数据查询是数据库的核心操作,DM_SQL 语言提供了功能丰富的查询方式,满足实际应用需求。几乎所有的数据库操作均涉及到查询,因此熟练掌握查询语句的使用是数据库从业人员必须掌握的技能。
在 DM_SQL 语言中,有的定义语法中也包含查询语句,如视图定义语句、游标定义语句等。为了区别,我们将这类出现在其它定义语句中的查询语句称查询说明。
每种查询都有适用的场景,使用得当会大大提高查询效率。为方便用户的使用,本章对 DM_SQL 语言支持的查询方式进行讲解,测例中所用基表及各基表中预先装入的数据参见第 2 章 手册中的示例说明,各例的建表者均为用户 SYSDBA。
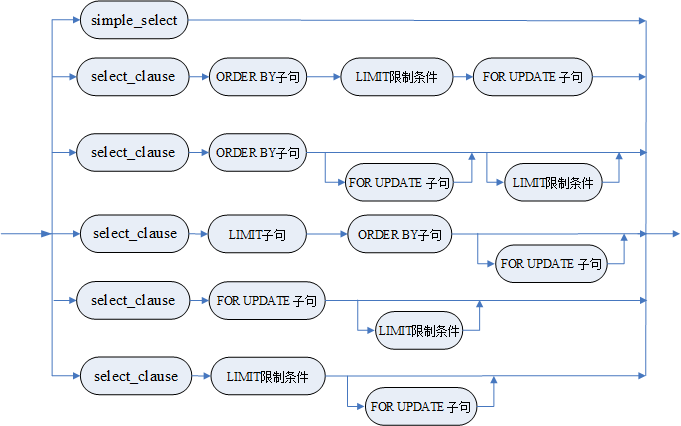
查询语句的语法如下:
<查询表达式>::=
<simple_select>|
<select_clause> <ORDER BY子句> <LIMIT限定条件> <FOR UPDATE 子句> |
<select_clause> <ORDER BY子句> [<FOR UPDATE 子句>] [<LIMIT限定条件>] |
<select_clause> <LIMIT子句> <ORDER BY 子句> [<FOR UPDATE 子句>] |
<select_clause> <FOR UPDATE 子句> [<LIMIT限定条件>] |
<select_clause> <LIMIT限定条件>[<FOR UPDATE 子句>]
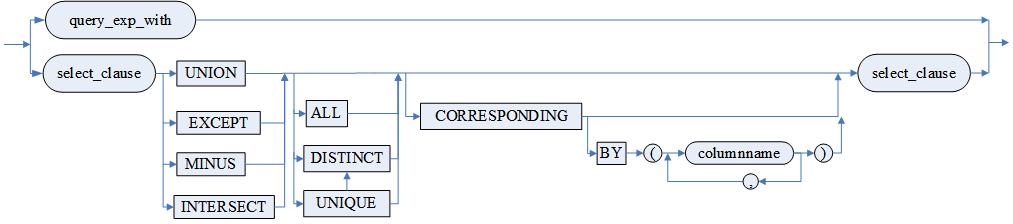
<simple_select> ::=
<query_exp_with>|
<select_clause><集合运算符>[ALL | DISTINCT | UNIQUE] [CORRESPONDING [BY (<列名> {,<列名>})]] <select_clause>
<select_clause>::=
<simple_select>|
(<查询表达式>)|
(<select_clause>)
<集合运算符>::=UNION| EXCEPT | MINUS | INTERSECT
<ORDER BY 子句>::= ORDER [SIBLINGS] BY <order_by_list>
<order_by_list>::= <order_by_item >{,<order_by_item>}
<order_by_item>::= <exp> [COLLATE <collation_name>] [ASC|DESC] [NULLS FIRST|LAST]
<exp>::=<列说明>|<无符号整数>|<值表达式>|<布尔表达式>
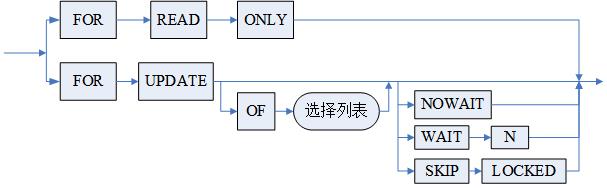
<FOR UPDATE 子句> ::=
FOR READ ONLY|
FOR UPDATE [OF <选择列表>] [NOWAIT | WAIT N |[N] SKIP LOCKED]
<LIMIT限定条件>::= <LIMIT子句>|<ROW_LIMIT子句>
<LIMIT子句>::= LIMIT <记录数> |
LIMIT <偏移量>, <记录数> |
LIMIT <记录数> OFFSET <偏移量> |
OFFSET <偏移量> LIMIT <记录数>
<记录数>::= <整数>
<偏移量>::= <整数>
<ROW_LIMIT子句>::= [OFFSET <offset> ROW[S] ] [<FETCH说明>]
<FETCH说明>::= FETCH <FIRST | NEXT> [<大小> | <大小> PERCENT] ROW[S] <ONLY | WITH TIES>
<query_exp_with>::=[<WITH 子句>] SELECT [<HINT 子句>] [ALL | DISTINCT | UNIQUE] [<TOP子句>] <选择列表>[<bulk_or_single_into_null>] <select_tail>
<选择列表> ::= [[<模式名>.]<基表名> | <视图名> .] * | <值表达式> [[AS] <列别名>]
{,[[<模式名>.]<基表名> | <视图名>.] * | <值表达式> [[AS] <列别名>]}
<WITH 子句> ::= [<WITH FUNCTION子句>] [<WITH CTE子句>] 请参考第4.4节 WITH 子句
<HINT 子句> ::=/*+ hint{hint}*/
<TOP子句>::=
TOP <n> |
<<n1>,<n2>>|
<n> PERCENT|
<n> WITH TIES|
<n> PERCENT WITH TIES
<n>::=整数(>=0)
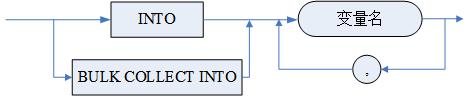
<bulk_or_single_into_null>::=<bulk_or_single_into> <变量名 >{,<变量名>}
<bulk_or_single_into>::= <INTO>| <BULK COLLECT INTO>
<select_tail>::= <FROM子句>[<WHERE子句>][<层次查询/GROUP BY/HAVING组合子句>]
<FROM子句>::= FROM <表引用>{,<表引用>}
<表引用>::=<普通表>|<连接表>
<普通表>::=<普通表1>|<普通表2>|<普通表3>| ARRAY <数组> | TABLE(<collection_exp>)
<普通表1>::=<对象名> [<SAMPLE子句>][[[AS] <别名>] <PIVOT子句>][[[AS] <别名>] <UNPIVOT子句>] [<闪回查询>] [[AS] <别名>]
<普通表 2>::=(<查询表达式>)[[AS <别名>] <PIVOT子句>][[AS <别名>] <UNPIVOT子句>] [<闪回查询>][[AS] <表别名> [<新生列>]]
<普通表3>::=[<模式名>.]<<基表名>|<视图名>>(<选择列>)[[AS <别名>] <PIVOT子句>] [[AS <别名>] <UNPIVOT子句>] [<闪回查询>] [[AS] <表别名> [<派生列表>]]
<对象名>::=<本地对象> | <索引> | <分区表>
<本地对象>::=[<模式名>.]<基表名|视图名>
<索引>::=[<模式名>.]<基表名> INDEX <索引名>
<分区表>::=
[<模式名>.]<基表名> PARTITION (<一级分区名>) |
[<模式名>.]<基表名> PARTITION FOR (<表达式>,{<表达式>})|
[<模式名>.]<基表名> SUBPARTITION (<子分区名>)|
[<模式名>.]<基表名> SUBPARTITION FOR (<表达式>,{<表达式>})
<选择列>::=<列名>[{,<列名> }]
<派生列表>::=(<列名>[{,<列名>}])
<SAMPLE子句>::=
SAMPLE(<表达式>) |
SAMPLE(<表达式>) SEED (<表达式>) |
SAMPLE BLOCK(<表达式>) |
SAMPLE BLOCK(<表达式>) SEED (<表达式>)
<闪回查询>::= <闪回查询子句>|<闪回版本查询子句>请参考17.2 闪回查询
<闪回查询子句>::=
WHEN <TIMESTAMP time_exp> |
AS OF <TIMESTAMP time_exp> |
AS OF <SCN|LSN lsn>
<闪回版本查询子句>::=VERSIONS BETWEEN <TIMESTAMP time_exp1 AND time_exp2> | <SCN|LSN lsn1 AND lsn2>
<连接表>::=<交叉连接>|
<限定连接>|
<join_apply_item>|
(<交叉连接>)|
(<限定连接>)|
(<join_apply_item>)
<交叉连接>::=<表引用> CROSS JOIN <普通表>|
