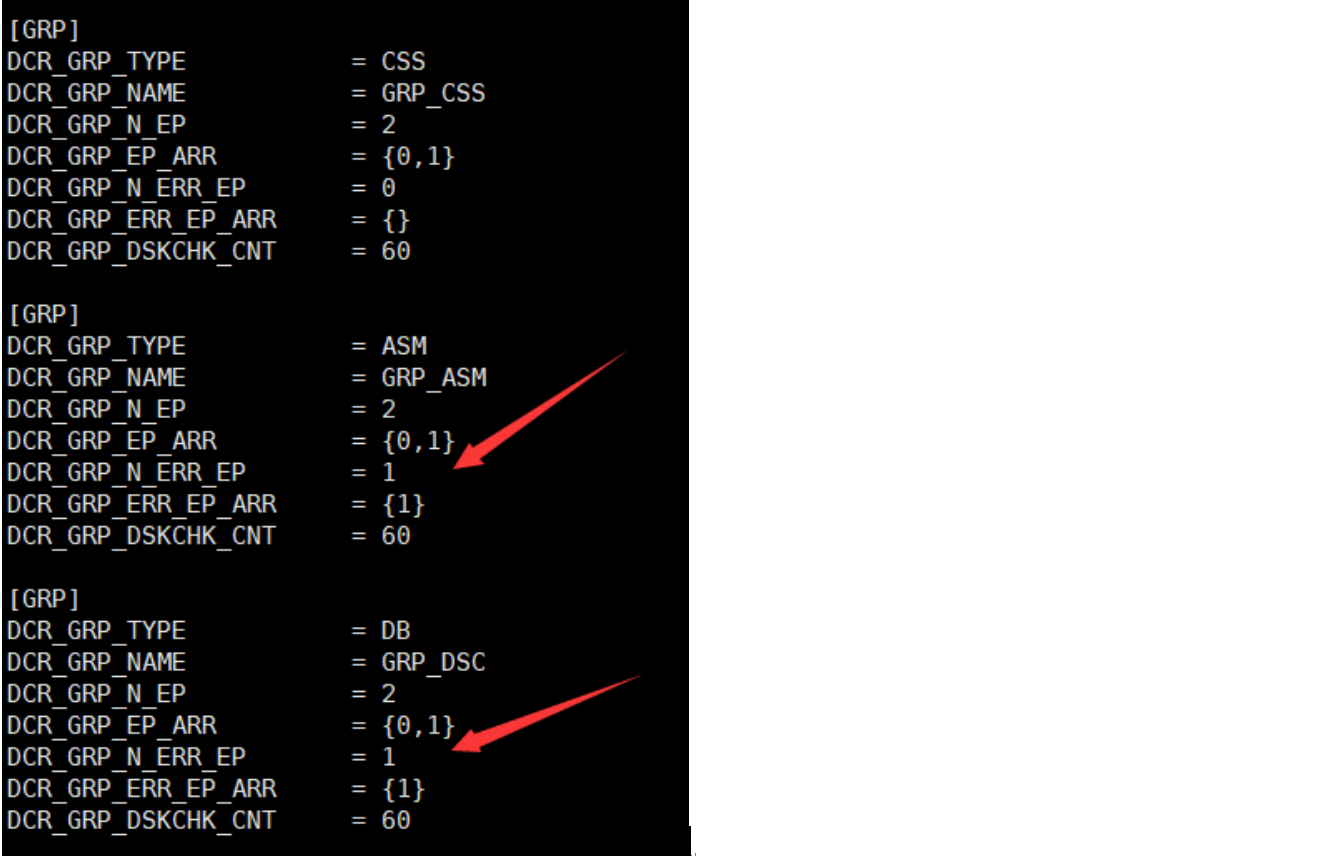
清除故障节点信息:
---到 bin 目录下进入 ASM 命令行模式
./dmasmcmd
---执行清除命令,清除 ASM
clear dcrdisk err_ep_arr ‘/dev/raw/raw1’ ‘GRP_ASM’
---清除 DSC
clear dcrdisk err_ep_arr ‘/dev/raw/raw1’ ‘GRP_DSC’
此时注意清除时候需要停止相关 ASM 和 CSS 以及实例服务。否则会提示当前正在使用无法清除。这里的 GRP_ASM 和 GRP_DSC 为 DCR_GRP_NAME 名称。
看到 userd time 表示执行清除成功。如果需要确认,可以导出来查看,只要 DCR_GRP_N_ERR_EP 为 0 即可。此时我们重新启动即可成功。
总结:导致故障标记的大致原因可分为以下情况:
1、集群自身故障,包括实例故障,网络故障等;
2、搭建过程中错误的配置、错误的操作流程和命令导致启动报错也可能会被标记;
3、停止 DSC 集群时候建议使用 shutdown immediate;来关闭数据库节点,使用 kill 或者注册的启停脚本关闭可能也会导致标记。
DEM 部署达梦数据守护集群提示:没有到主机的路由
【问题描述】
报错截图如下:
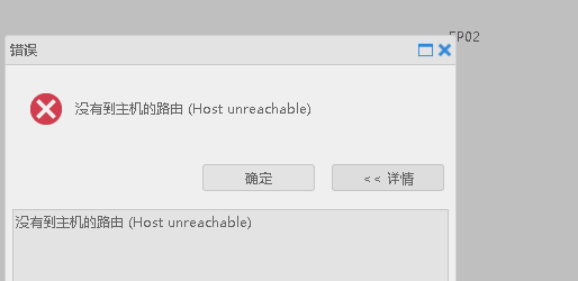
【问题解决】
出现该报错是由于主备机端口不通,检查并关闭主备机的防火墙。
---查看防火墙状态
[root@~]# systemctl status firewalld
---关闭防火墙
[root@~]# systemctl stop firewalld
--关闭防火墙开机自启
[root@~]# systemctl disable firewalld
注意:配置数据守护集群建议关闭防火墙,若不能关闭防火墙请根据端口规划开放相应端口。
主备集群中 dmwatcher 服务报错:Segmentation fault (core dumped)
【问题描述】
主备集群安装完成后启动 dmmonitor 服务,dmwatcher 服务会关闭,提示 Segmentation fault(core dumped);
[dmdba@04 bin]$ · /dmwatcher /data/dmdata/DAMENG/dmwatcher.ini
DMWATCHERC4 · 0 ]
DMWATCHERC4 ] IS R EADY
Segmentation fautt (core dumped )
【问题解决】
出现该报错可能是因为主备数据库版本和监视器所在数据库版本不一致导致,建议将主备和监视器所在数据库版本更换一致。
MPP 变更表结构后,查询表报错:site info mismatch
【问题分析】
由于 MPP 架构属于分布式架构,任务通过登录节点分发到集群中的其他节点,如果集群中其他节点执行出现错误,则会导致部分节点表结构变更未执行,造成不同节点表结构不一致,最终出现报错:site info mismatch。
【问题解决】
分别登录 MPP 集群中的每个节点进行检查,在存在表结构字段缺失的 MPP 节点中添加相应字段。
- 进入数据库安装目录下的 bin 目录下通过 disql 命令本地登录。
[dmdba@localhost bin]$ ./disql username/passwd#{mpp_type=local}
- 依次检查每个节点相应的表结构,并添加表结构中缺少的字段。local 登录默认不允许执行 ddl 语句,执行以下命令可允许执行 ddl 语句。
SP_SET_SESSION_LOCAL_TYPE (1);
- 所有 MPP 节点相应表结构修改完成后,全局登录进行验证,能够正常查询,即代表所有 MPP 节点相应表结构修改成功。
