本章节主要介绍从其他数据库迁移到 DM 常见问题,为用户提供从其他数据库迁移到 DM 常见问题的分析和解决思路。除此之外,用户还可前往达梦技术社区参与更多问题讨论。
目录
- DTS 能否把其他数据库脚本生成 DM 的脚本
- DTS 能够只迁移表结构吗
- DTS 目的模式名可以自定义么
- DTS 批量操作迁移所有表的表定义
- 迁移对象有哪些
- 管理工具、DTS 缓存清理
- PG12 向 DM 迁移无法显示源端
- 迁移数据至 DM MPP 集群提示随机分布表不能建唯一索引
- 报错:表或视图不存在
- Sybase 迁移到 DM
- 如何先删除旧表的记录 ,再迁移数据
- Excel 表中数据粘贴到数据库表
- 神通数据库 date 类型数据迁移到 DM 时,时间精度丢失
- 若要迁移某个包,如何查询所对应的依赖对象的 DDL 语句
- 利用 DTS 迁移工具,从 postgresql 到 DM 数据的迁移报错:时间类型错误
- Postgresql 视图迁移到 DM 报错: string index out of range:17
- Postgresql 源表中有字段定义默认值约束为序列的,将表结构迁移到 DM 时报错:default 约束表达式无效
- 使用 dts 从人大金仓迁移到 DM,报错:com.kingbase8.jdbc.KbArray cannot be cast to dm.jdbc.driver.DmdbArray
- 通过 VNC 实现在服务器端使用 DTS 进行数据迁移
- DB2 数据库迁移至 DM 报错:java.io.CharConversionException
- 非法的函数调用序列
- PgSQL 迁移到 dm 后,如何实现 string_to_array 函数功能
- PgSQL 中的 string_to_array && string_to_array 用法如何在 dm8 当中实现
- 使用 DTS 将 pg 空间类型数据迁移到 DM 时报错:“函数 st_asbinary(country.geometry) 不存在”
- 使用 DTS 将 pg 迁移到 dm 报错时间类型转换类型不匹配
- 使用 DTS 将 pg 迁移到 DM,迁移后部分 varchar 字段为空
- kafka 通过 etl 迁移数据时无法消费数据
- MariaDB 包含中文列名的表迁移到 DM 报错:" Unknown column '????' in 'field list'"