<表引用> CROSS JOIN (<连接表>)
<限定连接>::=<表引用> NATURAL JOIN <普通表>|
<表引用> NATURAL JOIN (<连接表>)|
<表引用> NATURAL <连接类型> JOIN <普通表>|
<表引用> NATURAL <连接类型> JOIN (<连接表>)|
<表引用> JOIN <表引用> <限定连接条件>|
<表引用>[<PARTITION JOIN子句>] <限定连接类型> JOIN <表引用> [<PARTITION JOIN子句>] <限定连接条件>
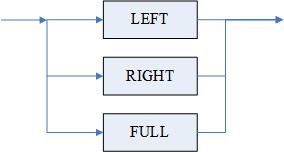
<限定连接类型>::= [<内外连接类型>] INNER|
<内外连接类型> [OUTER]
<内外连接类型>::=LEFT|RIGHT|FULL
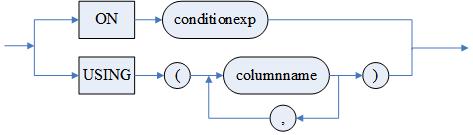
<限定连接条件>::=<条件匹配>|<列匹配>
<条件匹配>::=ON<搜索条件>
<列匹配>::=USING(<连接列列名>{, <连接列列名>})
<join_apply_item>::=
<表引用> CROSS APPLY <普通表>|
<表引用> CROSS APPLY (<连接表>)|
<表引用> OUTER APPLY <普通表>|
<表引用> OUTER APPLY (<连接表>)
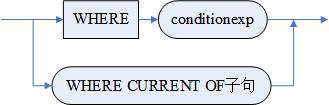
<WHERE子句> ::=
WHERE <搜索条件>|
< WHERE CURRENT OF子句>
<搜索条件>::=<逻辑表达式>
<WHERE CURRENT OF子句>::= WHERE CURRENT OF <游标名>
<层次查询/GROUP BY/HAVING组合子句>::=
[<层次查询子句>] [<GROUP BY子句>] [<HAVING子句>] |
[<层次查询子句>] [<HAVING子句>] [<GROUP BY子句>] |
[<GROUP BY子句>] [<HAVING子句>] [<层次查询子句>] |
[<GROUP BY子句>] [<层次查询子句>] [<HAVING子句>] |
[<HAVING子句>] [<GROUP BY子句>] [<层次查询子句>] |
[<HAVING子句>] [<层次查询子句>] [<GROUP BY子句>]
<层次查询子句>::=
CONNECT BY [NOCYCLE] <连接条件>[START WITH <起始条件> ] |
START WITH <起始条件> CONNECT BY [NOCYCLE] <连接条件>
<连接条件>::=<逻辑表达式>
<起始条件>::=<逻辑表达式>
<GROUP BY 子句> ::= GROUP BY <group_by项>
<group_by项>::=<group_by子项 > {,<group_by子项>}
<group_by子项>::=<group_by分组项> | <ROLLUP项> | <CUBE项> |<GROUPING SETS项>
<group_by分组项>=<分组项集>|
<分组项集>{,<分组项集>}
<分组项集>::=<分组项>|(<分组项>{,<分组项>})| ()
<分组项>::=<列说明> | <无符号整数>
<ROLLUP项>::=ROLLUP (<rollup分组项>)
<rollup分组项>::= <列说明> | <无符号整数>
<CUBE项>::=CUBE (<cube分组项>)
<cube分组项>::= <列说明> | <无符号整数>
<GROUPING SETS项>::=GROUPING SETS(<group_by分组项>)
<HAVING 子句> ::= HAVING <搜索条件>
<PARTITION JOIN子句> ::=PARTITION BY (<表列名>{,<表列名>})
<PIVOT子句> ::= PIVOT [XML] (<set_func_clause> FOR <pivot_for_clause> IN (<pivot_in_clause>))
<set_func_clause> ::= <集函数> [[AS] <别名>] {,<集函数> [[AS] <别名>]}
<pivot_for_clause> ::=
<列名> |
(<列名> {,<列名>})
<pivot_in_clause> ::=
<exp_clause> [[AS] <别名>] {,<exp_clause> [[AS] <别名>]} |
<select_clause> |
ANY
<exp_clause> ::=
<表达式> |
(<表达式> {,<表达式>})
<UNPIVOT子句> ::= UNPIVOT [<include_null_clause>](<unpivot_val_col_lst> FOR <unpivot_for_clause> IN (<unpivot_in_clause_low> ))
<include_null_clause> ::=
INCLUDE NULLS |
EXCLUDE NULLS
<unpivot_val_col_lst> ::=
<表达式> |
(<表达式> {,<表达式>})
<unpivot_for_clause> ::=
<表达式> |
(<表达式> {,<表达式>})
<unpivot_in_clause_low> ::= <unpivot_in_clause>{,<unpivot_in_clause>}
<unpivot_in_clause> ::=
<列名> [AS <别名>] |
(<列名> {,<列名>}) [AS (<别名> {,<别名>})]
参数
- < 集合运算符 > 包括并集 UNION、差集 EXCEPT、差集 MINUS 和交集 INTERSECT。具体请参考 4.5 集合查询;
- ALL|DISTINCT|UNIQUE 用于集合查询中。ALL 表示集合查询结果中保持所有重复;DISTINCT 表示删除所有重复。DISTINCT 与 UNIQUE 等价。缺省为 DISTINCT;
- CORRESPONDING 用于指定列名链表,通过指定列名(或列名的别名)链表来对两个查询分支的查询项进行筛选。无论分支中有多少列,最终的结果集只包含 CORRESPONDING 指定的列。查询分支和 CORRESPONDING 的关系为:<查询分支 1> CORRESPONDING [BY (<列名> {,<列名>})]
<查询分支 2>。如果 CORRESPONDING 指定了列名但两个分支中没有相同列名的查询项则报错,如果 CORRESPONDING 没指定列名,则按照第一个分支的查询项列名进行筛选;例如:select c1, c2, c3 from t1 union all corresponding by (c1,c2) select d1, d2 c1, d3 c2 from t2; - <HINT 子句 > 用于使用优化器提示,HINT 可以设置为 INI 参数、索引、连接方法等;其中具体支持使用 HINT 的 INI 参数可通过查询 V$HINT_INI_INFO 动态视图获取,视图的 PARA_NAME 列展示参数名,HINT_TYPE 列展示支持的 HINT 类型;支持 HINT 的 INI 参数分为两类:一是 HINT_TYPE 为"EXEC",表示运行阶段使用的参数,需要放在最外层的 SELECT 语句中,置于 SELECT 子句中不生效;二是 HINT_TYPE 为"OPT",表示分析阶段使用的参数,不要求放在最外层的 SELECT 语句中,但其中部分参数需要保持全局一致,即需要和上层的参数值保持一致。需要保持全局一致的参数例如:并行度"PARALLEL";
- <模式名> 被选择的表和视图所属的模式,缺省为当前模式;
- <基表名> 被选择数据的基表的名称;
- <视图名> 被选择数据的视图的名称;
- < 索引名 > 指定查询语句所使用的索引的名称;
- * 指定对象的所有的列;