SP_SET_SESSION_LOCAL_TYPE()函数:MPP 下本地登录时,设置本会话上是否允许 DDL 操作,本地登录默认不允许 DDL 操作。函数值为 1 时表示允许当前本地会话执行 DDL 操作,为 0 时则不允许。
安装 DSC 集群时报错:”[code : -11041] ASM connection exception“
【问题描述】
在安装 DSC 集群过程中,当使用 dmasmtool 工具创建 asm 磁盘组时报错:"[code : -11041] ASM connection exception"。
[dmdba@107 ~] $ /home/dmdba/dmdbms/bi n/dmasmtool DCR_INI=/home/dmdba/dmdbms/dscconfig/dmdcr. ini
DMASMTOOL V8
[code:-11041 ] ASM connection exception
【问题分析】
该错误是因为 ASM 配置文件的心跳 IP 地址写错导致,修改为正确的 IP 地址即可。
【问题解决】
例如: MAL_HOST 的心跳 IP 地址配置成错误的 IP 地址。
解决步骤:
- 查看 asm 服务是否启动。
通过操作系统命令,确认 asm 服务已启动。
ps -ef | grep dmasmsvr
- 看 asm 配置文件是否正确。
通过检查配置文件 dmasvrmal.ini 发现 MAL_HOST 的心跳 ip 地址配置错误,正确地址应该为 192.168.1.107。
[dmdba@107 ~] $ cat /home/dmdba/dmdbms/dscconfig/dmasvrmal.ini
- 修改 MAL_HOST 的心跳 IP 为正确的 IP 192.168.1.107。
- 重启 asm 服务。
- 再次使用 dmasmtool 工具创建 asm 磁盘组即可成功。
注意在 dsc 配置过程中,要确保基础配置文件正确无误。
DSC 集群启动 asm 服务报错:"[code: 12000]实例已经启动"
【问题描述】
部署 DSC 过程中第 2 节点启动 asm 服务时报错:”[code: 12000]实例已经启动“。
【问题分析】
该问题是由于 DSC 两个节点的 dmdcr.ini 文件中 DMDCR_SEQNO 配置成了一样的值导致。
【问题解决】
节点一:dmdcr.ini 文件中 DMDCR_SEQNO 需配置为 0。
[dmdba@~]# vi /dm/dmdbms/dsc_config/dmdcr.ini
DMDCR_PATH = /dev/dm/asm-dmdcr
DMDCR_MAL_PATH = /dm/dmdbms/dsc_config/DSC0/dmasvrmal.ini
DMDCR_SEQNO = 0
DMDCR_AUTO_OPEN_CHECK = 111
DMDCR_ASM_TRACE_LEVEL = 2
##DMDCR_ASM_RESTART_INTERVAL = 60 #CSS 认定 ASM 故障重启的时间
##DMDCR_ASM_STARTUP_CMD = /dm/dmdbms/dsc_config/DmAsmService_DSC0 start
##DMDCR_DB_RESTART_INTERVAL = 60 ##CSS 认定 DSC 故障重启的时间,设置为 0 不自动拉起
##DMDCR_DB_STARTUP_CMD = /dm/dmdbms/dsc_config/DmService_DSC0 start
节点二: dmdcr.ini 文件中 DMDCR_SEQNO 需配置为 1。
[dmdba@~]# vi /dm/dmdbms/dsc_config/dmdcr.ini