- DB2 迁移到 DM 如何适配函数 timestampdiff
正文
DTS 能否把其他数据库脚本生成 DM 的脚本
不可以。不能直接通过 DTS 从其他数据库生成 DM 数据库语法的脚本,但是可以使用 DTS 工具将其他数据库中的数据对象及数据迁移到 DM 数据库中,在 DM 数据库中生成 DM 数据库语法的脚本。
DTS 能够只迁移表结构吗
DTS 可以只迁移表结构,使用 DTS 工具迁移选中表,双击后出现下图所示:
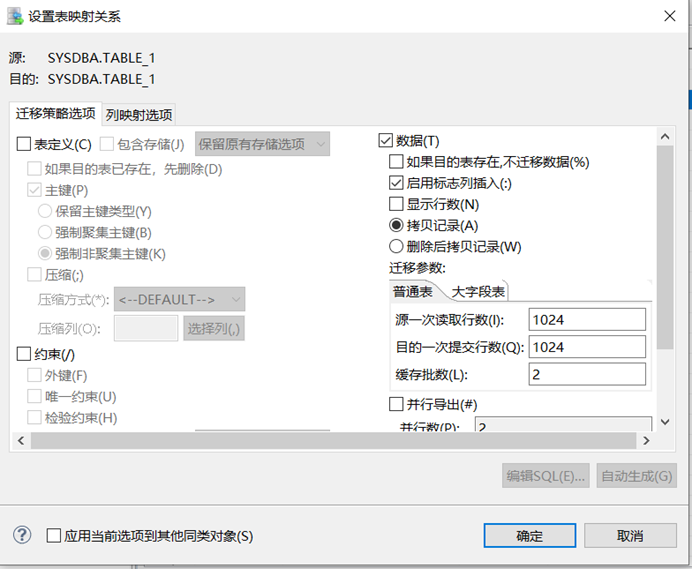
根据迁移需要可以设置表的迁移策略,来达到迁移表结构的目的。
DTS 目的模式名可以自定义么
目的模式名可以自定义,首先在需要迁移的目的端创建自己想要迁移的模式名,然后进行迁移的时候双击目的模式名。如下图所示:

会出现选项,选之前创建好的模式名,就可以实现目的模式名的自定义了。
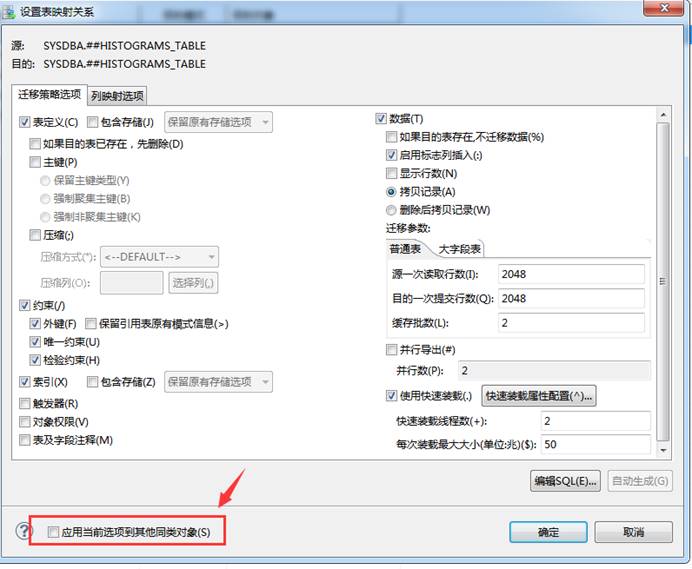
DTS 批量操作迁移所有表的表定义
DTS 转换的界面,还有个【应用到其它对象的按钮】的按钮,在左下角。如下图所示:
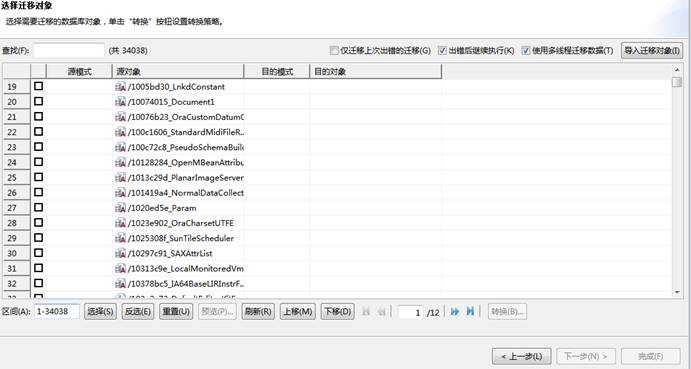
迁移对象有哪些
迁移对象如下图所示:
表/视图/序列对象是以不同的图标区分,如下图所示:
 表示“表”
表示“表”
 表示“视图”
表示“视图”
 表示“序列”
表示“序列”
 表示“存储过程”
表示“存储过程”
 表示“函数”
表示“函数”
 表示“包”
表示“包”
 表示“类”
表示“类”
 表示“同义词”
表示“同义词”
详细文档可在迁移工具的帮助文档中找到。
管理工具、DTS 缓存清理
在使用 DM 数据库管理工具和数据迁移工具时,清理工具缓存操作如下:
- 进入数据库安装目录下的 tool 目录。
dmdbms\tool\configuratio,把里面的除config.ini和org.eclipse.equinox.simpleconfigurator的其他目录删掉。dmdbms\tool\workspace,把里面的除local的其它目录删掉。
PG12 向 DM 迁移无法显示源端
【问题描述】:
PG12 向 DM 迁移的时候,无法显示源端的模式,并且不能迁移成功,一直报分析表失败的错。
【解决方法】:
需要更新 PG 驱动。
迁移数据至 DM MPP 集群提示随机分布表不能建唯一索引