- <值表达式> 可以为一个<集函数>、<函数>、<标量子查询>或<计算表达式>等等;
- <列别名> 为列表达式提供不同的名称,使之成为列的标题,列别名不会影响实际的名称,别名在该查询中被引用;
- <表别名 > 给表、视图提供不同的名字,经常用于求子查询和相关查询的目的;
- <列名> 指明列的名称;
- <WHERE 子句> 限制被查询的行必须满足条件,如果忽略该子句,DM 从在 FROM 子句中的表、视图中选取所有的行;其中,<WHERE CURRENT OF 子句>专门用于游标更新、删除中,用来限定更新、删除与游标有关的数据行。
- <HAVING 子句> 限制所选择的行组所必须满足的条件,缺省为恒真,即对所有的组都满足该条件;
- <无符号整数> 指明了要排序的<值表达式>在 SELECT 后的序列号;
- <列说明> 排序列的名称;
- ORDER SIBLINGS BY 必须与 CONNECT BY 一起配合使用。可用于指定层次查询中相同层次数据返回的顺序。
- ASC 指明为升序排列,缺省为升序;
- DESC 指明为降序排列;
- nulls first 指定排序列的 null 值放在最前面,不受 asc 和 desc 的影响,缺省的是 nulls first;
- nulls last 指定排序列的 null 值放在最后面,不受 asc 和 desc 的影响;
- <PARTITION BY 子句> 指明分区外连接中的分区项,最多支持 255 个列;仅允许出现在左外连接右侧表和右外连接中的左侧表,且不允许同时出现,详见 4.2.7;
- BULK COLLECT INTO 的作用是将检索结果批量的、一次性的赋给集合变量。与每次获取一条数据,并每次都要将结果赋值给一个变量相比,可以很大程度上的节省开销。使用 BULK COLLECT 后,INTO 后的变量必须是集合类型;
- CROSS APPLY 是在 CROSS JOIN 的基础上增加了右表可以引用左表列的功能,即同层列引用;
- OUTER APPLY 是在 LEFT OUTER JOIN 的基础上增加了右表可以引用左表列的功能,即同层列引用。
图例
查询表达式(query_express)
simple_select
query_exp_with
select_clause
ORDER BY 子句
FOR UPDATE 子句
LIMIT 限定条件

LIMIT 子句
ROW LIMIT 子句

FETCH 说明
FROM 子句
表引用(from_table)
普通表(normal_table)
普通表 1(normal_table1)
普通表 2(normal_table2)
普通表 3(normal_table3)
连接表(joined_table)
交叉连接(cross_join_item)
限定连接(limit_join_item)
限定连接类型(limit_join_type)
内外连接类型(inner_outer_join_type)
限定连接条件(limit_join_condition)
join_apply_item
WHERE 子句
层次查询/GROUP BY/HAVING 组合子句
层次查询子句

GROUP BY 子句
ROLLUP 项
CUBE 项
GROUPING SETS 项
group_by 分组项(groupby_group_item)
group_item_set
HAVING 子句(having_clause)

WITH 子句(with_clause)

WITH FUNCTION 子句(with_function_clause)
WITH CTE 子句(with_cte_clause)
闪回查询
选择列表

bulk_or_single_into_null
PIVOT 子句(pivot_clause)
pivot_in_clause
UNPIVOT 子句(unpivot_clause)
unpivot_in_clause
使用说明
1.< 选择列表> 中最多可包含 2048 个查询项,且查询记录的长度限制不能超过块长的一半;
2.<FROM 子句>中最多可引用 100 张表;
3.WHERE<搜索条件>用于设置对于行的检索条件。不在规定范围内的任何行都从结果集中去除;
4.查询语句调用的函数中,不能包含任何增删改操作(包括函数间接调用其它过程\函数产生的增删改操作);
5.<bulk_or_single_into_null> 当前查询语句是在函数、过程等语句块内执行时,且 INTO 的变量名在上下文中并未定义时,该条查询语句会在当前语句块创建以该变量名为表名的局部临时表,并转换为局部临时表的查询插入语句,不再输出结果集。
4.1 单表查询
SELECT 语句仅从一个表/视图中检索数据,称单表查询。即<FROM 子句>中<普通表>使用的是[<模式名>.]<基表名|视图名>。
4.1.1 简单查询
例 查询所有图书的名字、作者及当前销售价格,并消去重复。
SELECT DISTINCT NAME, AUTHOR, NOWPRICE FROM PRODUCTION.PRODUCT;
其中,DISTINCT 保证重复的行将从结果中去除。若允许有重复的元组,改用 ALL 来替换 DISTINCT,或直接去掉 DISTINCT 即可。
查询结果如下(注:除带 Order By 的查询外,本书所示查询结果中各元组的顺序与实际输出结果中的元组顺序不一定一致):
NAME AUTHOR NOWPRICE
-------------------------------- -------------- --------
红楼梦 曹雪芹,高鹗 15.2
水浒传 施耐庵,罗贯中 14.3
老人与海 海明威 6.1
射雕英雄传(全四册) 金庸 21.7
鲁迅文集(小说、散文、杂文)全两册 鲁迅 20
长征 王树增 37.7
数据结构(C语言版)(附光盘) 严蔚敏,吴伟民 25.5
工作中无小事 陈满麒 11.4
突破英文基础词汇 刘毅 11.1
噼里啪啦丛书(全7册) (日)佐佐木洋子 42
当用户需要查出所有列的数据,且各列的显示顺序与基表中列的顺序也完全相同时,为了方便用户提高工作效率,SQL 语言允许用户将 SELECT 后的 < 值表达式 > 省略为*。
SELECT * FROM PERSON.PERSON;
等价于:
SELECT PERSONID, NAME, SEX, EMAIL, PHONE FROM PERSON.PERSON;
其查询结果是模式 PERSON 中基表 PERSON 的一份拷贝,结果从略。
4.1.2 带条件查询
带条件查询是指在指定表中查询出满足条件的元组。该功能是在查询语句中使用 WHERE 子句实现的。WHERE 子句常用的查询条件由谓词和逻辑运算符组成。谓词指明了一个条件,该条件求解后,结果为一个布尔值:真、假或未知。
逻辑运算符有:AND,OR,NOT、&&、!。其中 AND 和&&表示逻辑与运算、OR 表示逻辑或运算,NOT 和!表示逻辑非运算。
谓词包括比较谓词(=、>、<、>=、<=、<>、!=),BETWEEN 谓词、IN 谓词、LIKE 谓词、NULL 谓词、EXISTS 谓词。
1.使用比较谓词的查询
当使用比较谓词时,数值数据根据它们代数值的大小进行比较,字符串的比较则按序对同一顺序位置的字符逐一进行比较。若两字符串长度不同,短的一方应在其后增加空格,使两串长度相同后再作比较。
例 给出当前销售价格在 10~20 元之间的所有图书的名字、作者、出版社和当前价格。
SELECT NAME, AUTHOR, PUBLISHER, NOWPRICE FROM PRODUCTION.PRODUCT WHERE NOWPRICE>=10 AND NOWPRICE<=20;
查询结果如下:
NAME AUTHOR PUBLISHER NOWPRICE
------------------------------- -------------- ----------------- --------
红楼梦 曹雪芹,高鹗 中华书局 15.2
