本章节主要介绍达梦数据库数据导入导出常见问题,为用户提供 数据导入导出常见问题的分析和解决思路。除此之外,用户还可前往达梦技术社区参与更多问题讨论。
目录
- DM 只导出表结构不导出数据
- 使用 DTS 导出
- 使用 DMP 方式导出
- 使用 Disql 命令行方式导出
- 6092 数据大小已超过可支持范围
- 如何使用管理工具导入 SQL 数据
- DM 如何导出数据为 SQL 格式
- 将 Excel 数据导入 DM
- DM 如何导出 SQL 脚本/导出对象定义的 DDL 语句
- 导入 dmp 的正确方式
- 导入 dmp 文件时出现乱码、问号
- 导入 dmp 文件提示初始化参数不一致
- 高效的数据装载方式
- dmfldr 导出报错“获取表信息失败 锁超时”
- ArcGIS 使用 DM 导入导出 shp 数据
- 客户端工具上的导入导出功能,是灰色按钮不可用
- 导入 dmp 文件时提示报错“该工具不能解析此文件,请使用更高版本的工具”
- dexp 导入时报错:文件打开出错,请检查您的输入参数
- 导入的时候怎么修改模式名?
- 是否有批量生成 SQL 脚本的方法
- “导入”功能按钮是灰色的,不可以点击
- 导入报错:Error Code:-70013,转换失败
- 导入 dmp 文件,出现警告:无效的对象
- 达梦数据库数据导出,再导入到达梦报错:-3503 无效的函数参数
- 使用管理工具进行导入的时候提示警告:导入导出编码方式不一致,可能无法转换
- dimp 或者管理工具导入会报错:“[警告]Error Code:-70016,日期超出范围”
- 达梦数据库如何只导出表结构不导出数据
- 达梦 dmp 逻辑导入数据时报字符串截断
- 如何将 A 模式下的表导入到 B 模式
- 如何通过 dexp 导出指定表,或根据条件导出某一类的表(比如以 T 开头的表)
- 达梦数据库导出数据,再导入到另一个库报错:无法解析成员访问表达式
- dmfldr 命令载出时用 WHEN 进行条件过滤无效,SQL 参数应如何使用
- 跨模式导入失败:导入对象过程有错误,请检查参数后重新执行导入
- 逻辑导入导出报错:the table SYSDBA.STAT isnot exist or is the system object,check input ,please
- 使用 dimp 逻辑导入 dmp 数据文件,警告错误:Error Code:-6524,跨事务填充大字段,文件中的数据没有全部导入导表中
- 导入导出过程中,特殊字符如何转义
- 利用管理工具导出数据时报:[警告]Error Code:-70037,字符串不完整
- manager 管理工具导出功能不能使用,界面为灰色
- DM6 数据库迁移还原成功后,发现其缺失用户登录关联关系
- 从代码导入 exlce 表中的数据到数据库后,正常的数值变成了科学计数法
- DM 中 BLOB 字段存有图片,想要导出 EXCEL(图片以超链接形式)要怎么做?
- 管理工具普通用户导入导出报错:"Error Code:-2158,无效的 IP"
- 在 Windows 环境下使用 dexp 导出时报错:“导出模式错误”
- 导入报错"数据文件少列"和"出现数据转换错误"
- dmfldr 导出数据文件字段之间如何以 16 进制 ASCLL 码“0x02”方式进行分割
- dmfldr 自定义 SQL 功能导出结果集顺序与 SQL 查询出的结果集顺序不一致
- dmfldr 装载含有中文字段长度 8296 的数据文件失败
- 数据导出报错:“创建文件失败,文件空间已经耗尽”
- dimp 导入数据时报错:"无效的模式名"
- dexpdp 工具执行导出逻辑时,报错:“ [警告]Error Code:-6819,字符不完整”
- 使用管理工具导入 DMP 文件时报错:“拒绝访问”
- 导入数据时出现大量告警:“输入错误,请重新输入”
- dexp 逻辑导出如何拆分导出文件,dimp 逻辑导入如何导入拆分文件
- 使用 dimp 导入数据时,物化视图报错:import instance's VlEW objects : MV_XXX
- 使用快速装载的工具进行导入,在导入数据时报数据错误
- dexp 导出报错:指定数据文件大小,必须使用 %U 对名称进行自动扩展
- dmfldr 工具导入数据时报错:超过最大错误数(无效的大字段数据格式)
- 管理工具导出结果集报错
- 管理工具导出或导入时报错:"openssl lib load failed code! -115"
正文
DM 只导出表结构不导出数据
针对导出数据库表结构通常有 3 种方法:
使用 DTS 导出
打开 DTS 迁移工具,选择【DM-->SQL】并链接到数据库中,如下图所示:
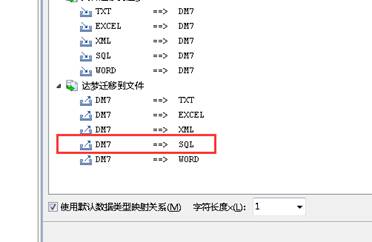
添加定义脚本,并选择【迁移范围】(仅迁移对象定义),如下图所示:
选择需要导出结构的表,如下图所示:
迁移完成,表结构已经导出,如下图所示:
DTS 同样可以将表结构迁移至其他数据库中或者从其他数据库迁移至 DM 数据库中。
使用 DMP 方式导出
打开 manager.exe,DM 管理工具链接至数据库中,如下图所示:

右键选择你想要导出的模式,点击【导出】,如下图所示:如下图所示:
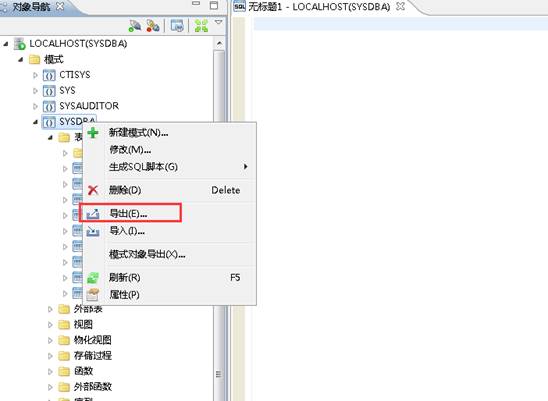
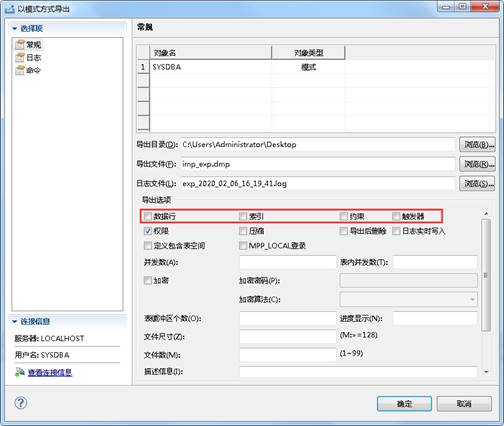
勾选掉数据行选项,点击【确定】完成导出,如下图所示:
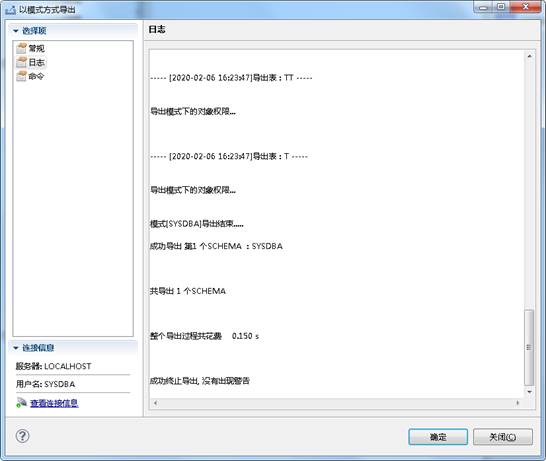
完成导出,包含表结构的 DMP 文件生成,如下图所示:
使用 Disql 命令行方式导出
参考《DM_dexp 和 dimp 使用手册》(手册位于数据库安装路径 /dmdbms/doc/special 文件夹下)。其中 dexp 的参数 ROWS :设置是否导出数据,可选参数。取值范围:Y/N。Y:导出数据,缺省值;N:不导出数据。只导出表结构不导出数据,可以将该参数设置为 ROWS=N 。
SELECT DBMS_METADATA.GET_DDL('TABLE',表名,模式名);//参考 DBMS_METADATA 系统包
CALL SP_TABLEDEF('模式名', '表名');//SQL 语句调用系统过程 SP_TABLEDEF
可以通过 SP_TABLEDEF 系统过程查看表的定义。
6092 数据大小已超过可支持范围
- 方法一
一般情况下,此问题由于实际数据超过了 DM 数据库支持的大小范围,重点分析被迁移数据的数字类型字段 (INT、BIGINT、NUMBER),找到造成引起报错的字段后,观察数据可以考虑将字段改为 BIGINT 或者 VARCHAR 字符字段以规避错误。
各数据类型范围详情可以参考《DM_SQL 语言使用手册》第一章 1.4.1 节内容(手册位于数据库安装路径 /dmdbms/doc 文件夹下)。
INTEGER 类型:-2147483648 (-2^31)~ +2147483647(2^31-1)。
BIGINT 类型: -9223372036854775808(-2^63)~9223372036854775807(2^63-1)。
- 方法二
默认 8 KB 的页大小情况下,字符类型无法创建超过 3900 长度的表。需要重新初始化数据库实例,对页大小进行调整。需要注意的是:这个限制长度只针对建表的情况,在定义变量的时候,可以不受这个限制长度的限制。
| 页大小 | 字符类型实际最大长度 |
|---|---|
| 4k | 1900 |
| 8k | 3900 |
| 16k | 8000 |
| 32k | 8188 |
两个建库参数有影响,一个字符集,一个“长度以字符为单位”。
比如 Oracle 中的 nvarchar2(50) 这个类型,表示该字段类型为 nvarchar2,长度为 50,不论英文、数字、中文都能存 50 个。在 DM 数据库中,如果长度以字符为单位这个参数建库的时候选了否,UNICODE 字符集,nvarchar2(50) 还是只能存 16 个中文。
- 方法三
在有表结构的基础上,将报错的表【启用超长记录】打开。
如何使用管理工具导入 SQL 数据
- 方法一
将 SQL 语句粘贴到查询窗口,然后执行。这种方式适合 SQL 不多的情况下使用,如果 SQL 比较多,比如几万条,那么在复制粘贴的时候就会受性能影响了,可能会导致管理工具卡死。
- 方法二
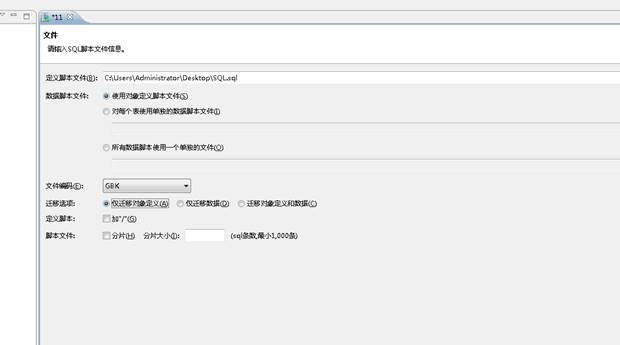
将 SQL 保存到 SQL 类型的文件中,然后用管理工具打开 SQL 文件,如下图所示:
这种方式也相对简单,但是如果文件大小不能超过 20 MB,当超过 20 MB 时会报 [文件过于庞大] 错误,如下图所示:

- 方法三
使用管理工具的【执行脚本】功能,如下图所示:

这种方式适合导入比较大的脚本,测试导入 3.42 GB 的 SQL 也是可以的,但还是不建议直接这样导入很大的 SQL,如果不能及时提交会使用大量的内存资源。
另外:如果要导入比较大的 SQL 还可以考虑使用迁移工具将数据 SQL 导入 DM 数据库,使用迁移工具还可以设置一次性提交的语句条数和缓存批次,这样可以提高数据导入的效率。

DM 如何导出数据为 SQL 格式
无论使用“管理工具”还是“迁移工具”都可以远程连接数据库进行操作,所以只要本机安装 DM 数据库客户端即可操作,不需要登录服务器本机操作。
- 使用管理工具
方法一:
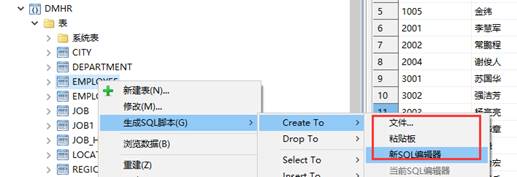
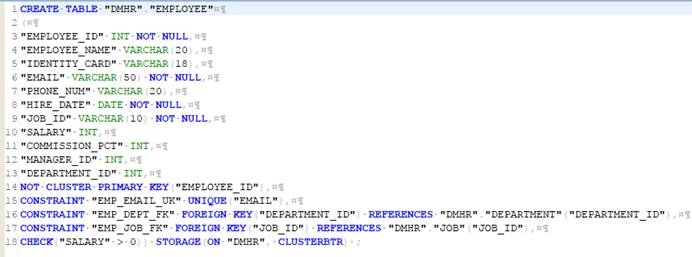
使用生成 SQL 脚本方式生成建表语句,并保存为 SQL 文件,或直接生成文件,如下图所示:
方法二:
查看表属性中的 DDL,复制语句并保存为 SQL 文件,如下图所示:

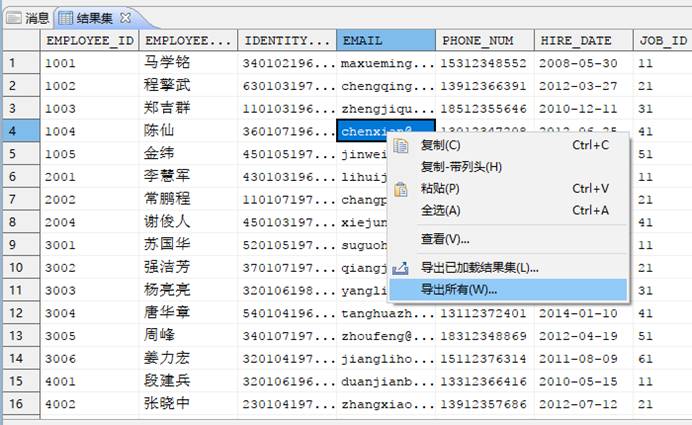
导出数据,此方法在数据量不大的情况下可以使用。查询出表数据,在结果中右键选择【导出所有】,选路径然后选要保存的类型为 SQL 并输入文件名。如下图所示:

方法三:
使用 DM 数据迁移工具 DTS。该方法适合导出比较大的表,如下图所示:

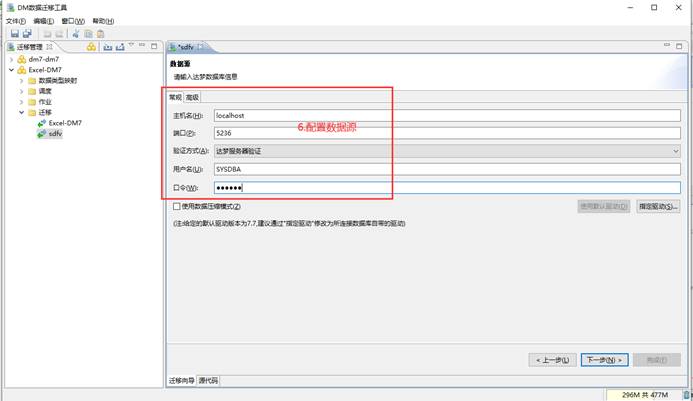

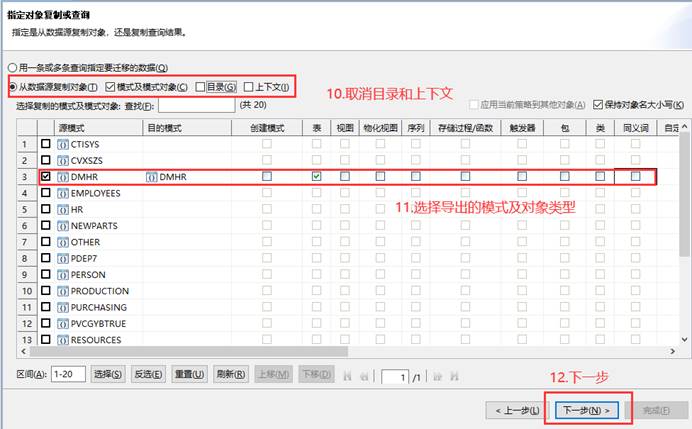
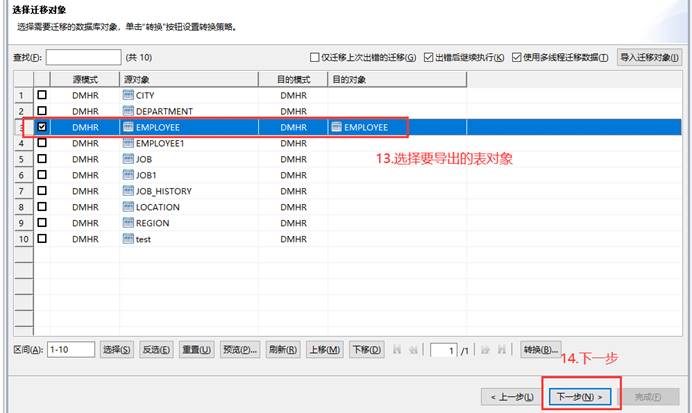
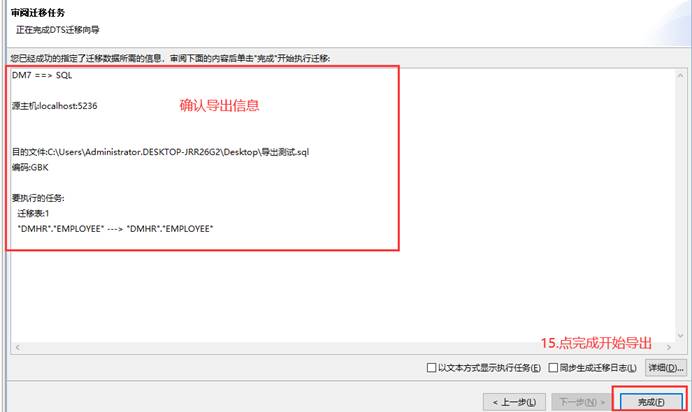
迁移过程和结束会显示迁移的情况,如有错误可以点击【查看日志】和【重新迁移出错对象】,有报错时在列表中也可以点击查看具体的报错信息。

将 Excel 数据导入 DM
DM 提供了两种方法导入 Excel 数据。
方法一: DTS 工具导入
使用 DM 数据迁移工具 DTS(以下简称“DTS”)可将不同数据或数据类型的文件数据导入到 DM 数据库中,其中 Excel 就可以使用迁移工具进行导入。
无论 Windows 或 Linux,在安装好 DM 数据库后,都会在安装后的 dmdbms/tool 目录下安装一系列的客户端工具,如 Windows 下迁移工具名称为 dts.exe,如下图所示:

如果试用图形化安装的 DM 数据库,同时会桌面或开始菜单生产一个【达梦数据库】的文件夹,可以在文件夹中快速的启动【DM 数据迁移工具】,如下图所示:
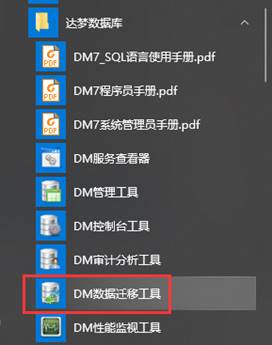
- 如何使用迁移工具导入 Excel
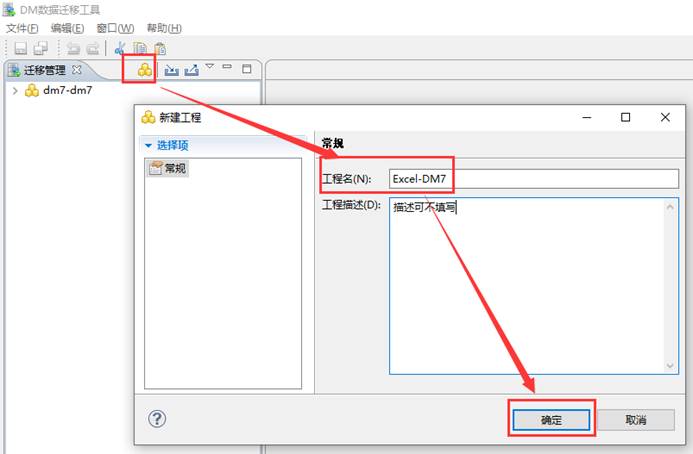
打开迁移工具,点击【新建工程】按钮,新建工程,如下图所示:
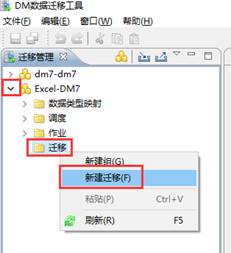
展开新建的工程,选择【迁移】-点击【新建迁移】,如下图所示:
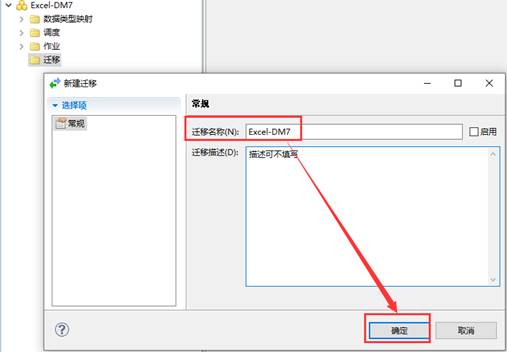
开始配置迁移(导入)Excel 数据,点击【下一步】,如下图所示:
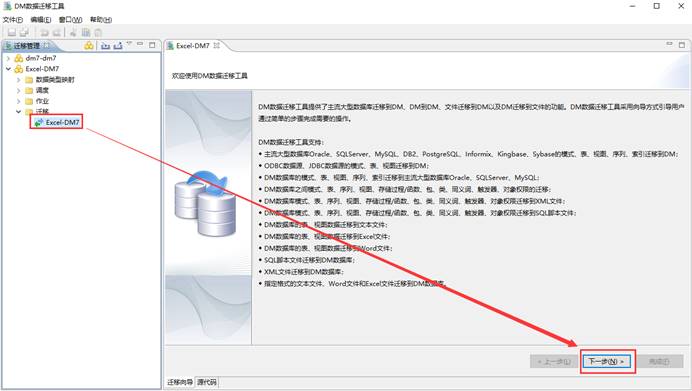
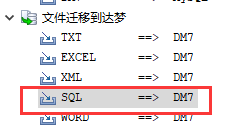
在列表中选择【文件迁移到达梦】中【Excel-->DM】,如下图所示:
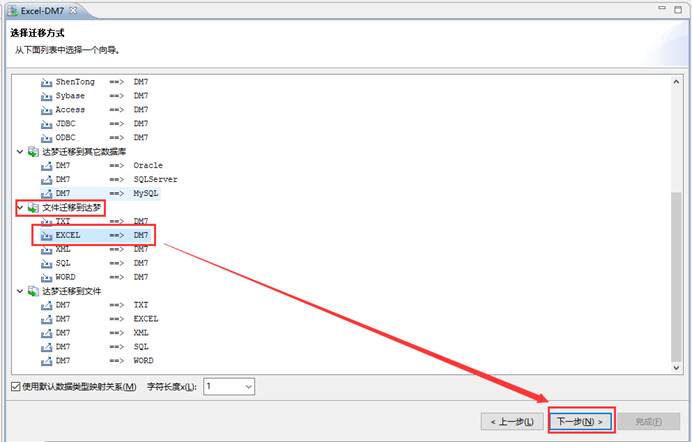
选择要导入的 Excel 文件,如下图所示:
注意:选择数据读取方式时,要考虑 Excel 文件首行是否为列名。
(1)如果 Excel 文件中第一行为列名,则选择“按照设定的数据格式读取”。
(2)如 Excel 文件中第一行不是列名,则选择“全部按字符集读取”,但是需要注意 Excel 文件中每列的数据要与表中的列一一对应,否则会报错。建议在 Excel 表中添加第一行作为列名。
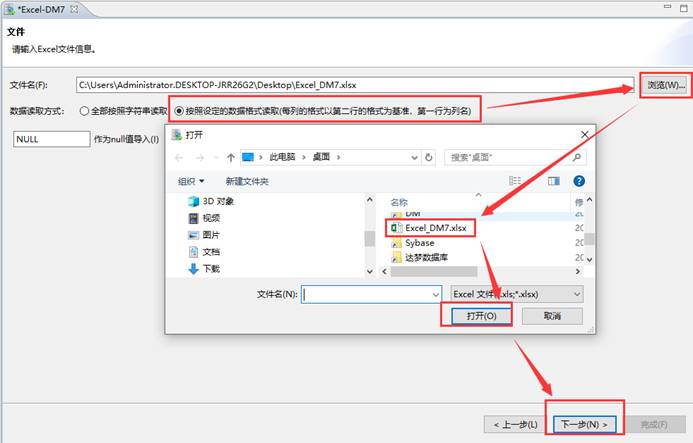
配置要导入的目的端数据库,如下图所示:
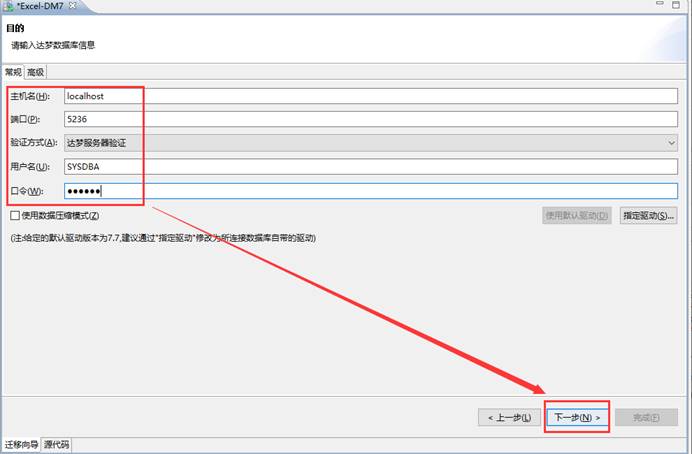
选择要导入到的模式,如下图所示:
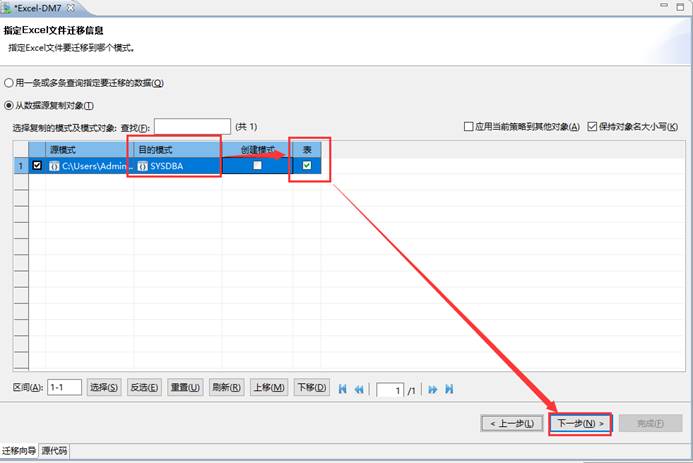
选择要导入的模式对应的目的表,如果有没有新建,可输入表名,导入过程中会自动创建相应的表,如下图所示:
需要注意:
(1)如果 Excel 中第一行作为列名,列名大小写与数据库表中列名大小写完全相同,则迁移工具会自动匹配相同列名。可以在右下方"转换"--"列映射选项"查看;
(2)如果 Excel 中第一行作为列名,列名大小写与数据库表中列名大小写不相同或者不完全相同,则需要在右下方"转换"--"列映射选项"中手动进行映射匹配。

点击【完成】开始迁移,如下图所示:

完成迁移,如下图所示:
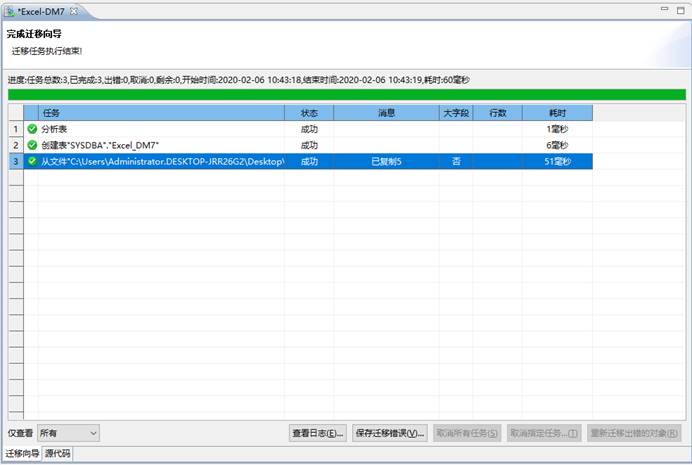
检查数据,如下图所示:
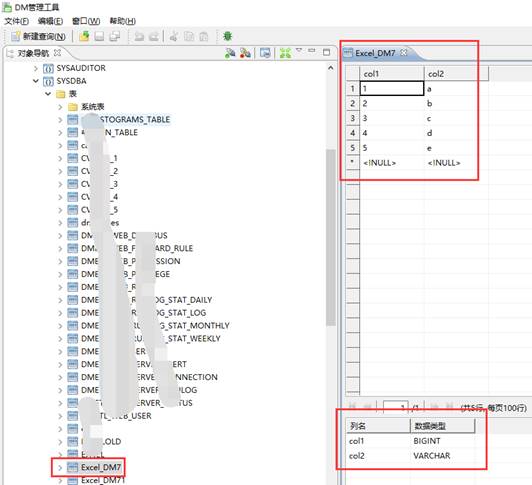
至此,数据已经导入到 DM 数据库中了,如果需要设置导入的列的数据类型,可以在导入前先将对应的数据表进行创建,然后再导入过程中的【目的对象】输入表名即可。
同样的,还可以将不同类型的数据库(如 Oracle、DB2、MySQL 等)和文件(如 TXT、XML 等)数据导入到 DM 数据库中。另外达梦公司还有 DMETL 软件,也可以通过 DMETL 进行导入,此处不进行详细介绍。
方法二: DMFLDR 工具导入
使用 dmfldr 工具无法直接将 excel 文件导入到数据库表中,需要将 excel 文件转换为 csv 格式,如果出现中文乱码,可以使用 Windows 记事本等工具将文件编码改为 UTF-8。转换为 CSV 格式之后,CSV 格式默认每列以逗号','分割,文件内容如下:
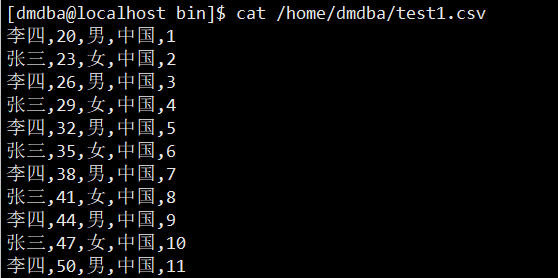
需要注意:Windows 上的 excel 或者 csv 文件拷贝到 Linux 上之后,Windows 格式的空格会变为"^M",需要在 vim 中使用 set ff=unix 将文件格式修改为 unix 格式。
DMFLDR 工具导入具体步骤如下:
创建表:
CREATE TABLE TEST1
(ID INT ,
NAME VARCHAR(100),
SEX VARCHAR(3),
AGE NUMBER,
ADDR VARCHAR(100));
使用 DMFLDR 将 CSV 文件内容装载到表中,创建 dmfldr 控制文件:
[dmdba@localhost bin]$ cat /home/dmdba/test1.ctl
OPTIONS
(
SKIP = 0
ROWS = 50000
DIRECT = TRUE
INDEX_OPTION = 2
CHARACTER_CODE='UTF-8' /*指定数据文件中数据的编码格式,即下面的test1.csv中数据的编码格式*/
)
LOAD DATA
INFILE '/home/dmdba/test1.csv'
BADFILE '/home/dmdba/test1.bad'
INTO TABLE test1
FIELDS ',' /*下面列名与csv文件中对应数据相匹配,否则会报错*/
(NAME,
AGE,
SEX,
ADDR,
ID
)
使用 dmfldr 装载数据:
[dmdba@localhost bin]$ ./dmfldr userid=SYSDBA/*****@localhost:5238 control=\'/home/dmdba/test1.ctl\'
注意注意:使用 dmfldr 工具导入 excel 数据,涉及到文件格式转换,要注意中文编码以及 Windows 文件与 Linux 文件格式兼容的问题(比如空格)。
DM 如何导出 SQL 脚本/导出对象定义的 DDL 语句
方法一: 在管理工具中导出
- 导出单个对象的 DDL 语句
选中单个对象,如具体的表或者视图,单击右键选择【生成 SQL 脚本】,如下图所示:

- 导出一类对象的 DDL 语句
选中表节点或者视图节点,右键,生成 SQL,会生成下面所有表的 SQL,如下图所示:
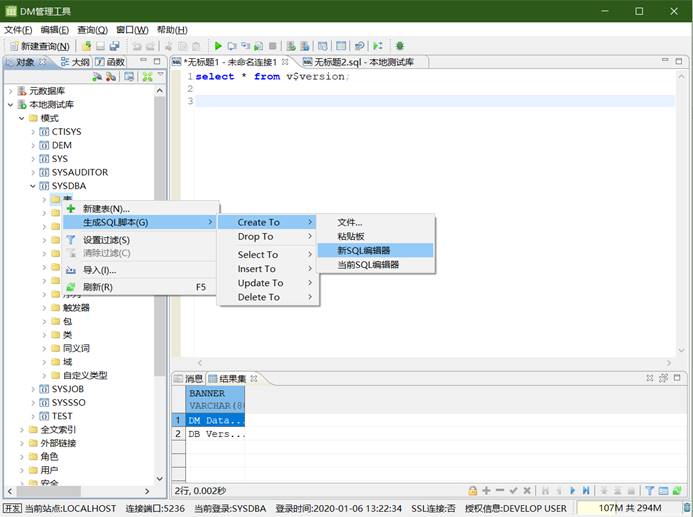
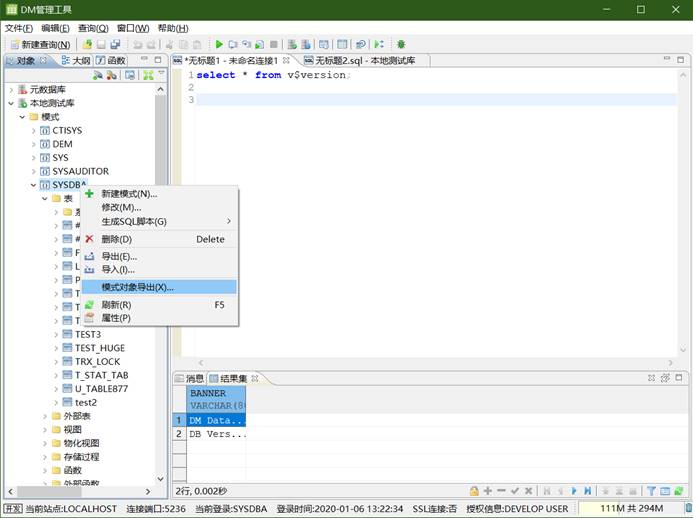
- 导出所有对象的 DDL 语句
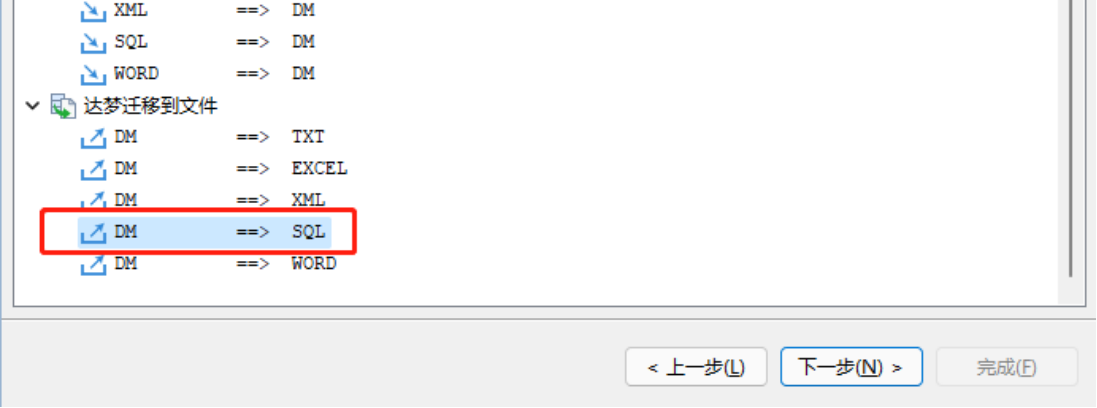
方法二: 利用 DTS 工具导出
新建迁移,选择迁移方式为“DM==>SQL”
配置达梦数据库信息

选择输出的 SQL 脚本文件名称,并选择“仅迁移对象定义”

选择迁移模式及对象类型,根据需求选择表、视图、存储过程等对象类型

选择要导出的对象

迁移任务概述

迁移导出完成

导入 dmp 的正确方式
导出备份文件,如下图所示:
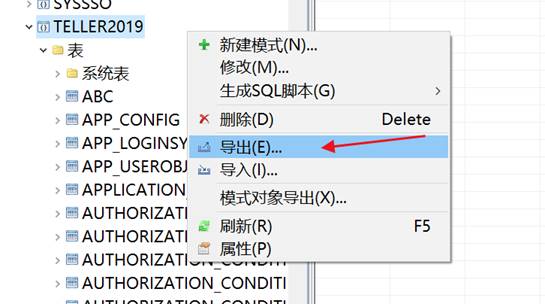
选择导出 dmp 存放的路径,如下图所示:
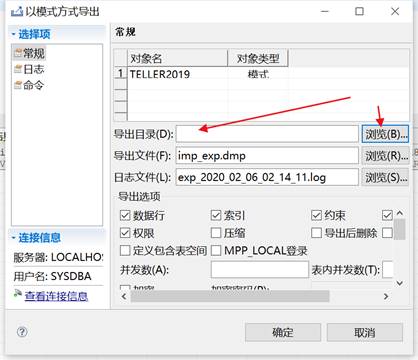
导出成功,如下图所示:
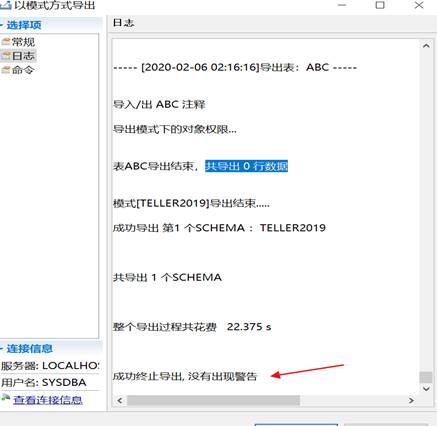
在选择的路径下会生成 dmp 文件和导出日志,如下图所示:
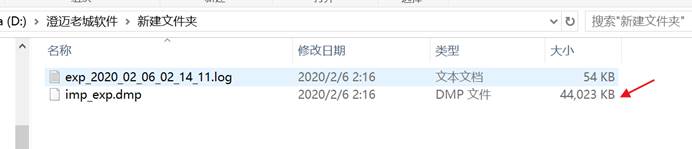
使用管理工具导入,如原表还存在,则报错,如下图所示:
- 如果只是一个表的导出 dmp 文件,则清空表
truncate table,再导入即可。
(为了防止清空表而导致数据丢失,可以重命名表如:alter table tab1 rename to tab2;再创建表和 tab2 一样表结构的 tab1 如:create table tab1 as select * from tab2 where 1=2;)
- 如果是模式导出的 dmp 文件,则先删除模式下的全部表。如表太多了,可以直接删除用户。重新创建用户,再模式导入 dmp 文件。
删除 drop、user 用户,如下图所示:

执行以下语句,创建用户(创建用户前,需先创建表空间):
create user "TELLER2019" identified by "TELLER2019"
default tablespace "HCSTTB"--指定数据表空间
default index tablespace "HCSTTB";--指定索引表空间
grant "PUBLIC","RESOURCE" to "TELLER2019"; --用户权限
导入 dmp 备份文件,如下图所示:
选择 dmp 存放路径,如下图所示:

导入成功,如下图所示:

如果表已经存在了,使用默认方式导入 dmp 时会报错【表或视图已存在】,我们分以下不同情况讨论:
- 如果需要导入少量表且只表定义并未发生过变化,我们可以在导入命令增加参数 ignore=y 即可,导入时忽略创建错误;
- 如果需要导入的表定义已经发生过变化,则我们需要删除数据库中的表后再导入;
- 如果需要导入少量表且数据需要重新灌入,则可以将表数据备份之后,将此表 truncate,再进行导入操作,同时增加参数 ignore=y;
导入 dmp 文件时出现乱码、问号
一般是由于导出与导入时的字符集的环境变量不同。使用命令行 dimp 命令导入,并在执行 dimp 前先执行 export LANG=... 将当前字符集调整的和导出时的一样。
读取 DM 数据库中文乱码,则可能是使用的应用软件和 DM 数据库的应用软件字符集不一致,调整两个字符集为一致状态。另外,在 DM 数据库中,字符集一旦确定好则不可以修改,需要在创建 DM 数据库实例之前确定好字符集,保证不会出现此类问题。
导入 dmp 文件提示初始化参数不一致
警告信息如下:
页大小不匹配,restore error code : -8210。
CASE_SENSIVE 参数不匹配、大小写参数不一致,大小写区分属性不匹配,restore error code : -8212。
LENGTH_IN_CHAR 属性不匹配,restore error code : -8266;编码不一致。
- 页大小不匹配
【问题原因】:
这是因为产生备份文件的数据库数据文件使用页大小与还原备份文件的数据库数据文件所使用的页大小不同,必须保证两边的数据文件使用的页大小一致才能正常还原。
注意数据文件使用的页大小 page_size,可以为 4 KB、8 KB、16 KB 或 32 KB,选择的页大小越大,则 DM 支持的元组长度也越大,但同时空间利用率可能下降,缺省时为 8 KB。
【解决方法】:
使用数据库配置助手 dbca 重现初始化一个库,在设置参数时注意保证两边的页大小一致。
或者在命令行中使用 dminit 重现初始化一个库,在设置参数时注意保证两边的页大小一致。
- 大小写区分属性不匹配,restore error code : [-8212]
【解决方法】:
这是因为产生备份文件的数据库的标识符大小写 (case_sensitive) 的敏感程度与还原备份文件的数据库对标识符大小写的敏感程度不同,必须保证两边对标识符大小写敏感程度一致才能正常还原。
注意标识符大小写敏感,默认值为 Y。当大小写敏感时,小写的标识符应用双引号括起,否则被转换为大写;当大小写不敏感时,系统不自动转换标识符的大小写,在标识符比较时也不区分大小写。
- LENGTH_IN_CHAR 属性不匹配
【解决方法】:
这是因为产生备份文件的数据库的 LENGTH_IN_CHAR 属性(默认为 0)与还原备份文件的数据库的 LENGTH_IN_CHAR 属性不一致,必须保证两边数据库的 LENGTH_IN_CHAR 属性一致才能正常还原。
注意LENGTH_IN_CHAR 属性设置为 1 时,所有 VARCHAR 类型对象的长度以字符为单位,否则以字节为单位。
- 编码不一致
【解决方法】:
这是因为产生备份文件的数据库的字符集编码属性(默认为 GB18030)与还原备份文件的数据库的字符集编码属性不一致,必须保证两边数据库的字符集编码属性一致才能正常还原。
注意只有初始化实例的时候可以选择以上属性,一经启用无法修改。需要重新初始化实例保持导出和导入的初始化设置一样。
高效的数据装载方式
DM 数据库除了 dts 和 dimp 之外,还提供了快速数据装载命令行工具 dmfldr,通过使用 dmfldr 工具能够把按照一定格式排序的文本数据以简单、快速、高效的方式载入到 DM 数据库中,或把 DM 数据库中的数据按照一定格式写入文本文件。
dmfldr 实际上除了客户端工具,还包含一个在 DM 数据库服务器中的 dmfldr 功能模块,它们共同完成 dmfldr 的各项功能。
当进行数据载入时, dmfldr 客户端接收用户提交的命令与参数,分析控制文件与数据文件,将数据打包发送给服务器端的 dmfldr 模块,由服务器完成数据的真正装载工作。并分析服务器返回的消息,必要时根据用户参数指定生成日志文件与错误数据文件。
当进行数据导出时,dmfldr 客户端接收用户提交的命令与参数,分析控制文件,将用户要求转换成相应消息发送给服务器端的 dmfldr 模块。服务器解析并打包需要导出的数据,发送给 dmfldr 客户端,客户端将数据写入指定的数据文件,必要时根据用户参数指定生成日志文件。
在程序目录 bin 下执行,使用方法如下:
./dmfldr userid=SYSDBA/***** control=’/opt/fldr.ctl’
其中 fldr.ctl 需要手动进行配置,控制文件用于指定数据文件中数据的格式,在数据载入时,dmfldr 根据控制文件指定的格式来解析数据文件;导出数据时,dmfldr 也会根据控制文件指定的列分隔符、行分隔符等生成数据文件。控制文件中还可以指定其他的一些 dmfldr 参数值。
具体使用方法和配置方法详见《DM_dmfldr 使用手册》。(手册位于数据库安装路径 /dmdbms/doc/special 文件夹下)
dmfldr 导出报错“获取表信息失败 锁超时”
查看会话进程
select * from v$sessions;
查看该张表是否存在未提交事务,当导出表需要等待释放资源时,会出现此类报错,将相关事务提交即可。
ArcGIS 使用 DM 导入导出 shp 数据
在 2015 年 10 月 27 日至 28 日举行的 2015 第十三届 Esri 中国用户大会上,Esri 中国信息技术有限公司总裁何宁宣布:Esri 中国公司与武汉达梦数据库股份有限公司达成合作,通过双方间的共同研发,ArcGIS 即将完成对 DM 数据库的原生支持。从 ArcGIS 10.4.X 开始支持达梦数据 V7.1.5 及以上版本。 下面简单介绍如何使用 DM 数据库:
| 软件 | 版本 |
|---|---|
| 操作系统 | Windows 10 |
| ArcGIS | ArcGIS 10.4.1 |
| DM 数据库 | DM V7.6.0.153(32 位和 64 位都要安装) |
- 安装 ArcGIS 10.4.1 过程省略。
- 安装 64 位 DM 数据并初始化一个实例,安装 32 位 DM 数据库,过程省略。
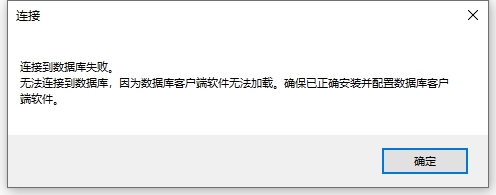
- 将 32 位 DM 数据的..\dmdbms\bin 目录中的 .dll 文件全部拷贝到 ArcGIS 的 ..\Desktop10.4\bin 目录下,有同名文件直接覆盖掉。此步骤非常重要,如果没有拷贝 32 位的 dll 文件到 ArcGIS 中,将会报错,如下图所示:
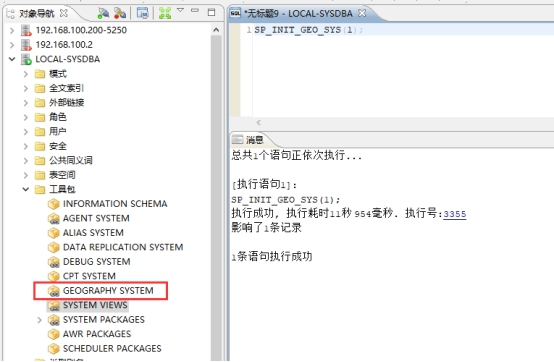
- 使用管理员用户登录数据,调用系统过程
SP_INIT_GEO_SYS(1)创建DMGEO包,如下图调用过程后,工具包中【GEOGRAPHY SYSTEM】将会处于启用状态。
- 添加 shp 数据。
打开 ArcCatalog-右键【连接到文件夹】,如下图所示:
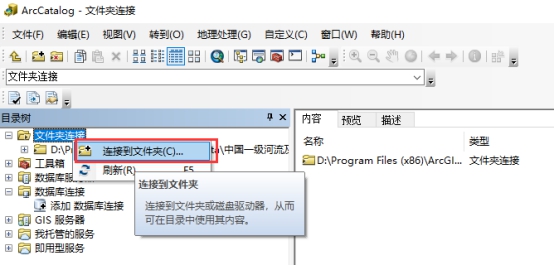
- 连接 DM 数据库。
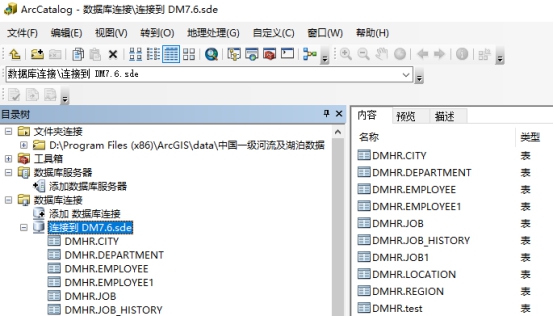
打开 ArcCatalog-数据库连接-双击【添加数据库连接图标】-在【数据库平台】选择【Dameng】,在【数据源】中添加 DM 数据库原,身份验证类型使用默认的【数据库身份认证】,输入数据库的的用户和密码,这里使用数据库的系统管理员用户 SYSDBA,最后点击【确定】即可。
数据源的格式:LOCALHOST;TCP_PORT=5236;CHARACTER_CODE=PG_UTF8
LOCALHOST 表示使用本机的数据库,如果是远程的请使用 IP;
TCP_PORT=5236 表示数据库端口号是 5236;
CHARACTER_CODE=PG_UTF8 表示使用 PG_UTF8 字符集。
连接后可查看数据库中的表数据,如下图所示:
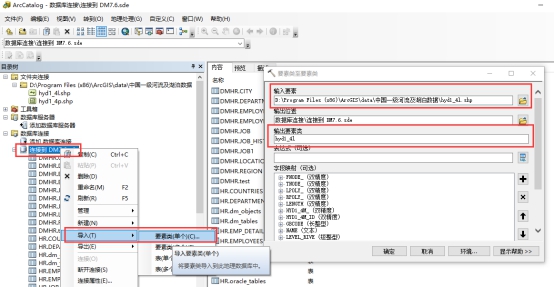
- 导入 shp 文件数据到 DM 数据中。
导入 shp 文件数据,如下图所示:
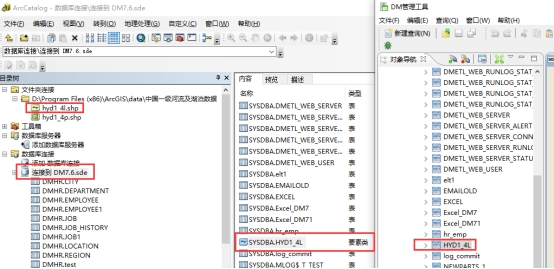
导入后可以在 DM 数据中看到刚导入的要素类,如下图所示:
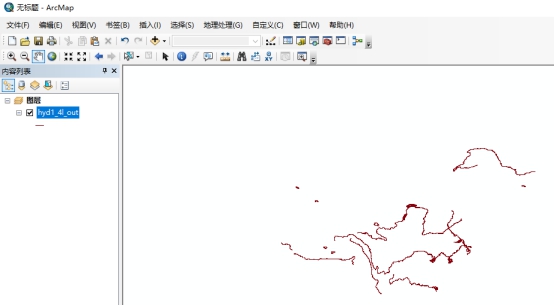
- 将保存在 DM 数据库中的要素类数据导出为 shp 文件数据,并测试导出要素类为 shp 文件数据。
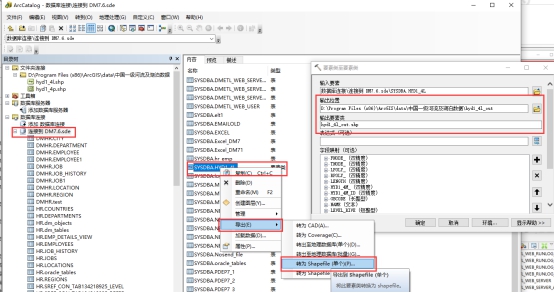
导出后的 shp 文件,如下图所示:

用 ArcMap 测试导出的 shp 文件数据,如下图所示:
客户端工具上的导入导出功能,是灰色按钮不可用
如遇到此问题,请更新客户端版本。客户端数据库版本和服务器端数据库版本不要相差太大。
导入 dmp 文件时提示报错“该工具不能解析此文件,请使用更高版本的工具”
dexp/dimp 的版本太低,要么用导出 dmp 文件的那个版本,要么用更新的版本。
dexp 导入时报错:文件打开出错,请检查您的输入参数
请参考安装目录 doc 目录下的 DM dimp/dexp 使用手册的语法规则。
导入的时候怎么修改模式名?
使用 REMAP_SCHEMA 语法,具体使用方法请参考《DM_dexp 和 dimp 使用手册》,手册位于数据库安装路径 /dmdbms/doc/special 文件夹下。
是否有批量生成 SQL 脚本的方法
使用达梦数据迁移工具 DTS 可以批量导出成 SQL 语句。
“导入”功能按钮是灰色的,不可以点击
【问题解决】
方法一:用客户端连接的其他服务器数据库,服务器端和客户端版本可能相差太大,请更新客户端或者服务器端,尽量保持版本一致。
方法二:配置环境变量指向安装目录的 bin 目录。
导入报错:Error Code:-70013,转换失败
先查看导出数据的源数据库的系统环境变量设置情况,然后设置导入目标数据库的操作系统环境变量:export lang= 源数据库的环境变量
导入 dmp 文件,出现警告:无效的对象
dimp 导入之前要先建好用户,如果需要换模式名,前提是需要指定映射。
例如把 SYSDBA 映射到 TEST 里面:REMAP_SCHEMA="SYSDBA":"TEST"。具体使用方法请参考安装目录 doc 目录下的 DM_dexp 和 dimp 使用手册。
达梦数据库数据导出,再导入到达梦报错:-3503 无效的函数参数
【问题原因】:
达梦客户端版本和达梦服务器版本差异过大。可以运行 select id_code 查询当前的版本信息。
【解决方法】:
- 将客户端版本换成和服务器相同版本
- 如果网络是畅通的,可以选择用 DTS 迁移工具迁移。DTS 迁移工具在安装目录的 tool 目录下。
使用管理工具进行导入的时候提示警告:导入导出编码方式不一致,可能无法转换
说明:本地编码:PG_GBK, 导入文件编码:PG_GB18030,出现以下警告:
[警告]导入导出编码方式不一致,可能无法转换
解决方法:该警告对导入没有影响,可以忽略。
如果想不出现该警告可以修改本地编码与导入文件编码一致,修改方法:
在 dm_svc.conf 文件中指定本地编码,增加一行:
CHAR_CODE=(PG_GB18030)
然后重启管理工具.
dimp 或者管理工具导入会报错:“[警告]Error Code:-70016,日期超出范围”
【问题说明】:
dimp 或者管理工具导入会报错:“[警告]Error Code:-70016,日期超出范围”,导出的源库表的包含 date 类型,而导入的目标库的兼容性参数 COMPATIBLE_MODE=2,那么在导入到目标库时会自动将 date 类型转换为 timestamp(0),并且导入数据报错“日期超出范围“。
【解决方法】:
处理办法有两种:
第一种:通过达梦 DTS 工具进行数据迁移;
第二种:将源库表的 date 类型改为 timestamp(0),然后再导出。可以用语句拼接批量改:
select 'alter table '||owner||'.'||table_name||' modify '||column_name||' TIMESTAMP(0);' from dba_tab_columns where owner='用户名或者模式名' and data_type='DATE';
达梦数据库如何只导出表结构不导出数据
导出时添加 ROWS=N
D:\dmdbms\bin>dexp.exe SYSDBA/***** FILE=D:\AAAA.dmp DIRECTORY=d:\dmbak ROWS=N
其它详细参数 dexp help 查看即可。
达梦 dmp 逻辑导入数据时报字符串截断
- 先排查导出的数据中是否已经存在中文乱码数据。
- 最好是保证导入导出库的字符集一致,避免计算中文存储的字节长度不同导致精度不够。
如何将 A 模式下的表导入到 B 模式
遇到需要将 A 模式下的表导入到 B 模式的需求时,DM 数据库提供了三种解决办法:使用 DTS 迁移工具、模式级逻辑导入导出和表级逻辑导入导出。详细操作过程如下:
- 使用 DTS 迁移工具,将 A 模式下的表选择性迁移到 B 模式下
当前环境下,只有 A 模式下有表 t1、t2。
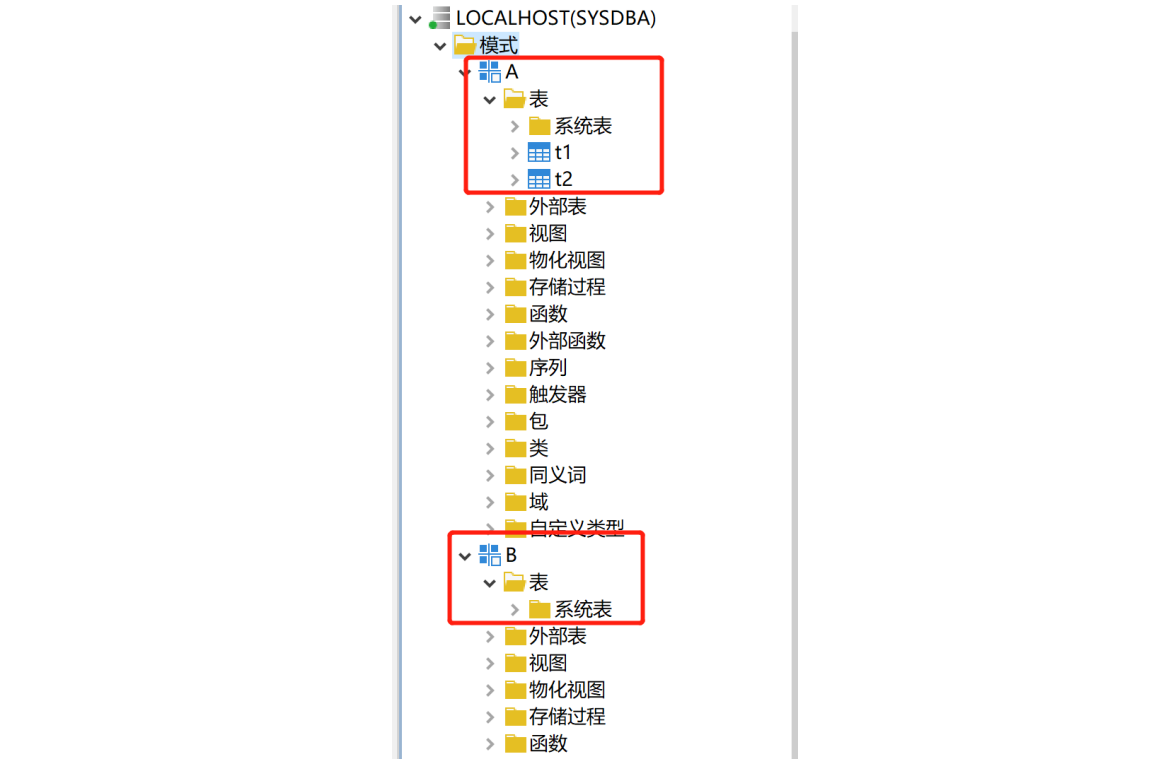
使用 DTS 迁移工具,源模式选择 A,目的模式选择 B,模式对象勾选“表”。点击下一步,并勾选需要迁移的表,然后完成迁移。
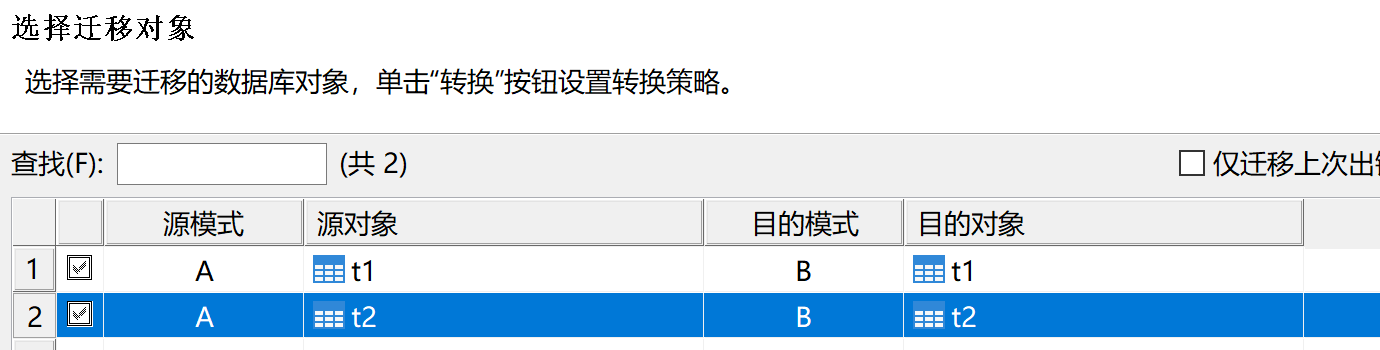
完成迁移后,可以看到 B 模式下已存在表 t1、t2。
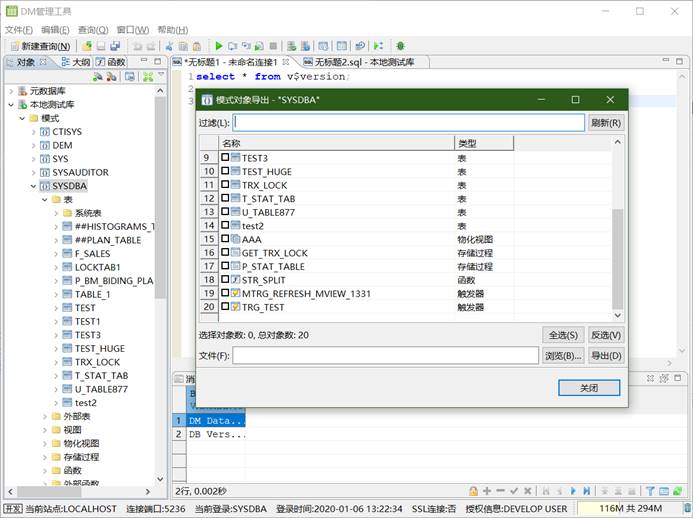
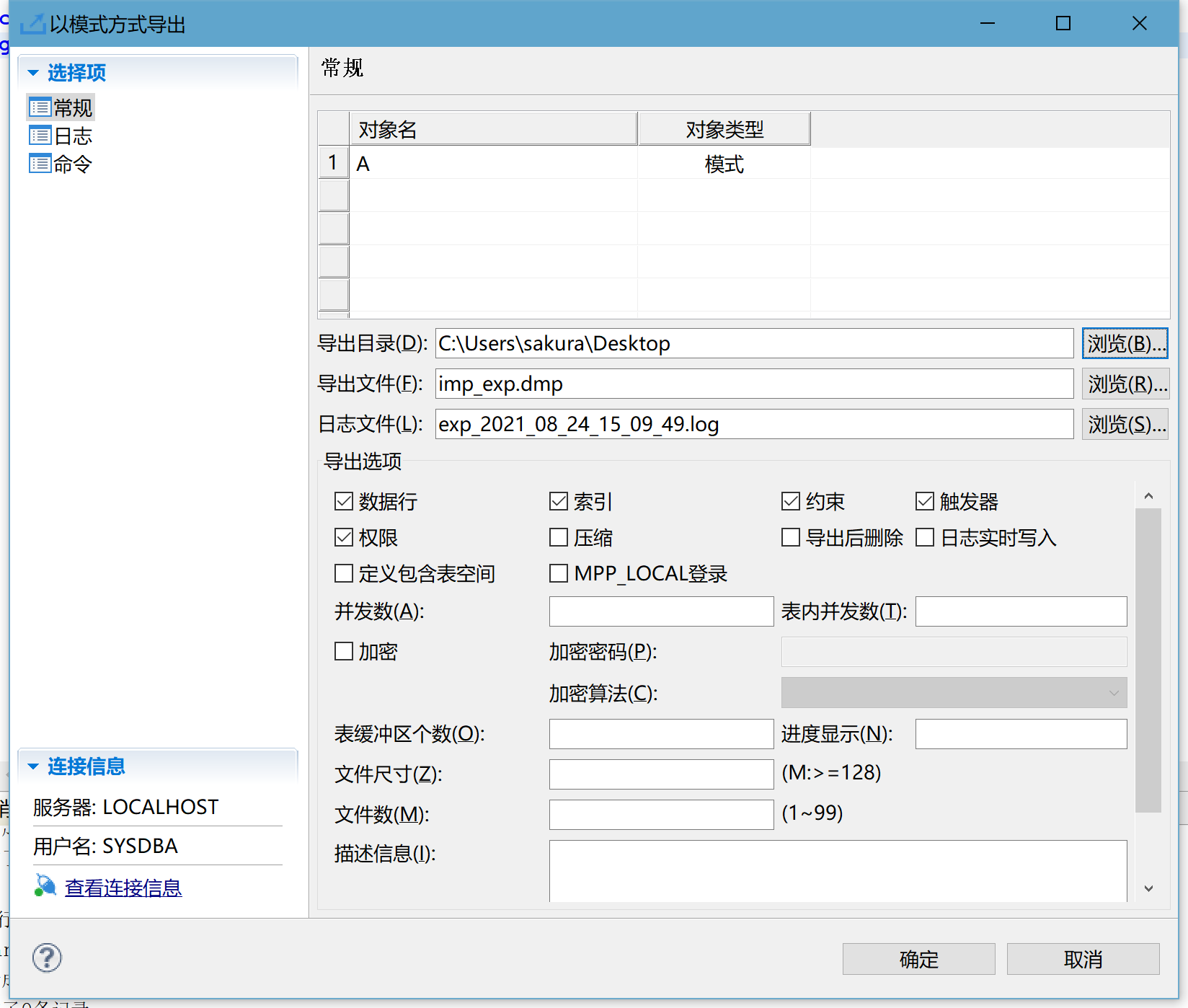
- 使用模式级逻辑导入导出功能,将 A 模式下的所有表,导入到 B 模式下
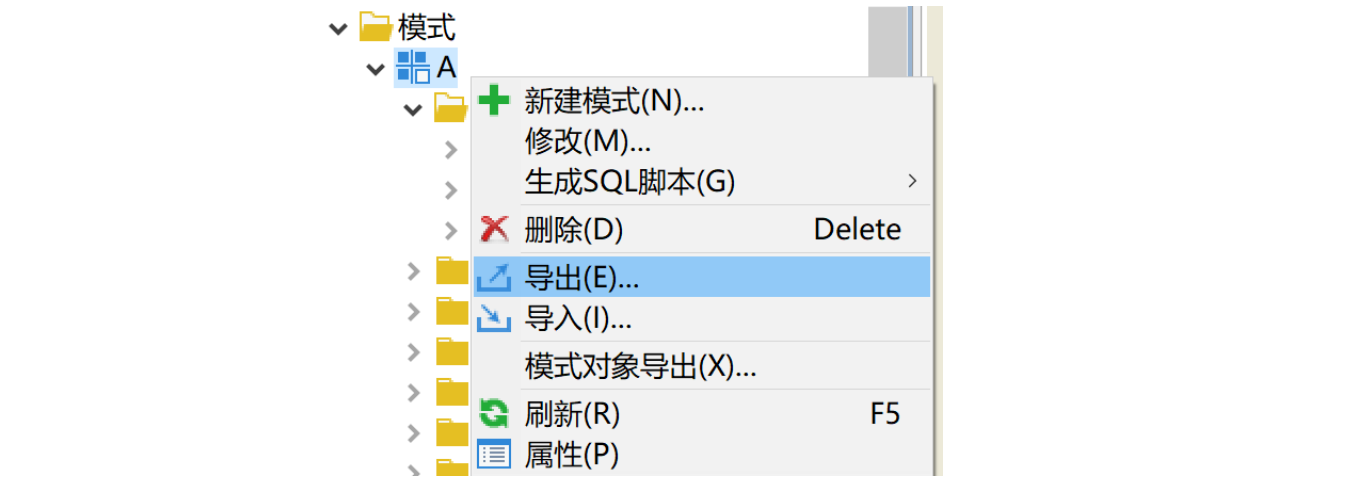
当前环境下,只有 A 模式下有表 t1、t2。右键模式 A,选择导出,将 dmp 包导出到相应的路径下。
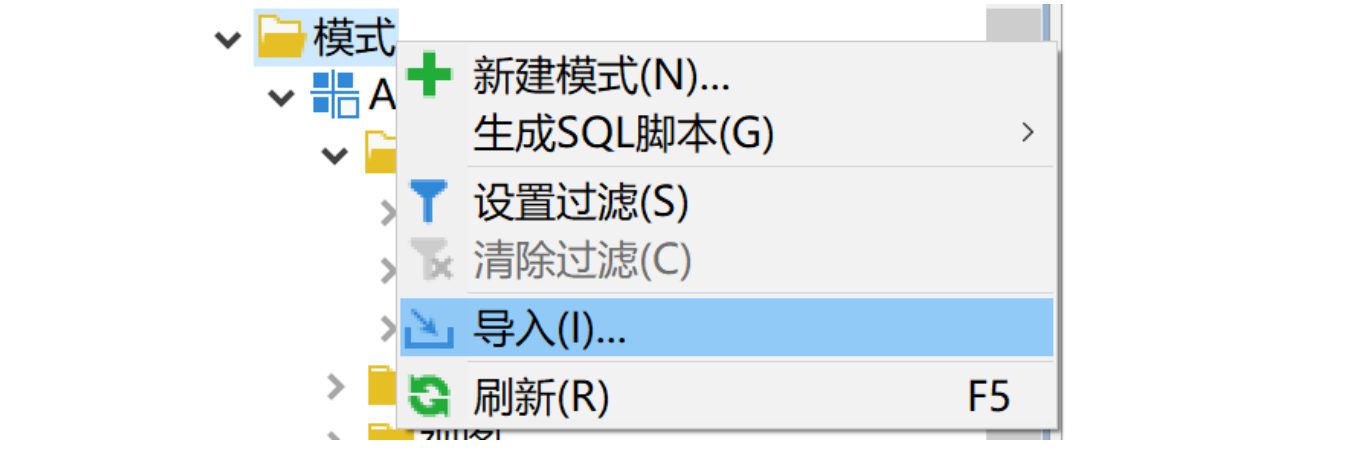
右键模式,选择导入。首先选择刚才导出的 dmp 包,然后将模式 A 映射为模式 B,最后完成导入。
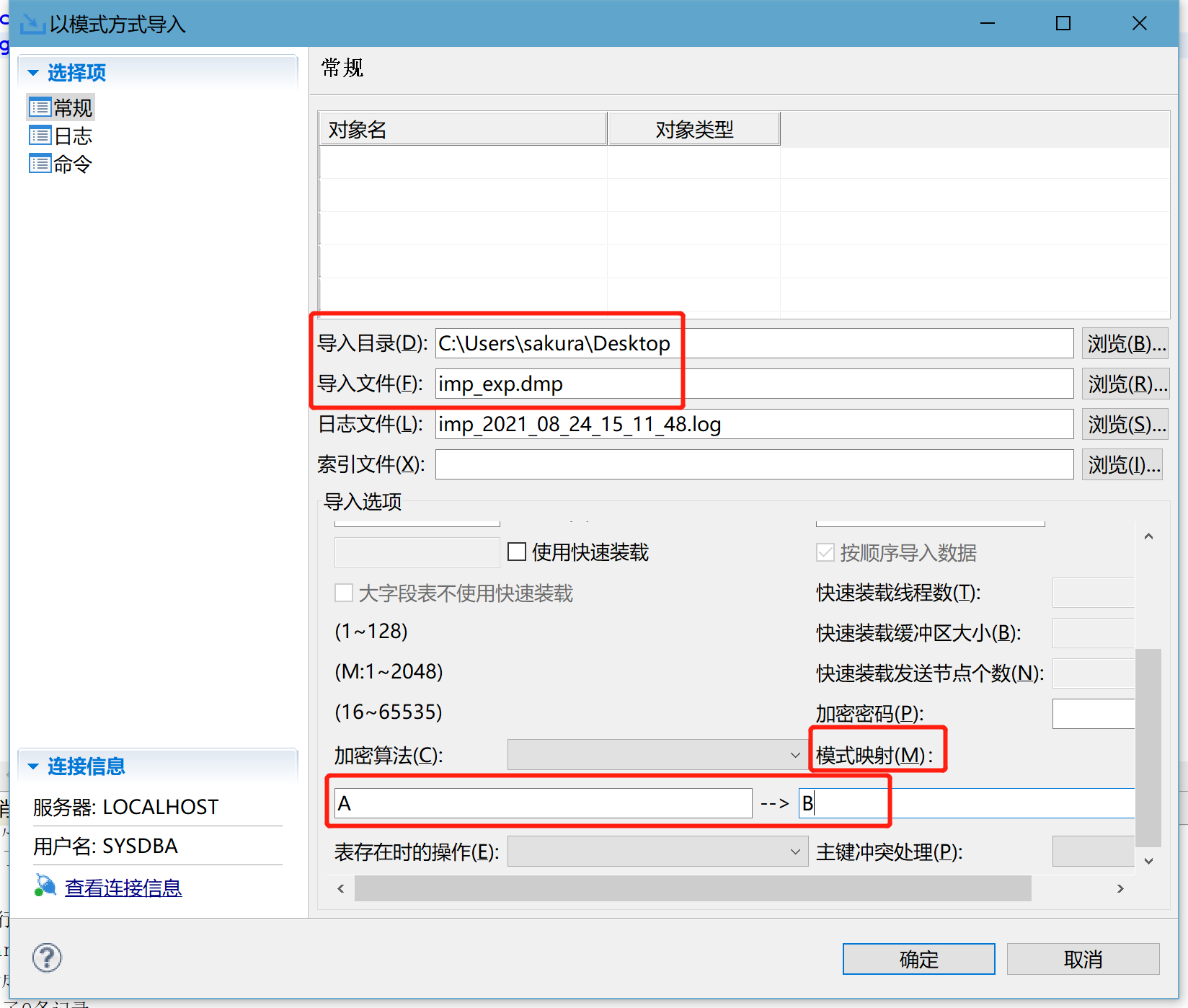
完成导入后,B 模式下已存在表 t1、t2.
- 使用表级逻辑导入导出工具,将 A 模式下的表选择性导入到 B 模式下
当前环境下,A 模式下有表 t1、t2、t3、t4,B 模式下有表 t1、t2。
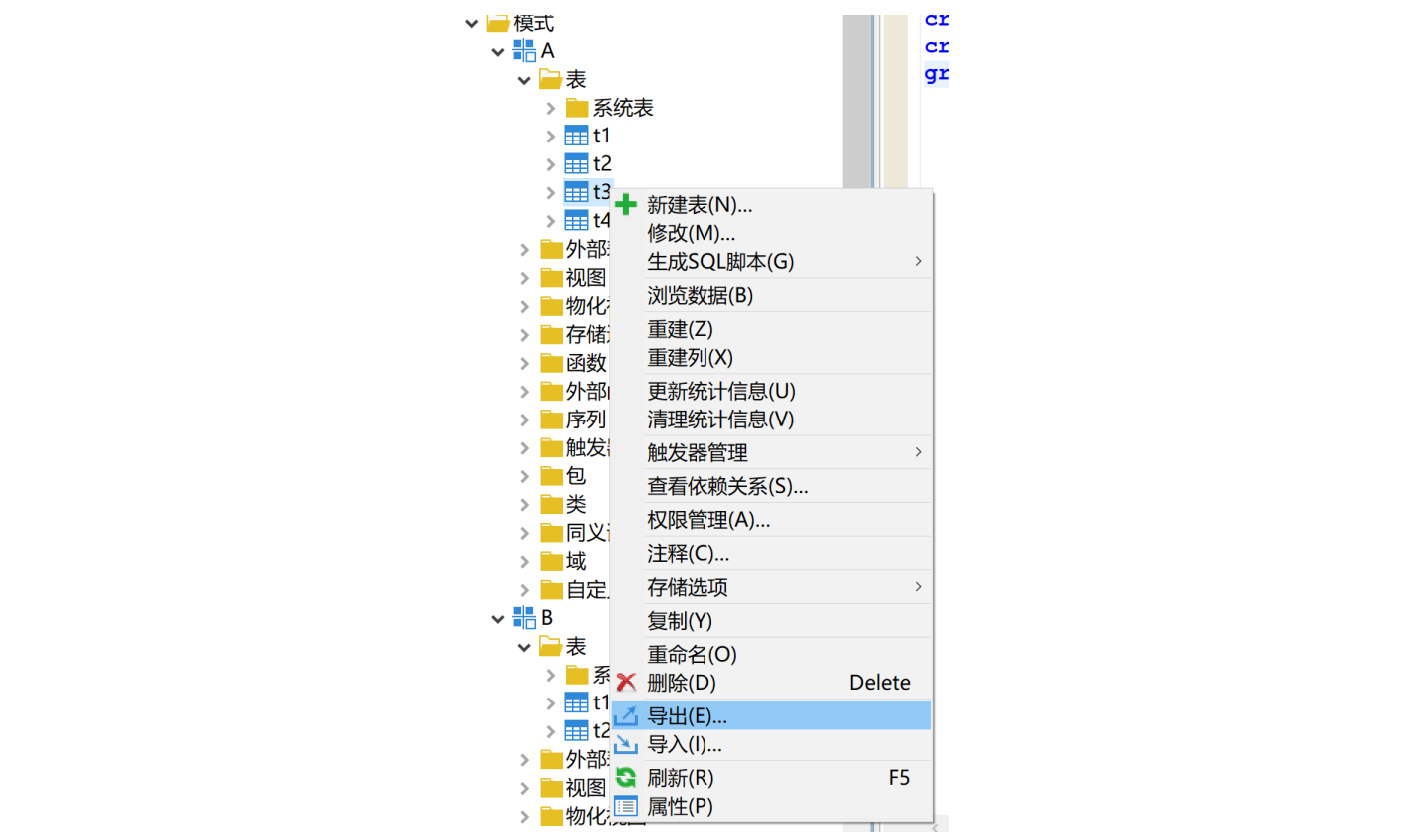
右键 A 模式下的表 t3,选择导出