DTS 工具分发方式设置成 HASH 分布即可。
报错:表或视图不存在
- 如果是用 DTS 做数据迁移报错:需要在源端查看用户是否有权限;
- 如果用驱动访问达梦数据库报错:要考虑是否是跨模式访问,给表加上模式名;
- dimp 导入数据时报错:考虑大小写敏感的问题和权限问题。
Sybase 迁移到 DM
可以参考:Sybase 迁移到 DM7
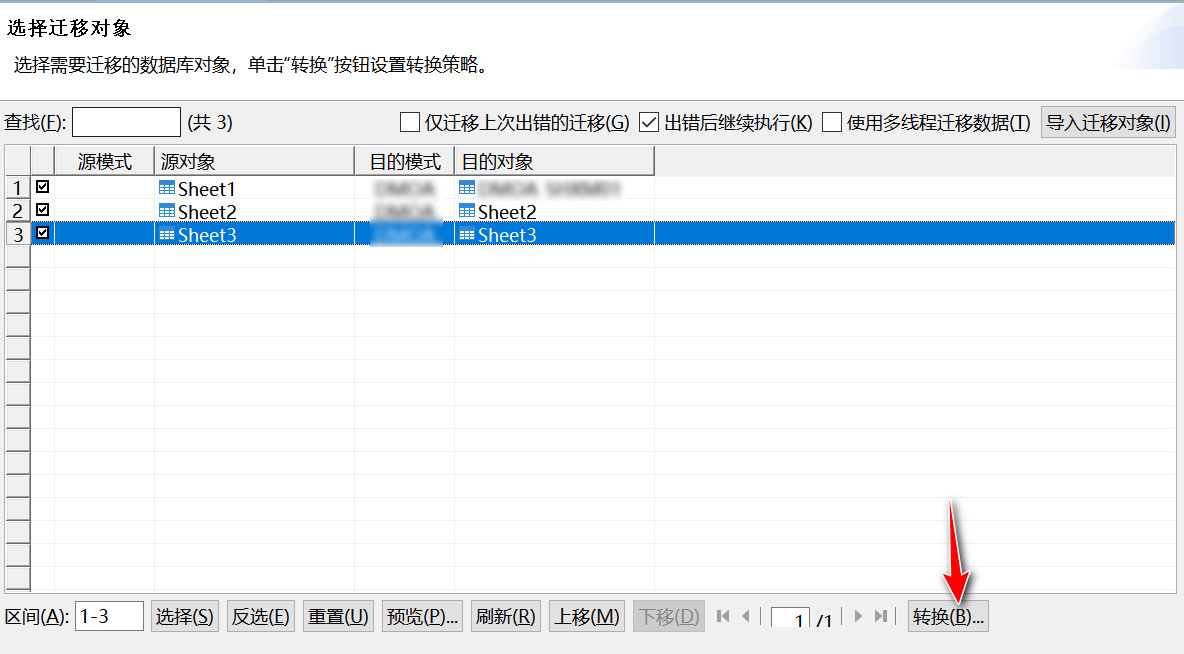
如何先删除旧表的记录 ,再迁移数据
在迁移的“转换”页面,然后选择“如果目的表已存在,先删除”
Excel 表中数据粘贴到数据库表
当 Excel 表中数据列顺序与数据库表中列一致时,可以采用 DM 数据库自带的 DTS 迁移工具进行迁移,迁移时选择 Excel-DM 即可。

神通数据库 date 类型数据迁移到 DM 时,时间精度丢失
【问题原因】:
神通数据库的 date 类型精确到时分秒,DTS 迁移工具转换成 DM 的 date 类型是没有时分秒的,导致 time 时间精度丢失。
【问题解决】:
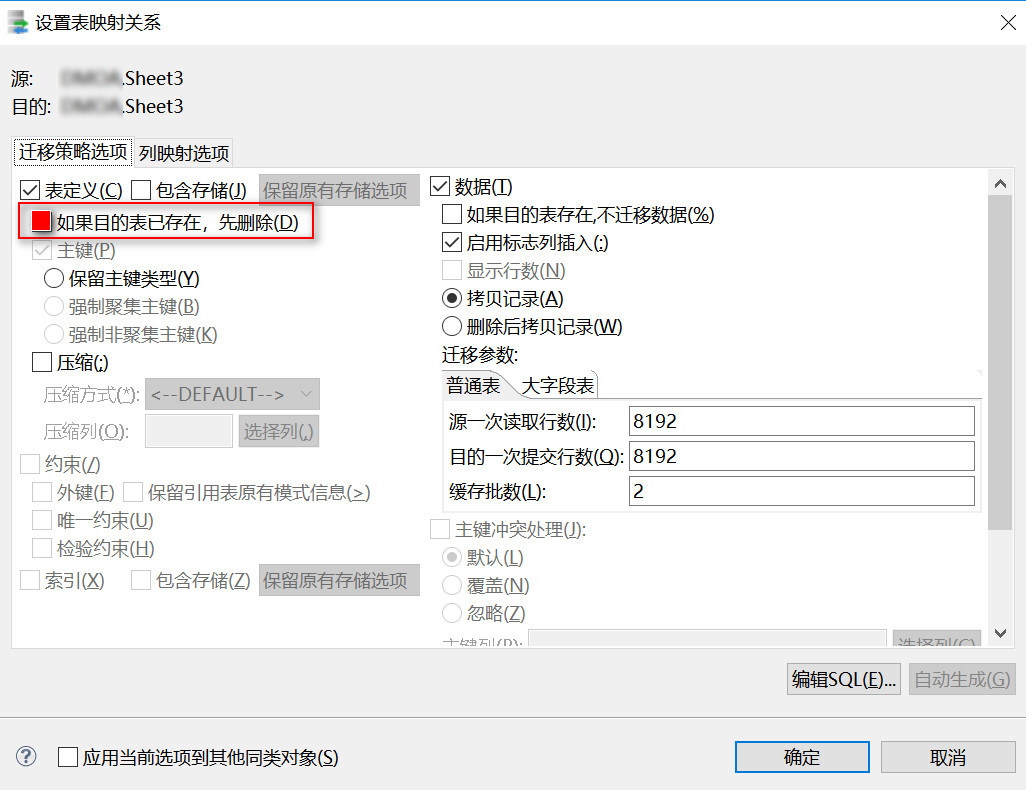
指定神通数据库驱动,同时迁移过程强制转换神通数据库的 date 类型为达梦数据库的 timestamp 类型。在数据类型映射的 ShenTong——DM 中,添加 date 到 timestamp(6) 的数据类型映射。

在迁移界面取消勾选使用默认数据类型映射关系,就可以使用手动添加的数据类型映射了。
若要迁移某个包,如何查询所对应的依赖对象的 DDL 语句
【问题描述】:
当需要重现某个包或者存储过程问题时,可能需要单独迁移个别包、存储过程到测试环境。当需要被迁移的某个包的依赖对象较多时,不建议手动拷贝,那如何高效迁移?
【问题分析】:
这种情况需要明确所涉及对象 DDL 语句,以此可以在测试环境中进行问题重现。可通过以下语句获取:
select
objs.ID,
CAST(dbms_metadatA.get_ddl(dobjs.refed_type$,objs.name,sobjs.name) AS VARCHAR)
from
(
select * from sysdependencies where id = (select object_id from DBA_OBJECTS t
where t.OWNER = '所属用户' and t.object_name = '对象名' and object_type = 'PACKAGE BODY')