水浒传 施耐庵,罗贯中 中华书局 14.3
鲁迅文集(小说、散文、杂文)全两册 鲁迅 20
工作中无小事 陈满麒 机械工业出版社 11.4
突破英文基础词汇 刘毅 外语教学与研究出版社 11.1
2.使用 BETWEEN 谓词的查询
例 给出当前销售价格在 10~20 元之间的所有图书的名字、作者、出版社和当前价格。
SELECT NAME, AUTHOR, PUBLISHER, NOWPRICE FROM PRODUCTION.PRODUCT WHERE NOWPRICE BETWEEN 10 AND 20;
此例查询与上例完全等价,查询结果如上表所示。在 BETWEEN 谓词前面可以使用 NOT,以表示否定。
3.使用 IN 谓词的查询
谓词 IN 可用来查询某列值属于指定集合的元组。
例 查询出版社为中华书局或人民文学出版社出版的图书名称与作者信息。
SELECT NAME, AUTHOR FROM PRODUCTION.PRODUCT WHERE PUBLISHER IN ('中华书局', '人民文学出版社');
查询结果如下:
NAME AUTHOR
------ --------------
红楼梦 曹雪芹,高鹗
水浒传 施耐庵,罗贯中
长征 王树增
在 IN 谓词前面也可用 NOT 表示否定。
4.使用 LIKE 谓词的查询
LIKE 谓词一般用来进行字符串的匹配。我们先用实例来说明 LIKE 谓词的使用方法。
例 查询第一通讯地址中第四个字开始为“关山”且以 202 结尾的地址。
SELECT ADDRESSID, ADDRESS1, CITY, POSTALCODE FROM PERSON.ADDRESS WHERE ADDRESS1 LIKE '___关山%202';
查询结果如下:
ADDRESSID ADDRESS1 CITY POSTALCODE
----------- ---------------------- ------------ ----------
13 洪山区关山春晓55-1-202 武汉市洪山区 430073
14 洪山区关山春晓10-1-202 武汉市洪山区 430073
15 洪山区关山春晓11-1-202 武汉市洪山区 430073
由上例可看出,LIKE 谓词的一般使用格式为:
<列名> LIKE <匹配字符串常数>
其中,<列名>必须是可以转化为字符类型的数据类型的列。对于一个给定的目标行,如果指定列值与由<匹配字符串常数>给出的内容一致,则谓词结果为真。<匹配字符串常数>中的字符可以是一个完整的字符串,也可以是百分号“%”和下划线“_”,“%”和“_”称通配符。“%”代表任意字符串(也可以是空串);“_”代表任何一个字符。
因此,上例中的 SELECT 语句将从 ADDRESS 表中检索出第一通讯地址中第四个字开始为“关山”且以 202 结尾的地址情况。从该例我们可以看出 LIKE 谓词是非常有用的。使用 LIKE 谓词可以找到所需要的但又记不清楚的那样一些信息。这种查询称模糊查询或匹配查询。为了加深对 LIKE 谓词的理解,下面我们再举几例:
ADDRESS1 LIKE '%洪山%'
如果 ADDRESS1 的值含有字符“洪山”,则该谓词取真值。
POSTALCODE LIKE '43__7_'
如果 POSTALCODE 的值由六个字符组成且前两个字符为 43,第五个字符为 7,则该谓词取真值。
CITY LIKE '%汉阳_'
如果 CITY 的值中倒数第三和第二个字为汉阳,则该谓词取真值。
ADDRESS1 NOT LIKE '洪山%'
如果 ADDRESS1 的值的前两个字不是洪山,则该谓词取真值。
阅读以上的例子,读者可能就在想这样一个问题:如果<匹配字符串常数>中所含“%”和“_”不是作通配符,而只是作一般字符使用应如何表达呢?为解决这一问题,SQL 语句对 LIKE 谓词专门提供了对通配符“%”和“_”的转义说明,这时 LIKE 谓语使用格式为:
<列名> LIKE '<匹配字符串常数>' [ESCAPE <转义字符>]
其中,<转义字符>指定了一个字符,当该字符出现在<匹配字符串常数>中时,用以指明紧跟其后的“%”或“_”不是通配符而仅作一般字符使用。
例 查询第一通讯地址以 C1_501 结尾的地址,则 LIKE 谓词应为:
SELECT ADDRESSID, ADDRESS1, CITY, POSTALCODE FROM PERSON.ADDRESS WHERE ADDRESS1 LIKE '%C1*_501' ESCAPE '*';
在此例中,*被定义为转义字符,因而在<匹配字符串常数>中*号后的下划线不再作通配符,而是普通字符。
查询结果如下:
ADDRESSID ADDRESS1 CITY POSTALCODE
----------- ---------------------- ------------ ----------
16 洪山区光谷软件园C1_501 武汉市洪山区 430073
为避免错误,转义字符一般不要选通配符“%”、“_”或在 < 匹配字符串常数 > 中已出现的字符。
5.使用.ROW 进行 LIKE 谓词的查询
LIKE 谓词除支持使用列的计算外,还支持通过 ROW 保留字对表或视图进行 LIKE 计算。该查询依次对表或视图中所有字符类型的列进行 LIKE 计算,只要有一列符合条件,则返回 TRUE。
其语法的一般格式为
<表名>.ROW LIKE <匹配字符串> [ ESCAPE <转义字符>]
例 查询评论中哪些与曹雪芹有关
SELECT * FROM PRODUCTION. PRODUCT_REVIEW WHERE PRODUCT_REVIEW.ROW LIKE '%曹雪芹%';
该语句等价于
SELECT * FROM PRODUCTION. PRODUCT_REVIEW WHERE NAME LIKE '%曹雪芹%' OR EMAIL LIKE '%曹雪芹%' OR COMMENTS LIKE '%曹雪芹%';
6.使用 NULL 谓词的查询
空值是未知的值。当列的类型为数值类型时,NULL 并不表示 0;当列的类型为字符串类型时,NULL 也并不表示空串。因为 0 和空串也是确定值。NULL 只能是一种标识,表示它在当前行中的相应列值还未确定或未知,对它的查询也就不能使用比较谓词而须使用 NULL 谓词。
例 查询哪些人员的 EMAIL 地址为 NULL。
SELECT NAME, SEX, PHONE FROM PERSON.PERSON WHERE EMAIL IS NULL;
在 NULL 谓词前,可加 NOT 表示否定。
7. 组合逻辑
可以用逻辑运算符与各种谓词相组合生成较复杂的条件查询。
例 查询当前销售价格低于 15 元且折扣低于 7 或出版社为人民文学出版社的图书名称和作者。
SELECT NAME, AUTHOR FROM PRODUCTION.PRODUCT WHERE NOWPRICE < 15 AND DISCOUNT < 7 OR PUBLISHER='人民文学出版社';
查询结果如下:
NAME AUTHOR
------------ -------
老人与海 海明威
长征 王树增
工作中无小事 陈满麒
4.1.3 集函数
为了进一步方便用户的使用,增强查询能力,SQL 语言提供了多种内部集函数。当根据某一限制条件从表中导出一组行集时,使用集函数可对该行集作统计操作并返回单一统计值。
集函数经常与 SELECT 语句的 GROUP BY 子句一同使用。集函数对于每个分组只返回一行数据。
4.1.3.1 函数分类
集函数可分为 14 类:
- COUNT(*);
- 相异集函数 AVG|MAX|MIN|SUM|COUNT(DISTINCT< 列名>);
- 完全集函数 AVG|MAX|MIN| COUNT|SUM([ALL]< 值表达式>);
- 方差集函数 VAR_POP、VAR_SAMP、VARIANCE、STDDEV_POP、STDDEV_SAMP、STDDEV;
- 协方差函数 COVAR_POP、COVAR_SAMP、CORR;