DMDCR_PATH = /dev/dm/asm-mpatha
DMDCR_MAL_PATH = /dm/dmdbms/dsc_config/DSC1/dmasvrmal.ini
DMDCR_SEQNO = 1
DMDCR_AUTO_OPEN_CHECK = 111
DMDCR_ASM_TRACE_LEVEL = 2
##DMDCR_ASM_RESTART_INTERVAL = 60
##DMDCR_ASM_STARTUP_CMD = /dm/dmdbms/dsc_config/DmAsmServiceDSC1 start
##DMDCR_DB_RESTART_INTERVAL = 60
##DMDCR_DB_STARTUP_CMD = /dm/dmdbms/dsc_config/DmServiceDSC1 start
更改完毕后重启 ASM 服务即可。
参数说明:
| 参数名 | 说明 |
|---|---|
| DMDCR_SEQNO | 记录当前节点序号(用来获取 ASM 登录信息) |
| DMDCR_PATH | 记录 DCR 磁盘路径 |
| DMDCR_MAL_PATH | 保存 dmmal.ini 配置文件的路径,仅对 dmasmsvr 有效 |
| DMDCR_AUTO_OPEN_CHECK | 指定时间内如果节点实例未启动,DMCSS 会自动将节点踢出集群环境,单 位 S,取值应大于等于 30s。不配置此参数时表示不启用此功能 |
| DMDCR_ASM_TRACE_LEVEL | 指定日志级别。 1:TRACE 级别; 2:WARN 级别; 3:ERROR 级别; 4:FATAL 级别。缺省为 1。 日志级别越低(参数值越小),输出的日志越详细。当设置日志级别为较 低级别时,兼容输出级别大的日志,如 WARN 级别也可输出 ERROR 级别 的日志。 |
更多详细内容参考数据库安装目录 doc 路径下《共享存储集群》使用手册。
读写分离集群应用启动异常
【问题描述】
读写分离集群配置心跳网络的情况下,jdbc 连接串不启用 rwSeparate 参数,应用启动正常,jdbc 连接串启用 rwSeparate 读写分离参数后,应用启动异常。
【问题分析】
这种情况一般是 MAL_INST_HOST 配置成了心跳 IP,并且心跳 IP 与业务 IP 是隔离的。可以通过开启 jdbc 日志来分析,具体开启方法为在连接串后面加上 &logLevel=all&logDir=D:\testlog 属性,在 D:\testlog 目录下会生成相关日志。不开启 rwSeparate 即为主备模式,分析日志可以发现,相比于主备模式,读写分离的连接过程会多两个方法:CMD_STMT_ALLOCATE 和 CMD_PREPARE,会启用内部计数器和分发器,来判断下一个发去哪里,这里分发使用的链路为 MAL_INST_HOST+MAL_INST_PORT,如果 MAL_INST_HOST 配置成了心跳 IP,并且与服务器不通,就会出现不能获取到数据库连接的情况,应用启动异常。
【问题解决】
排查 MAL_HOST,MAL_INST_HOST 配置是否正确,MAL_HOST 为心跳 IP,MAL_INST_HOST 为业务 IP。
DPC 集群启动 MP 日志报错:“can't find self config in mp.ini”
【问题描述】
DPC 集群 MP 多副本架构,MP 节点前台无法启动且无报错信息提示,如下:
C:\bigprogram\dmdbms\bin>dmserver.exe C:\bigprogram\dmdbms\data\dpc_data_3IDC\mp1_01\DAMENG\dm.ini dpc_mode=MP
file dm.key not found, use default license!