)
dobjs
left join sysobjects objs
on
dobjs.refed_id = objs.id
left join sysobjects sobjs
on
objs.schid = sobjs.id
and objs.schid != 0
利用 DTS 迁移工具,从 postgresql 到 DM 数据的迁移报错:时间类型错误
【问题描述】:
利用 DTS 迁移工具,从 postgresql 到 DM 数据的迁移报时间类型错误。但源表和目的表字段类型都一致,看日志提示已迁移部分记录成功,目的数据库查询也能查到迁移成功的部分记录但记录不全,如何定位问题在哪?
【问题分析】:
通过以下步骤进行检查:
步骤 1:将目的表中所有 timestamp 类型字段修改成 varchar 类型后,重新导入数据成功;
步骤 2:将步骤 1 中修改的的字段类型 还原为 timestamp 字段,看哪个还原成 timestamp 字段有报错;
步骤 3:找出修改字段类型报“非法的时间日期类型数据”的错误;
步骤 4:检查步骤 3 找出的该字段数据,通过 isdate()函数 查看是否有非日期型数据;
步骤 5:若检查到有非日期型异常记录,源端修改记录数据在 timestamp 范围内后,重新导入。例如,经检查有条非日期型异常记录是'20019-01-01 00:00:00',该数据在 postgre 中认为是有效的日期型数据,能存储在 timestamp 字段中。
注意达梦 TIMESTAMP/DATETIME 类型包括年、月、日、时、分、秒信息,定义了一个在'-4712-01-01 00:00:00.000000'和'9999-12-31 23:59:59.999999'之间的有效日期时间;'20019-01-01 00:00:00' 中的年份不在此范围内,所以会出现迁移报时间类型错误,而 postgre 中定义的有效的日期型数据精度较为广泛,能存储在 timestamp 字段中,此类错误很隐蔽,需要逐一排查数据才能定位到问题。
Postgresql 视图迁移到 DM 报错: string index out of range:17
【问题分析】:
首先查看日志,获取视图脚本,在 disql 中执行,获取更详细的报错信息,定位到是语法分析错误,再进行语法修正即可。
例如视图对应相关基表的建表脚本为:
create table test(a INTEGER,b INTEGER);
dts 生成的视图脚本:
create or replace view v_test as(select a::text||b::text from test);
Postgresql 中数值型字段不允许直接拼接,需要强制转换为字符或文本型才允许拼接。而达梦无相关转换语法,数字型字段可直接拼接,所以将 ::text 的强制转换直接去掉即可。修正后的视图脚本:
create or replace view v_test as(select a||b from test);
Postgresql 源表中有字段定义默认值约束为序列的,将表结构迁移到 DM 时报错:default 约束表达式无效
【问题分析】:
出现该问题是由于目的端 DTS 的登录账号和迁移表的模式不属于同一个,脚本中的 DEFAULT 序列名.NEXTVAL 无法找到,需要加上模式名,即 DEFAULT 模式名.序列名.NEXTVAL。
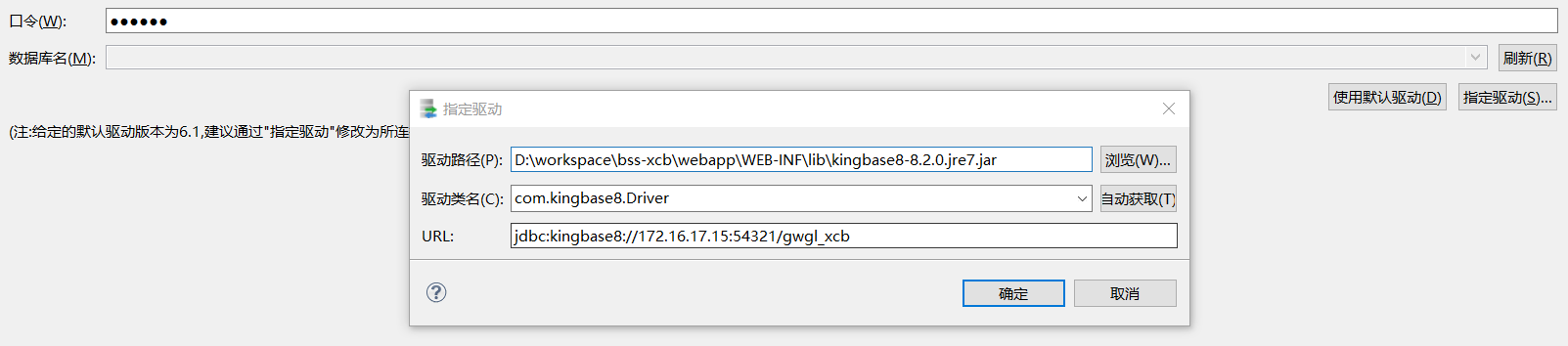
使用 dts 从人大金仓迁移到 DM,报错:com.kingbase8.jdbc.KbArray cannot be cast to dm.jdbc.driver.DmdbArray
【问题解决】:
在进行 DTS 迁移时,需要指定人大金仓和 DM 数据库的驱动包,如下图所示:
通过 VNC 实现在服务器端使用 DTS 进行数据迁移
【问题描述】
在具有大数据量上的项目上进行迁移时,如果 DTS 部署在客户端或中转机上,由于客户端与中转机上的内存或 CPU 或网络资源存在瓶颈,导致迁移速度慢,迁移易中断;此时如果在条件允许的情况下,可利用服务器上充足的资源使用 DTS 迁移,可大幅提升迁移效率。
【解决方法】
这里以在 kylinV10 上部署 VNCserver 为例:
- 下载安装 VNCserver
方式一:yum install tigervnc-server 。
方式二:通过提前准备好的 vnc 安装包进行安装。
[root@localhost ~]#rpm -ivh tigervnc-server-1.10.1-5.p02.ky10.aarch64.rpm
- 启动 VNC 服务和设置密码
root@localhost 桌面]# vncserver
You will require a password to access your desktops.