- 首行函数 FIRST_VALUE;
- 任意行函数 ANY_VALUE;
- 求区间范围内最大值集函数 AREA_MAX;
- FIRST/LAST 集函数;
- 字符串集函数 LISTAGG/LISTAGG2、WM_CONCAT、COLLECT;
- 求中位数函数 MEDIAN。
- 线性回归相关 REGR 集函数 REGR_COUNT、REGR_AVGX、REGR_AVGY、REGR_SLOPE、REGR_INTERCEPT、REGR_R2、REGR_SXX、REGR_SYY、REGR_SXY。
- 百分比集函数 PERCENTILE_CONT、PERCENTILE_DISC。
- 位运算集函数 BIT_AND、BIT_OR、BIT_XOR。
4.1.3.2 使用说明
在使用集函数时要注意以下几点:
- 相异集函数与完全集函数的区别是:相异集函数是对表中的列值消去重复后再作集函数运算,而完全集函数是对包含列名的值表达式作集函数运算且不消去重复。缺省情况下,集函数均为完全集函数;
- 集函数中的自变量可以是集函数,但最多只能嵌套 2 层。嵌套分组函数的时候,需要使用 GROUP BY;
- AVG、SUM 的参数必须为数值类型;MAX、MIN 的结果数据类型与参数类型保持一致;对于 SUM 函数,如果参数类型为 BYTE、SMALLINT、INTEGER、BINARY 或 VARBINARY,那么结果类型为 BIGINT,如果参数类型为 FLOAT 或 DOUBLE,那么结果类型为 DOUBLE,如果参数类型为 NUMERIC 或 DEC,那么结果类型为 DEC;COUNT 的结果类型统一为 BIGINT;
对于 AVG 函数,其参数类型与结果类型对应关系如表 4.1.1 所示:
| 参数类型 | 结果类型 |
|---|---|
| tinyint | dec |
| smallint | dec |
| int | dec |
| bigint | dec |
| float | double |
| double | double |
| dec(x,y) | dec |
| binary | dec |
| varbinary | dec |
-
方差集函数中参数 expr 为<列名>或<值表达式>,具体用法如下:
1)VAR_POP(expr) 返回 expr 的总体方差。其计算公式为:
2)VAR_SAMP(expr)返回 expr 的样本方差,如果 expr 的行数为 1,则返回 NULL。其计算公式为:
3)**VARIANCE(expr)**返回 expr 的方差,如果 expr 的行数为 1,则返回为 0,行数大于 1 时,与 var_samp 函数的计算公式一致;
4)**STDDEV_POP(expr)**返回 expr 的标准差,返回的结果为总体方差的算术平方根,即 var_pop 函数结果的算术平方根。公式如下:
5)**STDDEV_SAMP(expr)**返回 expr 的标准差,返回的结果为样本方差的算术平方根,即 var_samp 函数结果的算术平方根,所以如果 expr 的行数为 1,stddev_samp 返回 NULL;
6)**STDDEV(expr)**与 stddev_samp 基本一致,差别在于,如果 expr 的行数为 1,stddev 返回 0,即 variance 函数结果的算术平方根。公式如下:
-
协方差集函数中参数 expr1 和 expr2 为 < 列名 > 或 < 值表达式 >,具体用法如下:
1)COVAR_POP(expr1, expr2) 返回 expr1 和 expr2 的总体协方差。其计算公式为:
2)**COVAR_SAMP(expr1, expr2)**返回 expr1 和 expr2 的样本协方差,如果 expr 的行数为 1,则返回 NULL。其计算公式为:
3)**CORR(expr1, expr2)**返回 expr1 和 expr2 的相关系数,如果 expr 的行数为 1,则返回 NULL。其计算公式为:
其中 NVL2(expr1, expr2,expr3)表示如果表达式 expr1 非空,NVL2 返回 expr2;如果表达式 expr1 为空,NVL2 返回 expr3。
-
FIRST_VALUE 集函数,返回查询项的第一行记录;
-
ANY_VALUE 集函数,实际返回查询项的第一行记录,等同于 FIRSTR_VALUE 集函数;
-
AREA_MAX(EXPR, LOW, HIGH) 在区间[LOW,HIGH]的范围内取 expr 的最大值。如果 expr 不在该区间内,则返回 LOW 值。如果 LOW 或 HIGH 为 NULL,则返回 NULL。expr 为< 变量>、< 常量>、< 列名> 或< 值表达式>。参数 expr 类型为 TINYINT、SMALLINT、INT、BIGINT、DEC、FLOAT、DOUBLE、DATE、TIME、DATETIME、BINARY、VARBINARY、INTERVAL YEAR TO MONTH、INTERVAL DAY TO HOUR、TIME WITH TIME ZONE、DATETIME WITH TIME ZONE。LOW 和 HIGH 的数据类型和 expr 的类型一致,如果不一致,则转换为 expr 的类型,不能转换则报错。此外,LOW 和 HIGH 仅支持常量表达式。AREA_MAX 集函数返回值定义如下:
| EXPR 集合 | 是否有在[LOW, HIGH] 区间内的非空值 | 结果 |
|---|---|---|
| 空集 | - | LOW |
| 非空 | 否 | LOW |
| 非空 | 是 | 在[LOW,HIGH]区间的最大值 |
| 分组前结果 | 在[LOW, HIGH] 区间内是否非空值 | 结果 |
|---|---|---|
| 空集 | - | 整个结果为空集 |
| 非空集 | 是 | 在[LOW,HIGH]区间的最大值 |
| 非空集 | 否 | LOW |
-
FIRST/LAST 集函数 首先根据 SQL 语句中的 GROUP BY 分组(如果没有指定分组则所有结果集为一组),然后在组内根据 ORDER BY 项进行排序。根据 FIRST/LAST 计算第一名(最小值)/最后一名(最大值)的集函数值,排名按照奥林匹克排名法;
FIRST 和 LAST 集函数的用法:
<函数名> ([ALL] <值表达式>) KEEP ( DENSE_RANK <FIRST | LAST > <ORDER BY子句>) <函数名>::= AVG | MAX | MIN | COUNT | SUM <ORDER BY子句>::=语法参考4.7 ORDER BY子句 -
字符串集函数:
- LISTAGG/LISTAGG2(exp1, exp2) 首先根据 SQL 语句中的 GROUP BY 分组(如果没有指定分组则所有结果集为一组),然后在组内按照 WITHIN GROUP 中的 ORDER BY 项进行排序(没有指定排序则按数据组织顺序),最后将表达式 expr1 用表达式 expr2 串接起来。表达式 expr1 为 < 常量 >、< 列名 > 或 < 值表达式 >,支持和 DISTINCT 关键字一起使用,表示对组内的 exp1 进行去重操作后再进行串接;表达式 expr2 为指定用于分隔的分隔符,可以缺省。LISTAGG2 跟 LISTAGG 的功能是一样的,区别就是 LISTAGG 返回的是 VARCHAR 类型,LISTAGG2 返回的是 CLOB 类型。当 LISTAGG 返回串的长度超过 32767 字节时,将根据 LISTAGG_OVERFLOW 子句决定是否对返回串进行截断,若不指定 LISTAGG_OVERFLOW 子句或者指定 ON OVERFLOW ERROR,不对超长的字符串进行截断,即超长报错;当指定 ON OVERFLOW TRUNCATE 时,服务器将截断足够多的字符串,以确保返回值在不超过 32767 字节的情况下可以容纳最后一个分隔符、截断标识符和截断的字符串个数。< 截断标识符 > 的缺省值为’…’,对于[ { WITH | WITHOUT } COUNT ]选项,不指定该选项或指定 WITH COUNT 时会展示截断的字符串个数,否则不会展示截断的字符串个数。