version info: develop
实例日志报错:
2023-08-04 12:28:44.457 [INFO] database P0000000872 T0000000000000021132 version info: develop
2023-08-04 12:28:44.460 [INFO] database P0000000872 T0000000000000021132 os_sema2_create_low, create mutex success, name:Global\DM$INNER164097472!
2023-08-04 12:28:44.464 [FATAL] database P0000000872 T0000000000000021132 can't find self config in mp.ini
2023-08-04 12:28:44.465 [FATAL] database P0000000872 T0000000000000021132 [for dem]SYSTEM SHUTDOWN ABORT.
2023-08-04 12:28:44.465 [FATAL] database P0000000872 T0000000000000021132 can't find self config in mp.ini
2023-08-04 12:28:44.465 [INFO] database P0000000872 T0000000000000021132 total 0 rfil opened!
【问题分析】
配置 mp.ini 配置文件时,对于 MP 多副本情况下,"[]" 中 MP 的名称必须要与具体 MP 实例的实例名保持一致。
【问题解决】
例如:三副本的 MP,实例名分别为 MP1_01、MP1_02、MP1_03,则 mp.ini 配置参考如下(端口根据实际情况配置,不冲突即可)。
[MP1_01]
mp_host = 127.0.0.1
mp_port = 9001
[MP1_02]
mp_host = 127.0.0.1
mp_port = 9002
[MP1_03]
mp_host = 127.0.0.1
mp_port = 9003
回滚表空间不足
【问题描述】
统计类型 sql 执行时间较长,UNDO_RETENTION 参数改大之后执行报错:“回滚表空间不足”。
【问题分析】
该报错是由于 UNDO_RETENTION 设置变大导致现有的回滚表空间无法存放 UNDO_RETENTION 所设置时间内的回滚段。
【问题解决】
若磁盘空间和可用内存充足,可以通过扩大回滚表空间解决该报错。
DSC 集群 CSS 启动报错:dmcss startup failed
【问题描述】
使用虚拟机搭建 DSC 集群时,启动 CSS 报错:dmcss startup failed。
共享磁盘的创建方式为:在一个虚拟机节点中创建一块新磁盘,然后在另外的虚拟机节点中关联此磁盘来作为共享磁盘,。
【问题分析】
出现此报错的原因是共享磁盘的配置方式存在问题。当使用虚拟机搭建 DSC 集群时,在其中一台机器中创建共享磁盘,然后再在第二台关联此磁盘,此方式配置可能导致 CSS 启动失败;
【问题解决】
重新创建共享磁盘。使用 vmware 的 vmware-vdiskmanager.exe 应用程序创建一块新的磁盘作为两台机器的共享磁盘,然后在两台虚拟机上分别关联此磁盘。
示例如下:创建一块 20G 的共享磁盘
- 打开 cmd 进入到虚拟机安装目录;
cd /d D:\Program Files (x86)\VMware\VMware Workstation
- 执行以下命令创建 20G 的共享磁盘;
.\vmware-vdiskmanager.exe -c -s 20G -a lsilogic -t 2 "D:\Program Files (x86)\VMware\CentOS 7.7(1)\SHARE.vmdk"
创建完成之后,可以在对应的目录中看到创建好的磁盘。
- 在虚拟机中添加共享磁盘。