Password:(这里设置密码)
Verify:(这里确认密码)
Would you like to enter a view-only password (y/n)? n(询问你是否要再输入一个只有观看权限而被禁止操作远程桌面的密码。一般我们都不需要这样的一个只能看屏幕的权限,所以此处输入n)
New 'localhost.localdomain:1 (user)' desktop is localhost.localdomain:1
Creating default startup script /root/.vnc/xstartup
Creating default config /root/.vnc/config
Starting applications specified in /root/.vnc/xstartup
Log file is /root/.vnc/localhost.localdomain:1.log
- 查询 VNC 端口,这里显示为 5901
[root@localhost ~]# netstat -nltp |grep vnc
- 通过 VNC 客户端进行连接:输入 ip+ 端口 后,输入密码后进入服务器界面。
输入用户名和密码进入主界面。
- 在 shell 中切换到 dmdba 用户,对 DISPLAY 变量进行赋予后,既可使用 dts 进行迁移。
DB2 数据库迁移至 DM 报错:java.io.CharConversionException
【问题描述】
DB2 数据库迁移至 DM,迁移过程中报错:java.io.CharConversionException
【问题解决】
在 DTS 的配置文件中添加参数 -Ddb2.jcc.charsetDecoderEncoder=3
Linux 下: dmdbms/tool/dts 添加参数
Windows 下:dmdbms/tool/dts.ini 添加参数
非法的函数调用序列
【问题描述】
dm 到 dm ,dmp 迁移,导入时报错:"非法的函数调用序列"。
【问题分析】
该问题可能由两种情况导致:
- 源端表中有乱码数据;
- 源端表中同时包含了 date 和 clob 类型数据,且源端和目的端数据库兼容模式不一致。
【问题解决】
- 检查源端表中是否存在乱码,如果有乱码数据且包含乱码的数据比较少,建议手动删除数据中的乱码部分,重新迁移;如果乱码比较多,考虑是否可以通过备份还原的方式迁移数据。
- 检查数据库兼容模式,兼容模式不一致的情况下,可将目的端兼容模式改为和源端一致。
PgSQL 迁移到 dm 后,如何实现 string_to_array 函数功能
【问题描述】
PgSQL 迁移到 dm 后,如何实现 string_to_array 函数功能。
【问题解决】
可通过创建自定义同名函数来实现 string_to_array 函数功能,具体如下:
CREATE or replace TYPE "SPLIT_TYPE"
IS
TABLE OF VARCHAR2 (4000);
CREATE OR REPLACE
FUNCTION "string_to_array"
(
p_str IN VARCHAR2,
p_delimiter IN VARCHAR2 DEFAULT
(
',') --分隔符,默认逗号
)
RETURN split_type
IS
j INT := 0;
i INT := 1;
LEN INT := 0;
len1 INT := 0;
str VARCHAR2 (4000);
my_split split_type := split_type ();
BEGIN
LEN := LENGTH (p_str);
len1 := LENGTH (p_delimiter);
WHILE j < LEN
LOOP
j := INSTR (p_str, p_delimiter, i);
IF j = 0 THEN
j := LEN;
str := SUBSTR (p_str, i);
my_split.EXTEND;
my_split(my_split.COUNT) := str;
IF i >= LEN THEN
EXIT;
END IF;
ELSE
str := SUBSTR (p_str, i, j - i);
i := j + len1;
my_split.EXTEND;
my_split(my_split.COUNT) := str;
END IF;
END LOOP;
RETURN my_split;
END;
PgSQL 中的 string_to_array && string_to_array 用法如何在 dm8 当中实现
【问题描述】
PgSQL 中的 string_to_array && string_to_array 用法如何在 dm8 当中实现。
【问题解决】
可通过创建自定义函数来实现 string_to_array && string_to_array 的相同功能,具体如下:
CREATE OR REPLACE
FUNCTION FIND_SET_IN_SET
(
piv_str1 VARCHAR2,
piv_str2 VARCHAR2,
p_sep VARCHAR2 := ',')
RETURN NUMBER
IS
l_idx NUMBER:=0; -- 用于计算piv_str2中分隔符的位置
h_idx NUMBER:=0; -- 用于计算piv_str1中分隔符的位置
str VARCHAR2(500); -- 根据分隔符截取的子字符串
aimstr VARCHAR2(500); -- 根据分隔符截取的子字符串