右键模式,选择导入。首先选择刚才导出的 t3.dmp 包,然后将模式 A 映射为模式 B,完成导入。

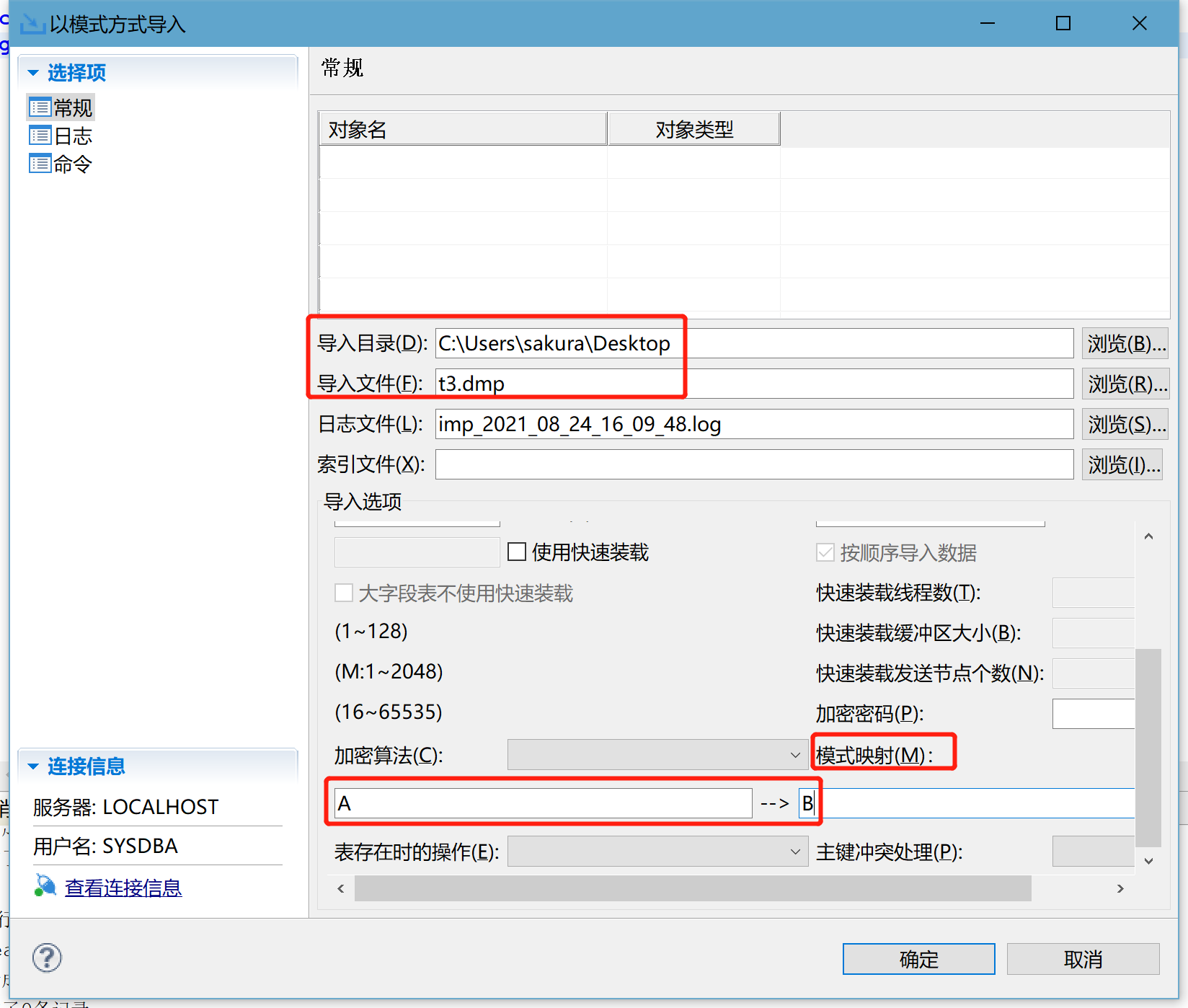
完成导入后,B 模式下新增表 t3。
如何通过 dexp 导出指定表,或根据条件导出某一类的表(比如以 T 开头的表)
【问题解决】:
DM 数据库提供 TABLES 来指定导出的数据表,FUZZY_MATCH 参数来指定 TABLES 选项是否支持模糊匹配,QUERY 参数指定导出的数据范围。
- 导出指定的表。以下以 Windows 环境为例,导出 USER1 用户下的表 table1 和表 table2:
D:\dmdbms\bin\dexp.exe "SYSDBA"/"*****"@LOCALHOST:5237 DIRECTORY=E:\DM\test\USER1 FILE=imp_exp1.dmp LOG=exp_1.log TABLES=USER1.table1,USER1.table2
- 导出 USER1 用户下以 T 开头的表:
D:\dmdbms\bin\dexp.exe "SYSDBA"/"*****"@LOCALHOST:5237 DIRECTORY=E:\DM\test\USER1 FILE=imp_exp2.dmp LOG=exp_2.log TABLES=USER1.T% FUZZY_MATCH=Y
- 导出某个表中的部分数据。如下为导出 T_LOG 表中日期(TTIME 列)大于 20210101 的数据:
D:\dmdbms\bin\dexp.exe "SYSDBA"/"*****"@LOCALHOST:5237 DIRECTORY=E:\DM\test\USER1 FILE=imp_exp3.dmp LOG=exp_3.log TABLES=SYSDBA.T_LOG QUERY=" WHERE TTIME >= '20210101'"
更多导入导出参数请参照《dexp 和 dimp 使用手册》,手册位于数据库安装路径 /dmdbms/doc 文件夹。
达梦数据库导出数据,再导入到另一个库报错:无法解析成员访问表达式
【问题分析】:
进行数据导入导出操作时,case_sensitive 这个参数需要一致。若两个库的大小写敏感属性不一致,则会导致无法识别序列的对象,即出现如上报错。
dmfldr 命令载出时用 WHEN 进行条件过滤无效,SQL 参数应如何使用
【问题描述】:
使用 dmfldr 命令载出的时候,使用 WHEN 进行条件过滤,利用如下语句载出无效:
LOAD DATA
INFILE '/home/test/test.txt'
INTO TABLE TEST.TEST_CCL1
WHEN COL1 != 'zzw'
FIELDS ','
(COL1,COL2,COL3)
载出时使用的 SQL 语句如下:
dmfldr userid=SYSDBA/*****@127.0.0.1:5236 control='/home/test/test.ctl' mode='out' character_code='utf-8' sql='select * from TEST_CCL1 where COL1 ='zzw'
【问题解决】:
首先,dmfldr 只在装载时支持 WHEN 进行条件过滤,载出时无效。
其次,不推荐在命令行中直接使用 SQL 参数。一个原因是空格问题,另一个原因是转义问题,复杂 sql 转义比较麻烦。推荐直接在控制文件中设置,示例如下:
OPTIONS
(
SQL='select * from TEST.TEST_CCL1 where COL1 !='zzw''
)
LOAD DATA
INFILE '/ssd1/wt/manual/fldr/test.txt'
INTO TABLE TEST.TEST_CCL1
FIELDS ','
(COL1,COL2,COL3)
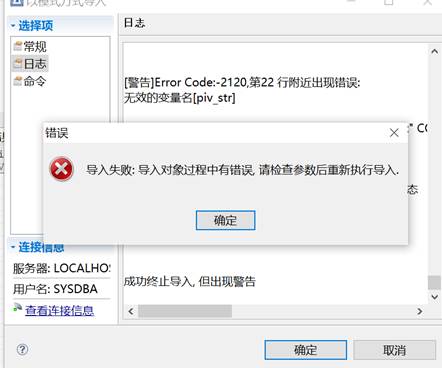
跨模式导入失败:导入对象过程有错误,请检查参数后重新执行导入
【问题解决】:
在导入时,要右键模式目录导入,不要右键模式目录下的任何模式进行导入,如下为错误的方式:
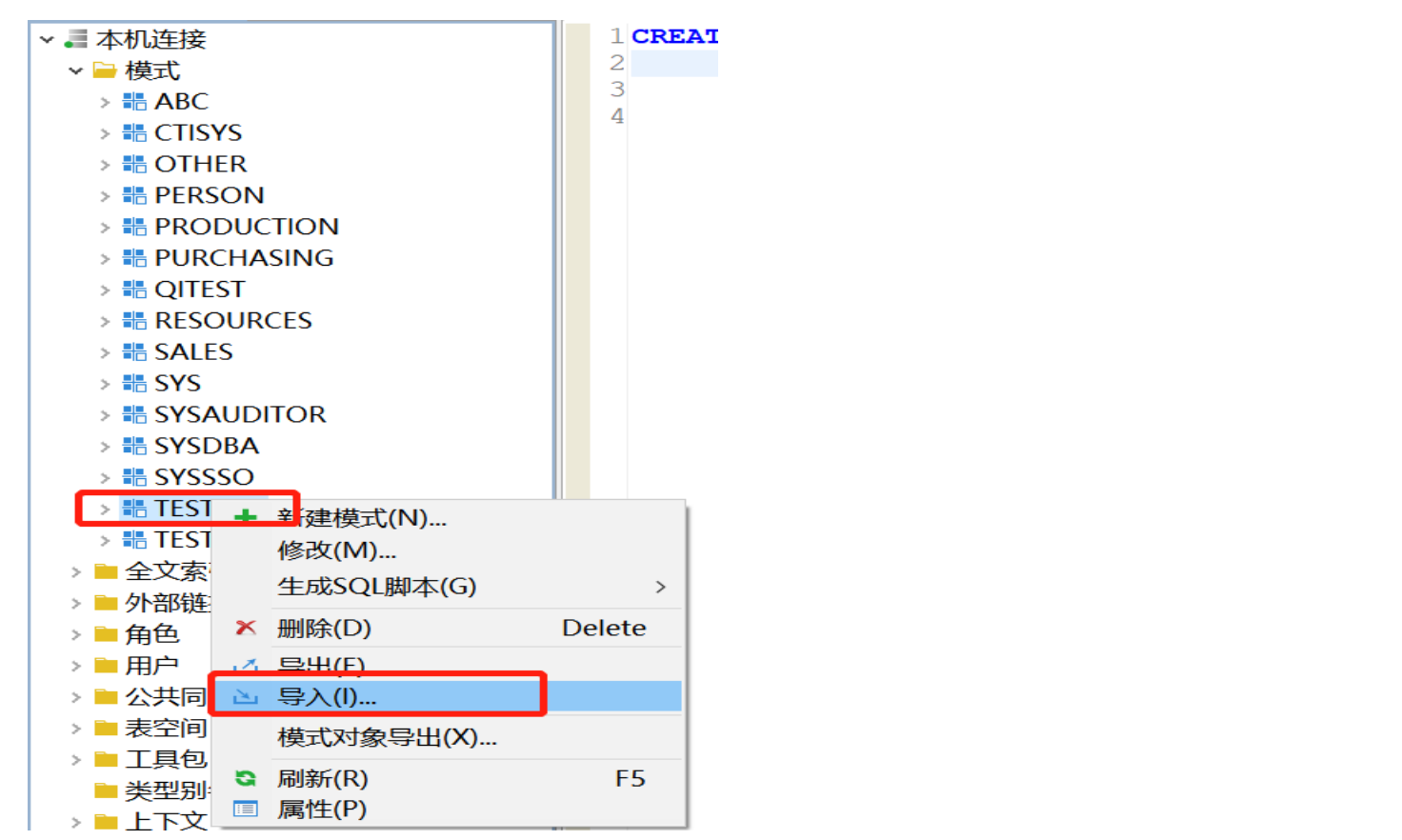
源库中从 A 模式中导出数据,目标库导入到 B 模式中,模式名不同,一般会报错,可以进行模式映射避免该错误。
逻辑导入导出报错:the table SYSDBA.STAT isnot exist or is the system object,check input ,please
【问题描述】:
逻辑导入导出时,命令如下:
./dexp SYSDBA/*****@192.168.100.115:5236 directory=/data/sdb/snn file=imp_exp.dmp tables=STAT$_STAT_TABLE_1
会出现报错:the table SYSDBA.STAT isnot exist or is the system object,check input ,please
【问题解决】:
原因是表名(STAT_STAT_TABLE_1)中含有特殊符号 ,在进行导入导出时需要进行转义,修改后的的语句如下:
./dexp SYSDBA/*****@192.168.100.115:5236 directory=/data/sdb/snn file=imp_exp.dmp tables=STAT\$_STAT_TABLE_1
更多导入导出的转义方法可查看《DM dexp 和 dimp 使用手册》第二章内容,手册位于数据库安装路径 /dmdbms/doc 文件夹。
使用 dimp 逻辑导入 dmp 数据文件,警告错误:Error Code:-6524,跨事务填充大字段,文件中的数据没有全部导入导表中
【问题原因】:
表中数据存在大字段类型数据,dimp 导入时如果开启了并行操作就会导致此错误产生。
解决方法:存在大字段类型的表导入时,不要指定 PARALLEL 参数开启并行,保持默认即可。PARALLEL 参数含义:用于指定导入过程中所使用的线程数目。
导入导出过程中,特殊字符如何转义
【问题解决】:
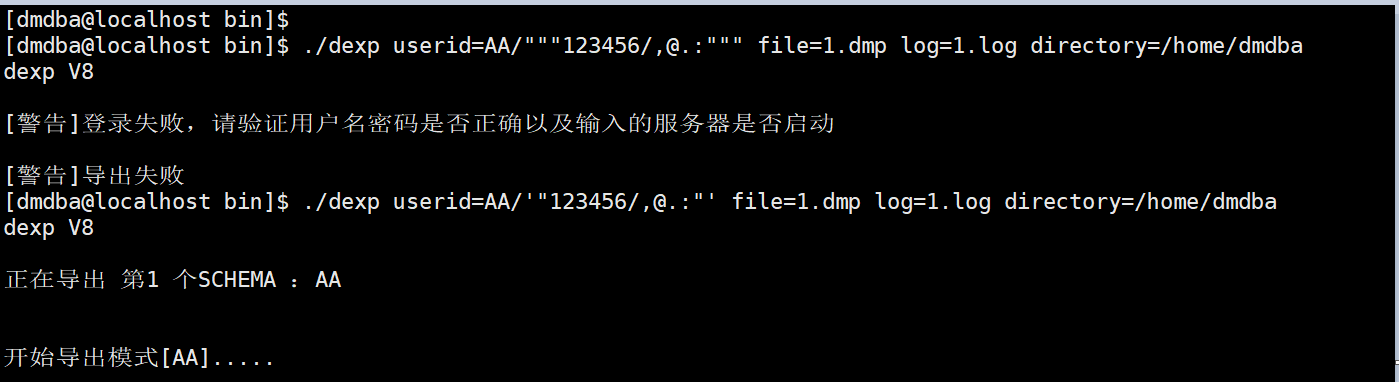
当 PWD 密码中带有特殊字符(/,@.:等)时,在不同操作系统中有不同的转义方式。
- Windows 系统中,转义特殊符号需要三个双引号(""" """),如下图所示:

- Linux 系统中,转义特殊字符一般使用单引号加双引号('" "')才能正确转义,如下图所示:
利用管理工具导出数据时报:[警告]Error Code:-70037,字符串不完整
【问题描述】
使用管理工具导出数据的时候报“[警告]Error Code:-70037,字符串不完整”,导致表的数据没有导出或者导出的数据不完整。如下图所示:

【问题分析】
主要原因是表中的某些行的数据存在不合法的字符(字符乱码),这些乱码主要是 char、varchar 类型的字段最后一位被截断导致,如“�”;
【问题解决】
一般情况下 dexp 导出日志当中,输出几次“[告警] Error Code: -70037 字符串不完整”的信息就说明有多少条对应的数据行数不正确。如下解决方法思路,适用于数据量少的小表。
- 对表的字段类型进行观察和分析,通过如下 SQL 观察数据条数最后一个字符是否为乱码:
SELECT *FROM (
SELECT
RIGHTSTR(列名, 4) zhsw,
RAWTOHEX (rightstr(列名, 1)) hm,
ROWNUM hs --数据所在行数
FROM
表名
)
where hm is not null;
- 将所有异常的数据条数全部找出来进行手工修正,再进行 dexp 导出即可正常。
manager 管理工具导出功能不能使用,界面为灰色
【问题描述】:
使用图形工具后,在模式对象上想导出数据,但是发现导出功能无法使用。“导出”按钮为灰色,不可使用,如下图:

【问题解决】:
查看数据库文件 bin 目录发现 dexp.exe 可执行文件不存在,从相同版本的客户端管理工具拷贝 dexp.exe 可执行文件后,导出功能恢复正常。
总结:在使用工具时,最好不要使用拷贝文件夹的方式,建议使用安装方式安装客户端工具,并在安装之前使用 MD5 校验下载文件是否完整。
DM6 数据库迁移还原成功后,发现其缺失用户登录关联关系
【问题描述】:
DM6 数据库迁移时,如果采用 dmp 方式,还原成功后,会发现其缺失用户登录关联关系,导致应用连接数据库异常。
【问题解决】:
出现以上情况,若手动逐一关联,容易出错,且耗时较多。故编写脚本快速提炼出设置用户登录关联关系的 related 语句。如下提供一实例设置用户关联关系:
declare
my_sql varchar(200);
linshi_1 varchar(200);
linshi_username varchar(200);
linshi_loginname varchar(200);
c cursor;
d cursor;
begin
open c for select name from system.sysdba.sysdatabases;
loop
fetch c into linshi_1;
exit
when c%notfound;
print('set current database '||linshi_1||';');
my_sql :='select username,name from '||linshi_1||'.SYSDBA.SYSUSERS,system.sysdba.syslogins where loginid=id;';
open d for my_sql;
loop
fetch d into linshi_username,linshi_loginname;
exit
when d%notfound;
print('alter user '||linshi_username||' related by '|| linshi_loginname||';');
end loop;
close d;
print(' ');
end loop;
close c;
end;
执行结果如下:

可保存执行结果的消息区输出 SQL 语句,若后期逻辑库关联关系缺失或紊乱后,可执行一系列 set 和 alter 语句,进行关联关系的重新设置。
从代码导入 exlce 表中的数据到数据库后,正常的数值变成了科学计数法
【问题描述】:
从代码导入 exlce 表中的数据到数据库后,正常的 19102952 变成了科学计数法 1.9102952E7。
【问题解决】:
打开 Excel,选中要更改区域,点击上方的【数据】-->【分列】-->【分隔符号】-->【下一步】-->【Tab 键】-->【下一步】-->【文本】-->【完成】,这样操作可成功将 excel 涉及的列设置成文本格式。
DM 中 BLOB 字段存有图片,想要导出 EXCEL(图片以超链接形式)要怎么做?
【问题解决】:
以表 TEST1 为例,C2 列(BLOB)存有图片。
可通过以下步骤导出:
步骤一:使用达梦迁移工具 DTS 先进行迁移,将其直接以超链接形式导出到 Word。
详细迁移步骤如下:
1、迁移方式选择 DM-WORD。
2、输入数据库信息,和导出文件位置。
3、选择要迁移的对象。
4、选择图片所在的表,点击转换。
5、点击迁移参数,选择将大对象保存在单独的文件中。
6、完成迁移。
步骤二:修改文件为图片格式。
详细步骤如下:
1、打开导出文件保存位置可以看到导出了两个文件,一个是 word 文档里面保存的是表里的数据,另一个是文件夹里面存放的则是大字段保存的东西。
2、进入文件夹可以看到,大字段默认导出的是 txt 格式,只需要将文件格式扩展名修改为图片的格式就可以正常打开图片。
可以批量进行修改,例如 windows 下使用 ren 命令:
ren *.txt *.jpg
3、打开导出的 Word 文件夹,同样将文件扩展名修改为图片格式。
步骤三:复制表格到 excel,使用 HYPERLINK 函数设置超链接。
通过以上步骤即可实现把达梦数据库中含有图片的表导出到 excel 并拥有超链接。
管理工具普通用户导入导出报错:"Error Code:-2158,无效的 IP"
【问题描述】
管理工具普通用户导入导出报错:“Error Code:-2158,无效的 IP”。
【问题分析】
导出语句中 ip 使用的是 localhost,而普通用户设置了 IP 限制登录:alter user "AAA" allow_ip "127.0.0.1";
【问题解决】
将 localhost 替换成对应的机器 IP 即可正常导入导出。
注意管理工具可以使用 localhost 主机名登录 AAA 用户,原因是管理工具已自动把 localhost 处理成 127.0.0.1。
在 Windows 环境下使用 dexp 导出时报错:“导出模式错误”
【问题描述】
在 Windows 环境下使用命令 dexp 导出数据库所有表结构和部分数据时报错:“导出模式错误”。
dexp.exe SYSDBA/***** FILE=D:\TEST.dmp full=y query="where rownum<=100"
[警告]导出模式错误
[警告]导出失败
【问题解决】
query 参数必须与 tables 参数一起使用,如果要导出全库的表结构及部分数据则可以使用如下的方法:
dexp.exe SYSDBA/***** FILE=D:\TEST.dmp tables=sysdba.%,test.%, ... query="where rownum<=100" fuzzy_match=y
其中 fuzzy_match=y 表示启用模糊匹配,tables 要列出所有模式。
更多详情可参考达梦数据库安装目录下的 doc 目录中的《DM8_dexp 和 dimp 使用手册》。
导入报错"数据文件少列"和"出现数据转换错误"
【问题描述】
使用 dmfldr 导出列存表中的数据,重新导入到原列存表中时,会报错"数据文件少列"和"出现数据转换错误"。
使用 dmfldr 导出列存表命令:
./dmfldr userid=SYSDBA/*****@10.15.1.35:5120 control=\'/dm/dpc_09/load_tpch/ctrl/test_1118.ctrl\' READ_ROWS=10000000 BUFFER_NODE_SIZE=100 BDTA_SIZE=10000 MODE=\'OUT\'
使用 dmfldr 导入列存表命令:
/dmfldr userid=$user_id control=\'$curr/ctrl/test_1118_1.ctrl\' log=\'$curr/log/test_1118_1.log\' character_code=\'GBK\' READ_ROWS=10000000 BUFFER_NODE_SIZE=100 BDTA_SIZE=10000 SINGLE_FILE=FALSE MODE='IN'
【问题分析】
由于导出结果集时未指定字符集参数 character_code,因此默认为操作系统字符集 "zh_CN.UTF-8",而导入时指定字符集为 GBK,因此会报错"数据文件少列"和"出现数据转换错误"。
【问题解决】
在进行导入导出操作时使用相同的字符集。
dmfldr 导出数据文件字段之间如何以 16 进制 ASCLL 码“0x02”方式进行分割
【问题描述】
dmfldr 导出数据文件要求字段之间以 16 进制 ASCLL 码 “0x02” 方式进行分割,例如使用 Notepad,开启显示全部符号应看到 STX 分隔字符。
【问题解决】
修改控制文件中 FIELDS 为 X '02' 再导出,即可实现以 16 进制 ASCLL 码 “0x02” 方式进行分割。
示例如下:
- 创建测试表结构;
create table T_test
(
col1 varchar2(40)
,col2 date
,col3 date
,col4 date
);
- 插入数据;
insert into T_test values('a','2020-01-01','2021-01-01','2022-01-01');
insert into T_test values('b','2020-01-01','2021-01-01','2022-01-01');
insert into T_test values('c','2020-01-01','2021-01-01','2022-01-01');
- 控制文件指定参数 FIELDS 为 X '02';
OPTIONS(skip=0)
load data
INFILE '/data/dmfldr/T_test.dat'
INSERT
INTO TABLE T_test
FIELDS X '02' --注意X后有空格
(
col1
,col2
,col3
,col4
)
- 导出数据;
dmfldr userid=SYSDBA/***** control=\'/data/dmfldr/dmfldr.ctl\' mode=\'out\'
- 查看数据文件字段之间以 16 进制 ASCLL 码“0x02”方式进行分割。
其他字符要求参考 ASCII 一览表。
dmfldr 自定义 SQL 功能导出结果集顺序与 SQL 查询出的结果集顺序不一致
【问题描述】
使用 dmfldr 自定义 SQL 的功能,导出的文本中结果集顺序与自定义 SQL 中查询的结果集不一致。
./dmfldr USERID=SYSDBA/***** TABLE='TA' SQL='SELECT ID FROM TA ORDER BY NAME' DATA=\'/home/dmdba/ta.text\' MODE=\'OUT\'
【问题分析】
此问题是由于 dmfldr 默认开启了并行,会将并行度设置为系统 CPU 的个数导致。
【问题解决】
可以通过调整并行线程数目来降低出现使用自定义 SQL 的功能导出的文本中结果集顺序与自定义 SQL 查询中结果集顺序不一致的概率。
在使用 dmfldr 自定义 SQL 功能时通过指定 TASK_THREAD_NUMBER=1,将并行线程数调到最小。
./dmfldr USERID=SYSDBA/***** TABLE='TA' SQL='SELECT ID FROM TA ORDER BY NAME' DATA=\'/home/dmdba/ta.text\' MODE=\'OUT\'
TASK_THREAD_NUMBER=1
dmfldr 装载含有中文字段长度 8296 的数据文件失败
【问题描述】
dmfldr 装载含有中文字段长度 8296 的数据文件失败,表定义该字段为 varchar2(30000),varchar/varchar2() 类型,缺省值 8188 字节。
【问题解决】
将该字段数据类型改为 text,且装载时加上 direct=false 参数后装载成功。命令参考如下:
./dmfldr SYSDBA/***** control=\'/data/dmfldr/dmfldr.ctl\' mode=\'in\' lob_directory=\'/data/dmfldr\' direct=false
参数说明:
DIRECT 为 FALSE 时,dmfldr 选择普通的插入方式装载数据,可以保证数据的正确性和约束的有效性,效率比前者要低。 此参数为可选参数,作用于 MODE 为 IN 的情况下,当 MODE 为 OUT 时无效。
数据导出报错:“创建文件失败,文件空间已经耗尽”
【问题描述】
通过 C++ 的 system 函数调用 dexp 命令进行数据导出,出现报错:“创建文件失败,文件空间已经耗尽”。
【问题分析】
该问题是由于此种方式导出时单个文件大小不能超过 4g 导致。
【问题解决】
可以通过 dexp 的参数 filesize 设置导出文件分片,进行导出,导出命令参考如下:
./dexp xygis/******@210.10.1.7:5236 owner=xygis FILE=export_%U.dmp DIRECTORY=/home/h-a2/vl/home/ams/bin/databak LOG=export_%U.log filesize=6000M
dimp 导入数据时报错:"无效的模式名"
【问题描述】
使用 dimp 导入数据时,模式已经创建,但报错:"无效的模式名"。如下图所示:
【问题解决】
该问题为导出 dmp 文件的源端库创建 TEST 模式时,未通过创建的 TEST 用户创建,TEST 模式所属的用户为 SYSDBA 或其他用户。而目的端创建 TEST 模式是通过创建 TEST 用户进行附带创建,TEST 模式所属的用户为 TEST。规避该问题时,可以通过 REMAP_SCHEMA=TEST:TEST 参数进行规避。如下图所示:
dexpdp 工具执行导出逻辑时,报错:“ [警告]Error Code:-6819,字符不完整”
【问题描述】
dexpdp 工具执行导出逻辑时,报错:“ [警告]Error Code:-6819,字符不完整”。
【问题分析】
通过查看 V$RUNTIME_ERR_HISTORY 视图以及 sqllog,发现报错的 sql 为 :0=SF_READ_DEXPDP_LOG(:1,:2,:3,:4)。字符不完整该报错大多数情况是导出的字符集与数据库的字符集不一样,处理此问题时发现使用 dexp 工具导出不报错,使用 dexpdp 才会出现该问题。
【问题解决】
可以参考如下方法尝试解决该问题:
- 修改导出用户的编码,参考以下命令:
export LANG=zh_CN.GBK
export LANG=zh_CN.UTF-8
- 分析 sqllog 日志发现每次都是 SF_READ_DEXPDP_LOG 函数,在 dexpdp 后新增 SIMPLE_LOG=Y 参数后会换一种日志格式即可解决该问题。
参数说明:
SIMPLE_LOG: 用于设置导出日志是否只打印简要日志,简要日志只打印导出对象个数和导出表数据行数。可选参数。N:导出日志不使用简要日志,缺省值;Y:导出日志使用简要日志。
使用管理工具导入 DMP 文件时报错:“拒绝访问”
【问题描述】
使用管理工具导入 DMP 文件时出现如下报错:
成功终止导入, 但出现警告
os_file_open_normal_rw error! desc: 拒绝访问。
, code: 5, path: C:\Users\1425\Desktop\imp_exp24scyun20240416.dmp
dimp V8
【问题分析】
该报错通常是因为没有足够的权限或者文件被设置为只读导致。
【问题解决】
可以尝试通过授予导入文件读、写和执行的权限来解决该问题。
导入数据时出现大量告警:“输入错误,请重新输入”
【问题描述】
使用 nohup 命令将 dimp 放到后台导入数据时出现大量警告:“输入错误,请重新输入”。
nohup ./dimp SYSDBA/*****@LOCALHOST:5236 DIRECTORY=/home/dmdba FILE=full0510.dmp full=y table_parallel=16 parallel=16 LOG=dimp_full0510.log TABLE_EXISTS_ACTION=REPLACE &
【问题分析】
排查发现是由于导入日志已存在,在导入日志已存在时,dimp 默认打印交互信息:
[警告]文件"/home/dmdba/dimp_full0510.log"已经存在
是否覆盖(y/n, 1/0):
nohup 将 dimp 程序放到后台执行后,未正常处理交互信息,相当于未输入是否覆盖的选项(y/n,1/0)。类似如下场景:
【问题解决】
按需求设置 DUMMY=Y 或 DUMMY=N 。
参数说明:
DUMMY 用于设置交互信息处理。可选参数,缺省使用 P 打印交互信息。语法如下:
DUMMY=P/Y/N
P:打印交互信息,默认方式。
Y:不打印交互信息,所有交互都按 YES 处理。
N:不打印交互信息,所有交互都按 NO 处理。
dexp 逻辑导出如何拆分导出文件,dimp 逻辑导入如何导入拆分文件
【问题描述】
Linux 服务器上数据库较大使用 dexp 逻辑导出如何拆分导出文件,dimp 逻辑导入如何导入拆分文件。
【问题解决】
dexp 导出拆分文件:
dexp 导出拆分文件可使用参数 FILESIZE 参数指定单个文件大小,配合 FILE 参数指定文件名 %U 通配符自动扩展进行导出,示例如下:
dexp USERID=SYSDBA/***** FILE=db_str_%U.dmp LOG=db_str_%U.log FULL=Y DIRECTORY=/data/tianshuai FILESIZE=128M
dimp 导入 dexp 导出的拆分文件:
dimp 导入 dexp 导出的拆分文件时仅需要指定第一个文件名进行导入,示例如下:
dimp USERID=SYSDBA/***** FILE=db_str_01.dmp LOG=db_str.log DIRECTORY=/data/tianshuai
使用 dimp 导入数据时,物化视图报错:import instance's VlEW objects : MV_XXX
【问题描述】
使用 dimp 导入数据时,物化视图失败报错如下:
【WARNING】the version of tool and server not fit
import instance's VlEW objects : MV_XXX
【问题解决】
方法一: 需要保证导入导出两边的数据库版本以及 dimp 版本一致。
方法二: 赋予目标库的用户权限,步骤如下:
- 先在目标库上执行:
SP_CREATE_SYSTEM_PACKAGES (1,'DBMS_MVIEW');
grant execute on DBMS_MVIEW to plcms;
- 然后再次导入(过滤表):
dimp xxxxx owner=plcms exclude=\(ROWS\)
使用快速装载的工具进行导入,在导入数据时报数据错误
【问题描述】
CSV 文件使用快速装载的工具进行导入,但是在导入数据时报数据错误,如下图:
【问题解决】
排查后发现为双引号导致的该问题,需要在 ctl 文件里添加 enclose by ' " ',添加后可正常进行装载。
dexp 导出报错:指定数据文件大小,必须使用 %U 对名称进行自动扩展
【问题描述】
在使用 dexp 导出超大数据量,使用参数 FILESIZE=20G 时,提示导出失败,【警告】指定数据文件大小,必须使用 %U 对名称进行自动扩展,如下图一所示:
【问题解决】
如果指定文件在生成的过程中自动扩展为多个,文件名需要包含通配符 %U,用于作为自动扩充文件的文件名模板。%U 表示为 2 个字符宽度的数字,由系统自动生成,起始为 01。再使用 FILESIZE 参数来指定文件的大小。
以下为示例方法,导出模式,单个文件 dmp 文件限定 20G,导出命令:
./dexp USERID=SYSDBA/XXXXXX@XXXXXX:5236 FILE=V80%U.dmp DIRECTORY=/home/dmdba/dmbackup LOG=V8020250225%U.log LOG_WRITE=Y COMPRESS=Y FILESIZE=20G SCHEMAS=V80 PARALLEL=4
导入命令:
./dimp USERID=SYSDBA/XXXXXX@XXXXXX:5236 FILE=V8001.dmp DIRECTORY=/home/dmdba/dmbackup LOG=V8001imp.log REMAP_SCHEMA=V80:V90 PARALLEL=4
在导入的过程中,把所有的 dmp 文件放在 /home/dmdba/dmbackup 目录,file 参数只需要写导出产生的第一个 dmp 文件,其他文件在导入的过程中会自动导入。如上面示例所示,导出的文件格式是 V80%U.dmp,系统生产的第一个 dmp 文件是 V8001.dmp,在导入的过程中,file=V8001.dmp 即可。
dmfldr 工具导入数据时报错:超过最大错误数(无效的大字段数据格式)
【问题描述】
使用 dmfldr 工具导入数据失败,报错信息为:超过最大错误数(无效的大字段数据格式)。
【问题分析】
在使用 dmfldr 工具进行数据导入时,因源端与目标端字段类型不匹配导致导入失败。具体表现为:源表字段定义为 VARCHAR 类型,而目标表对应字段为 TEXT 类型,在导入时格式解析发生异常。
【问题解决】
在 dmfldr 导入命令中添加 LOB_AS_VARCHAR=TRUE 参数,该参数的作用是强制将目标端的大字段按 VARCHAR 格式处理,从而规避因类型不匹配导致的解析错误。
管理工具导出结果集报错
【问题描述】
使用管理工具导出 select 结果集时报错:The workbook already contains a sheet named xxxxxxxxxxxxxxxxxxxxx。
【问题分析】
原因是管理工具导出 select 结果集时会将表名(结果集的名字)转化为 excel 的页签名,而页签名有长度限制最大为 31,当表名的长度大于 31 时则会报错。
【问题解决】
- 如果 select 中包含多个表名,则将一个表名小的表放在前面进行查询,然后导出结果集。
--例如,将
select * from vhhhhhhhhhhhhhhhhhhhhhhhhhhh111111 a ,v$dm_ini b
where a.para_name=b.para_name and a.para_name='CTL_PATH';
--改为
select * from v$dm_ini b,vhhhhhhhhhhhhhhhhhhhhhhhhhhh111111 a
where a.para_name=b.para_name and a.para_name='CTL_PATH';
- 如果只有单个表,可以参考使用以下语句。
select * from 长名表 where 1=2
union select * from 长名表;
--例如:
select * from vhhhhhhhhhhhhhhhhhhhhhhhhhhh111111 where 1=2
union select * from vhhhhhhhhhhhhhhhhhhhhhhhhhhh111111;
管理工具导出或导入时报错:"openssl lib load failed code! -115"
【问题描述】
windows 环境下使用管理工具导出或导入时报错:"openssl lib load failed code! -115"。
【问题分析】
该报错为管理工具无法找到 openssl 的 lib 依赖包,一般情况下对应的依赖包位于数据库软件安装路径的 bin 下,可以通过配置环境变量让管理工具找到对应的依赖包,极少数情况下是操作机本身缺少某些依赖项。
【问题解决】
- 配置环境变量
通过我的电脑-属性-高级系统设置-环境变量中,在系统变量中的 Path 中添加数据库软件安装路径的 bin 的路径,例如 D:\dmdbms\bin,并配置新的环境变量 LD_LIBRARY_PATH ,变量同为 bin 的路径。然后重启管理工具,使用管理员身份打开管理工具重新尝试导入导出。
- 重新部署客户端
如果现有客户端并非正常安装,而且从其他地址拷贝或直接解压 iso 所获得,建议使用对应版本的安装包重新安装客户端,然后使用管理员身份打开管理工具重新尝试导入导出。
- 使用 cmd(命令提示符)命令绕过管理工具进行导出
上述办法无法解决问题,可以使用 cmd 命令进行导入导出,具体操作流程如下,使用管理工具导入导出功能,选择好导出导入的项目并完成所有配置后,点击左侧命令,获取其中的命令。
使用管理员身份打开 cmd(命令提示符),将复制的导入导出命令粘贴入 cmd 中并修改用户名或密码,回车执行导出导入。
- 下载 openssl
如果上述操作均无法成功,可能为操作机器本身缺少依赖包,可前往 openssl 官网下载进行安装,安装包名称示例:Win64OpenSSL_Light-3_5_3.exe。安装完成后使用管理员身份打开管理工具重新尝试导入导出。