LISTAGG 的用法:
<LISTAGG>([DISTINCT] <参数>[, <参数>] [<LISTAGG_OVERFLOW子句>]) [WITHIN GROUP(<ORDER BY项>)]
<LISTAGG_OVERFLOW子句>::=
ON OVERFLOW ERROR |
ON OVERFLOW TRUNCATE [ '截断标识符' ] [ { WITH | WITHOUT } COUNT ]
LISTAGG2 的用法:
<LISTAGG2>([DISTINCT] <参数>[, <参数>]) [WITHIN GROUP(<ORDER BY项>)]
- WM_CONCAT(expr) 首先根据 SQL 语句中的 GROUP BY 分组(如果没有指定分组则所有结果集为一组),然后将返回的组内指定参数用“,”拼接起来。expr 为 < 常量 >、< 列名 > 或 < 值表达式 >,返回类型为 CLOB。WM_CONCAT 也可以写成 WMSYS.WM_CONCAT。
WM_CONCAT 的用法:
WM_CONCAT(expr[ || expr])
- COLLECT(expr) 首先根据 SQL 语句中的 GROUP BY 分组(如果没有指定分组则所有结果集为一组),然后在组内按照 ORDER BY 项进行排序(没有指定排序则按数据组织顺序),最后将参数列拼接起来组合成对象类型大字段,再由外层 CAST 函数转换为嵌套表。表达式 expr 支持和 DISTINCT 或 UNIQUE 关键字一起使用,表示对组内的 expr 进行去重操作后再进行串接。COLLECT 返回的是 BLOB 类型,必须与 CAST 一起使用才能返回嵌套表类型,不支持在 CAST 之外使用。
COLLECT 的用法:
CAST (<COLLECT> ([DISTINCT / UNIQUE] <参数> [ORDER BY项]) AS TYPE)
其中,TYPE 只能是嵌套表类型,且参数列类型可转换到嵌套表列类型。嵌套表列类型目前仅支持 DM 定义的常规数据类型(如数值类型、字符类型、多媒体类型、日期时间类型等),暂不支持非常规数据类型(如记录类型、数组类型、集合类型、类类型等)。
- MEDIAN 集函数当组内排序后,返回组内的中位数。计算过程中忽略空值 NULL。MPP/LPQ 情况下,需要保证组内数据是全的,否则结果错误。MEDIAN()不支持和 DISTINCT 和<KEEP 子句>一起使用。<参数>:参数类型可以是数值类型(INT/DEC)、时间类型(DATETIME/DATE)、时间间隔类型(INTERVAL YEAR TO MONTH)。<参数>暂不支持带时区的时间类型。
MEDIAN 的用法:
MEDIAN(<参数>)
- 线性回归相关 REGR 集函数 参数 expr1 和 expr2 为 < 列名 > 或 < 值表达式 >,当 expr1 或 expr2 为空值 NULL 时,忽略该组数值对。REGR 集函数均不支持 distinct,仅 regr_count 支持和 <keep 子句 > 一起使用。与计算无关的参数(REGR_COUNT 的 expr1 和 expr2、REGR_AVGX 的 expr1、REGR_AVGY 的 expr2、REGR_SXX 的 expr1、 REGR_SYY 的 expr2,这五个参数都与实际计算过程无关)支持包含自定义类型在内的任意类型。除与计算无关的参数外,REGR 集函数参数应为数值类型,REGR_AVGX 的 expr2 和 REGR_AVGY 的 expr1 还可以是时间间隔类型。具体用法如下:
1)REGR_COUNT(expr1, expr2) 返回所有非空(expr1,expr2)数值对的个数。等价于 COUNT(NVL2(expr1,expr2,NULL))。
2)REGR_AVGX(expr1,expr2),去除含空值的数值对后,计算 expr2 的平均值,其计算公式为:
SUM(NVL2(*expr1, expr2*, NULL))/COUNT(NVL2(*expr1, expr2*, NULL))
3)REGR_AVGY(expr1,expr2),去除含空值的数值对后,计算 expr1 的平均值,其计算公式为:
SUM(NVL2(*expr2, expr1*, NULL))/COUNT(NVL2(*expr2, expr1*, NULL))
4)REGR_SLOPE(expr1,expr2),去除含空值的数值对后,计算回归曲线的斜率,其计算公式为:
5)REGR_INTERCEPT(expr1,expr2),去除含空值的数值对后,计算回归曲线在 y 轴(对应 expr1)上的截距,其计算公式为:
6)REGR_R2(expr1,expr2),去除含空值的数值对后,计算回归曲线的相关系数,其计算公式为:
7)REGR_SXX(expr1,expr2),计算诊断统计量 SXX,去除含空值的数值对后,相当于 COUNT(expr2) * VAR_POP(expr2),其计算公式为:
8)REGR_SYY(expr1,expr2),计算诊断统计量 SYY,去除含空值的数值对后,相当于 COUNT(expr1) * VAR_POP(expr1),其计算公式为:
9)REGR_SXY(expr1,expr2),计算诊断统计量 SXY,去除含空值的数值对后,相当于 REGR_COUNT(expr1,expr2) * COVAR_POP(expr1,expr2),其计算公式为:
- 百分比集函数 PERCENTILE_CONT、PERCENTILE_DISC
1)PERCENTILE_CONT:计算连续分布的百分位数。当组内排序后,percentile_cont 函数返回组内某百分比位置处的数据(对应列为 order by 项的 key),计算过程中忽略空值 NULL。PERCENTILE_CONT 用法如下:
<PERCENTILE_CONT> (<参数>) WITHIN GROUP(<ORDER BY项>) <GROUP BY项>
说明
- <group by 项 > 为可选项;
- 参数的数学含义为百分比;
a) 不含有group by语句时:合法的参数可以是[0, 1]区间内任意值,或能够计算成[0, 1]区间内值的常量表达式。
b) 含有group by语句时:参数不仅可以是[0, 1]区间内任意值,或能够计算成[0, 1]区间内值的常量表达式,也可以是由group by key对应列构成的表达式(最终计算值范围依旧是[0, 1]);
- <order by 项 >:order by 项的 key 有且仅有 1 个,其类型可以是数值类型(INT/DEC)、时间类型(DATETIME/DATE)、时间间隔类型(INTERVAL YEAR TO MONTH),暂不支持带时区的时间类型;
- percentile_cont()不支持和 DISTINCT 和 <KEEP 子句 > 一起使用,必须配合 within group 一起使用;
- MPP/LPQ 情况下,需要保证组内数据是全的,否则结果错误。
**2)PERCENTILE_DISC:**计算离散分布的百分位数。当组内排序后,percentile_disc 函数返回组内某百分比位置处的实际数据(对应列为 order by 项的 key),计算过程中忽略空值 NULL。PERCENTILE_DISC 用法如下:
<PERCENTILE_DISC> (<参数>) WITHIN GROUP(<ORDER BY项>) <GROUP BY项>
说明
- <group by 项 > 为可选项;
- 参数的数学含义为百分比;
a) 不含有group by语句时:合法的参数可以是[0, 1]区间内任意值,或能够计算成[0, 1]区间内值的常量表达式。