piv_str VARCHAR2(500) := piv_str2; -- 将piv_str2赋值给piv_str
aim_str VARCHAR2(500) := piv_str1; -- 将piv_str2赋值给piv_str
res NUMBER :=0; -- 返回结果
loopIndex NUMBER :=0;
BEGIN
IF instr(piv_str, p_sep, 1) = 0 AND instr(aim_str, p_sep, 1) = 0 THEN
IF piv_str = aim_str THEN
res := 1;
RETURN res;
END IF;
RETURN res;
ELSE
LOOP
l_idx := instr(piv_str, p_sep);
loopIndex:=loopIndex+1;
IF l_idx > 0 THEN
-- 截取第一个分隔符前的字段str
str :=SUBSTR(piv_str, 1, l_idx-1);
aim_str := piv_str1;
LOOP
h_idx := instr(aim_str, p_sep);
aimstr := SUBSTR(aim_str, 1, h_idx-1);
IF h_idx > 0 THEN
IF str = aimstr THEN
res:= loopIndex;
RETURN res;
END IF;
aim_str := SUBSTR(aim_str, h_idx+LENGTH(p_sep));
ELSE
IF str = aim_str THEN
res:= loopIndex;
RETURN res;
END IF;
EXIT;
END IF;
END LOOP;
ELSE
str :=piv_str;
aim_str := piv_str1;
LOOP
h_idx := instr(aim_str, p_sep);
aimstr := SUBSTR(aim_str, 1, h_idx-1);
IF h_idx > 0 THEN
IF str = aimstr THEN
res:= loopIndex;
RETURN res;
END IF;
aim_str := SUBSTR(aim_str, h_idx+LENGTH(p_sep));
ELSE
IF str = aim_str THEN
res:= loopIndex;
RETURN res;
END IF;
RETURN res;
END IF;
END LOOP;
END IF;
piv_str := SUBSTR(piv_str, l_idx+LENGTH(p_sep));
END LOOP;
END IF;
END FIND_SET_IN_SET;
使用 DTS 将 pg 空间类型数据迁移到 DM 时报错:“函数 st_asbinary(country.geometry) 不存在”
【问题描述】
从 pg 迁移空间类型数据到 DM 时,dts 报错“函数 st_asbinary(country.geometry) 不存在,建议:没有匹配指定名称和参数类型的函数. 您也许需要增加明确的类型转换.”。
【问题分析】
dts 迁移 pg 空间类型数据时需要调用到 pg 的 st_asbinary 函数,而 pg 数据库的 st_asbinary 函数是在扩展了 postgis 的模式下使用,比如在 pg 中执行 create extension postgis schema country; 后,那么就可以在 country 模式下执行该函数。
【问题解决】
方式一:在 dts 连接时添加 url 连接属性指定使用的模式 searchpath=country 再尝试迁移。如果该方法无法解决该问题,可以尝试方式二进行解决。
方式二:在 pg 中执行如下 SQL 后,再将空间类型数据的表导入到 public 模式下再尝试迁移。
drop extension postgis cascade;
create extension postgis schema public;
使用 DTS 将 pg 迁移到 dm 报错时间类型转换类型不匹配
【问题描述】
pg 迁移到 dm 报错时间类型转换类型不匹配:timestamp with time zone 类型,数据为 1990-01-01 01:00:00.201+8:00。
【问题解决】
该问题是由于时区前无空格导致,先调整表结构为 varchar 绕过,将数据迁移过后修改类型为 timestamp with time zone。
使用 DTS 将 pg 迁移到 DM,迁移后部分 varchar 字段为空
【问题描述】
使用 DTS 将 pg 迁移到 DM 后部分 varchar 字段为空。
【问题解决】
DM 端是以字节为单位的库,需要扩充 varchar 的精度或者迁移时将 varchar 设置为以字符为单位。
kafka 通过 etl 迁移数据时无法消费数据
【问题描述】
在配置完成转换工程时,kafka 服务可以连接,无法消费 kafka 中数据,也没有报错。
数据:
作业:
目的端内容:
【问题分析】
kafka 监听配置中的 ip 地址为 localhost,仅允许本地消费者进行进消费数据。
【问题解决】
调整 kafka 监听配置中的 ip 地址为业务网络。
生产数据:
作业:
目的端内容:
MariaDB 包含中文列名的表迁移到 DM 报错:" Unknown column '????' in 'field list'"
【问题描述】
MariaDB 包含中文列名的表迁移到达梦报错: "Unknown column '????' in 'field list'"。
【问题分析】
DTS 内置驱动版本为 mysql5.1,与 MariaDB 存在兼容问题,可以通过指定对应的驱动版本来尝试解决。
【问题解决】
通过 MariaDB 官网下载对应版本的驱动包,在 DTS 软件中数据库连接页面,通过“指定驱动”功能,将 MariaDB 的驱动添加到“驱动路径”中,自动获取驱动类名,进行后续的迁移操作即可成功。
DB2 迁移到 DM 如何适配函数 timestampdiff
【问题描述】
如何将 DB2 中函数 timestampdiff 适配达梦,如下查询:
select timestampdiff(256, char(current timestamp - timestamp('2000-01-01-00.00.00.00'))) from sysibm.dual;
【问题分析】
在 DB2 中,TIMESTAMPDIFF 函数用于根据两个时间戳记之间的时差,返回由第一个参数定义的类型表示的估计时差。该函数返回的结果是一个整数,不过它存在一定局限性,其计算结果未考虑闰年情况,并且假设每个月都是 30 天,因此只能提供近似值。当 enddate 早于 startdate 时,函数会返回负整数。
语法:
{fn TIMESTAMPDIFF(interval-type, startdate, enddate)}
参数说明:
-
interval-type:返回值将表示的时间/日期间隔类型,可使用以下值(不区分大小写,可使用单引号或双引号指定):
SQL_TSI_FRAC_SECOND:以千分之一秒的整数计数形式返回小数秒的差异(精度为三位数),%PosixTime 值始终包含六位精度。 毫秒 1
SQL_TSI_SECOND:秒 2
SQL_TSI_MINUTE:分钟 4
SQL_TSI_HOUR:小时 8SQL_TSI_DAY:天 16
SQL_TSI_WEEK:周 64
SQL_TSI_MONTH:月 128
SQL_TSI_YEAR:年 256
-
startdate:时间戳值表达式,可以是 %Library.TimeStamp 数据类型格式(yyyy-mm-dd hh:mm:ss.ffff)或 %Library.PosixTime 数据类型格式(编码的 64 位有符号整数)。若该参数仅指定时间值且 interval-type 指定日期间隔(天、周、月或年),则在计算结果间隔计数之前,时间戳的缺失日期部分默认为 “1900–01–01”。
-
enddate:将与 startdate 进行比较的时间戳值表达式,数据类型要求同 startdate。若该参数仅指定日期值且 interval-type 指定时间间隔(小时、分钟、秒、小数秒),则在计算结果间隔计数之前,时间戳的缺失时间部分默认为 “00:00:00.000”。
在 DM8 中函数 TIMESTAMPDIFF 表示返回一个表明 timestamp2 与 timestamp1 之间的指定 datepart 类型时间间隔的整数。
语法:
TIMESTAMPDIFF(datepart,timestamp1,timestamp2)
datepart 的取值如下:
| datepart 取值 | datepart 意义 |
|---|---|
| YEAR、YYYY、YY、SQL_TSI_YEAR | 年 |
| MONTH、MM、M、SQL_TSI_MONTH | 月 |
| DAY、DD、D、SQL_TSI_DAY | 日 |
| HOUR、HH、SQL_TSI_HOUR | 时 |
| MINUTE、MI、N、SQL_TSI_MINUTE | 分 |
| SECOND、S、SS、SQL_TSI_SECOND | 秒 |
| MILLISECOND、MS、SQL_TSI_FRAC_SECOND | 毫秒 |
| MICROSECOND、US | 微秒 |
| QUARTER、QQ、Q、SQL_TSI_QUARTER | 所处的季度 |
| DAYOFYEAR、DY、Y | 在年份中所处的天数 |
| WEEK、WK、WW、SQL_TSI_WEEK | 在年份中所处的周数 |
| WEEKDAY、DW | 在一周中所处的天数 |
【问题解决】
如 DB2 中查询:
select timestampdiff(256, char(current timestamp - timestamp('2000-01-01-00.00.00.00'))) from sysibm.dual;
修改到 DM8:
select timestampdiff(month,to_date('2000-01-01-00.00.00.00','yyyy-mm-dd-HH24:MI:SS'), sysdate ) from dual;
函数 TO_DATE 解释:
语法:TO_DATE(char [,fmt[,'nls']])
功能:将 CHAR 或者 VARCHAR 类型的值转换为 DATE 数据类型。TO_DATE 的结果不带小数秒精度。
参数 NLS:指定日期时间串的语言类型,取值:AMERICAN、ENGLISH 或 SIMPLIFIED CHINESE,分别表示美式英语、英语和简体中文,其中 AMERICAN 和 ENGLISH 的效果相同。例如,当将日期时间串指定为 2022-DECEMBER-12 时,应将 NLS 设置为 AMERICAN 或 ENGLISH。缺省为 SIMPLIFIED CHINESE。 这个参数的使用形式是:“NLS_DATE_LANGUAGE=''语言类型''”。更多参数说明可参考《DM8 SQL 语言使用手册》函数 TO_DATE。