b) 含有group by语句时:参数不仅可以是[0, 1]区间内任意值,或能够计算成[0, 1]区间内值的常量表达式,也可以是由group by key对应列构成的表达式(最终计算值范围依旧是[0, 1]);
- <order by 项 >:order by 项的 key 有且仅有 1 个,数据类型无限制,任何支持排序操作的类型皆可;
- percentile_disc()不支持和 DISTINCT 和 <KEEP 子句 > 一起使用,必须配合 within group 一起使用;
- MPP/LPQ 情况下,需要保证组内数据是全的,否则结果错误。
- 位运算集函数 BIT_AND、BIT_OR、BIT_XOR 三个函数功能分别如下:BIT_AND(expr)返回所有数据按位进行与运算的结果;BIT_OR(expr)返回所有数据按位进行或运算的结果;BIT_XOR(expr) 返回所有数据按位进行异或运算的结果。仅支持在 COMPATIBLE_MODE=4 时使用这三个集函数。参数的数据类型不同时,函数使用方式也略有不同,具体介绍如下:
1)参数类型为 binary/varbinary 类型参数时,结果为 varbinary 类型,结果类型长度是参数类型长度加一;
2)binary/varbinary 类型参数使用 bit_and/bit_or/bit_xor,需要所有行数据长度都相等,否则报错;
3)其余的数据类型,如果是非 bigint 类型,会先转为 bigint 类型再传入函数;
4)NULL 数据忽略,若所有数据都为 NULL,则 bit_and 结果为所有 bit 置为 1,bit_or/bit_xor 结果为所有 bit 置为 0。
4.1.3.3 举例说明
下面按集函数的功能分别举例说明。
1.求最大值集函数 MAX 和求最小值集函数 MIN
例 查询折扣小于 7 的图书中现价最低的价格。
SELECT MIN(NOWPRICE) FROM PRODUCTION.PRODUCT WHERE DISCOUNT < 7;
查询结果为:6.1
需要说明的是:SELECT 后使用集函数 MAX 和 MIN 得到的是一个最大值和最小值,因而 SELECT 后不能再有列名出现,如果有只能出现在集函数中。如:
SELECT NAME,MIN(NOWPRICE) FROM PRODUCTION.PRODUCT;
DM 系统会报错,因为 NAME 是一个行集合,而最低价格是唯一值。
至于 MAX 的使用格式与 MIN 是完全一样的,读者可以自己举一反三。
2.求平均值集函数 AVG 和总和集函数 SUM
例 1 求折扣小于 7 的图书的平均现价。
SELECT AVG(NOWPRICE) FROM PRODUCTION.PRODUCT WHERE DISCOUNT < 7;
查询结果为:23.15
例 2 求折扣大于 8 的图书的总价格。
SELECT SUM(NOWPRICE) FROM PRODUCTION.PRODUCT WHERE DISCOUNT >8;
查询结果为:25.5
3. 求总个数集函数 COUNT
例 1 查询已登记供应商的个数。
SELECT COUNT(*) FROM PURCHASING.VENDOR;
查询结果为:12
由此例可看出,COUNT(*)的结果是 VENDOR 表中的总行数,由于主关键字不允许有相同值,因此,它不需要使用保留字 DISTINCT。
例 2 查询目前销售的图书的出版商的个数。
SELECT COUNT(DISTINCT PUBLISHER) FROM PRODUCTION.PRODUCT;
查询结果为:9
由于一个出版商可出版多种图书,因而此例中一定要用 DISTINCT 才能得到正确结果。
4. 求方差集函数 VARIANCE、标准差函数 STDDEV 和样本标准差函数 STDDEV_SAMP
例 1 求图书的现价方差。
SELECT VARIANCE(NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:136.648888888888888888888888888888888889
例 2 求图书的现价标准差。
SELECT STDDEV(NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:11.6896915651735
例 3 求图书的现价样本标准差。
SELECT STDDEV_SAMP(NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:11.6896915651735
5. 求总体协方差集函数 COVAR_POP、样本协方差函数 COVAR_SAMP 和相关系数 CORR
例 1 求产品原始价格 ORIGINALPRICE 和当头销售价格 NOWPRICE 的总体协方差。
SELECT COVAR_POP(ORIGINALPRICE, NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:166.226
例 2 求产品原始价格 ORIGINALPRICE 和当头销售价格 NOWPRICE 的样本协方差。
SELECT COVAR_SAMP(ORIGINALPRICE, NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:184.69555555555555555555555555555555556
例 3 求产品原始价格 ORIGINALPRICE 和当头销售价格 NOWPRICE 的相关系数。
SELECT CORR(ORIGINALPRICE, NOWPRICE) FROM PRODUCTION.PRODUCT;
查询结果为:9.6276530968E-01
6. 首行函数 FIRST_VALUE
例 返回查询项的首行记录。
SELECT FIRST_VALUE(NAME) FROM PRODUCTION.PRODUCT;
查询结果为:红楼梦
7. 任意行函数 ANY_VALUE
例 返回查询项的任意行记录。
SELECT ANY_VALUE(NAME) FROM PRODUCTION.PRODUCT;
查询结果为:红楼梦
8. 求区间范围内的最大值函数 AREA_MAX
例 求图书的现价在 20~30 之间的最大值。
SELECT area_max(NOWPRICE,20,30) FROM PRODUCTION.PRODUCT;
查询结果为:25.5
9. 求 FIRST/LAST 集函数
例 求每个用户最早定的商品中花费最多和最少的金额。
select CUSTOMERID, max(TOTAL) keep (dense_rank first order by ORDERDATE) max_val, min(TOTAL) keep (dense_rank first order by ORDERDATE) min_val from SALES.SALESORDER_HEADER group by CUSTOMERID;
查询结果如下:
CUSTOMERID MAX_VAL MIN_VAL
-----------------------------------
1 36.9 36.9
10. 求 LISTAGG/LISTAGG2 集函数、求 WM_CONCAT 集函数、求 COLLECT 集函数
例 1 求出版的所有图书,分隔符为', ',使用 LISTAGG/LISTAGG2。
SELECT LISTAGG(NAME, ', ') WITHIN GROUP (ORDER BY NAME) LISTAGG FROM PRODUCTION.PRODUCT;
或
SELECT LISTAGG2(NAME, ', ') WITHIN GROUP (ORDER BY NAME) LISTAGG FROM PRODUCTION.PRODUCT;
查询结果如下:
LISTAGG
--------------------------------------------------------------------
长征, 工作中无小事, 红楼梦, 老人与海, 鲁迅文集(小说、散文、杂文)全两册, 射雕英雄传(全四册), 数据结构(C语言版)(附光盘), 水浒传, 突破英文基础词汇, 噼里啪啦丛书(全7册)
例 2 求每个出版社出版的所有图书。先根据出版社进行分组,然后将每个出版社出版的图书名用“,”拼接起来,使用 WM_CONCAT。
SELECT PUBLISHER, WM_CONCAT(NAME) FROM PRODUCTION.PRODUCT GROUP BY PUBLISHER;
查询结果如下:
PUBLISHER WM_CONCAT(NAME)
------------------ ----------------------------------
中华书局 红楼梦,水浒传
上海出版社 老人与海
广州出版社 射雕英雄传(全四册)
鲁迅文集(小说、散文、杂文)全两册
人民文学出版社 长征
清华大学出版社 数据结构(C语言版)(附光盘)
机械工业出版社 工作中无小事
外语教学与研究出版社 突破英文基础词汇
21世纪出版社 噼里啪啦丛书(全7册)
例 3 求出版的所有图书书名的嵌套表。
CREATE TYPE T_NAME AS TABLE OF VARCHAR;
/
SELECT CAST(COLLECT(NAME ORDER BY NAME) AS T_NAME) AS T_NAME FROM PRODUCTION.PRODUCT;
查询结果如下:
T_NAME
---------------------------------------------------------
RPODUCTION.T_NAME(长征,工作中无小事,红楼梦,老人与海,鲁迅文集(小说、散文、杂文)全两册,射雕英雄传(全四册),数据结构(C语言版)(附光盘),水浒传,突破英文基础词汇,噼里啪啦丛书(全7册))
11. 求 MEDIAN 集函数
例 求按照 type 分组之后,各组内 nowprice 的中位数。
SELECT MEDIAN(nowprice)FROM PRODUCTION.PRODUCT group by(type);
查询结果如下:
MEDIAN(NOWPRICE)
----------------
17.6
18.45
12. 求线性回归相关 REGR 集函数
例 1 以 ORIGINALPRICE 为自变量,NOWPRICE 为因变量,对 ORIGINALPRICE 和 NOWPRICE 进行线性回归分析,求有效数据行数,自变量均值,因变量均值。
SELECT REGR_COUNT(NOWPRICE, ORIGINALPRICE) AS COUNT, REGR_AVGX(NOWPRICE, ORIGINALPRICE) AS AVGX, REGR_AVGY(NOWPRICE, ORIGINALPRICE) AS AVGY FROM PRODUCTION.PRODUCT;
查询结果如下:
行号 COUNT AVGX AVGY
---------- -------------------- ----- ----
1 10 29.35 20.5
例 2 以 ORIGINALPRICE 为自变量,NOWPRICE 为因变量,对 ORIGINALPRICE 和 NOWPRICE 进行线性回归分析,求斜率,因变量截距,相关系数。
SELECT REGR_SLOPE(NOWPRICE, ORIGINALPRICE) AS SLOPE, REGR_INTERCEPT(NOWPRICE, ORIGINALPRICE) AS INTERCEPT,REGR_R2(NOWPRICE, ORIGINALPRICE) AS R2 FROM PRODUCTION.PRODUCT;
查询结果如下:
行号 SLOPE INTERCEPT R2
-------- ------------------ -------------------- ---------------------
1 0.6857890187778609782310483463394207185631
0.3720922988697802889187310349380019102
0.9269170415287250290073037339704071128267
例 3 以 ORIGINALPRICE 为自变量,NOWPRICE 为因变量,对 ORIGINALPRICE 和 NOWPRICE 进行线性回归分析,求三种诊断统计量。
SELECT REGR_SXX(nowprice, originalprice) AS SXX, REGR_SYY(nowprice, originalprice) AS SYY,REGR_SXY(nowprice, originalprice) AS SXY FROM PRODUCTION.PRODUCT;
查询结果如下:
行号 SXX SYY SXY
---------- -------- ------- -------
1 2423.865 1229.84 1662.26
13. 百分比集函数 PERCENTILE_CONT、PERCENTILE_DISC
例 PERCENTILE_CONT、PERCENTILE_DISC 的使用
数据准备如下:
// dm.ini中USE_PLN_POOL设为0
drop table test_percentile;
create table test_percentile(c1 int, c2 int, c3 double);
INSERT INTO test_percentile SELECT trunc(DBMS_RANDOM.VALUE(1,10)),trunc(DBMS_RANDOM.VALUE(1,10)),trunc(DBMS_RANDOM.VALUE(0,10)/10.0) from dual connect by level <=1000;
commit;
查询 C1 排序之后排在 30% 的数据。
select percentile_cont(0.3) within group(order by c1) from test_percentile;
select percentile_disc(0.3) within group(order by c1) from test_percentile;
结果如下:
行号 PERCENTILE_CONT(0.3)WITHINGROUP(ORDERBYC1ASC)
---------- ---------------------------------------------
1 3
行号 PERCENTILE_DISC(0.3)WITHINGROUP(ORDERBYC1ASC)
---------- ---------------------------------------------
1 3
14.位运算集函数 BIT_AND、BIT_OR、BIT_XOR
例 bit_and、big_or、bit_xor 的使用
数据准备:
create table test(c1 int, c2 int);
insert into test values(1, 1), (1, 3), (2, 5), (2, 7);
commit;
查询结果:
select c1, bit_and(c2), bit_or(c2), bit_xor(c2) from test group by c1;
行号 C1 BIT_AND(C2) BIT_OR(C2) BIT_XOR(C2)
---------- ----------- -------------------- -------------------- --------------------
1 1 1 3 2
2 2 5 7 2
4.1.4 分析函数
分析函数主要用于计算基于组的某种聚合值。
DM 分析函数为用户分析数据提供了一种更加简单高效的处理方式。如果不使用分析函数,则必须使用连接查询、子查询或者视图,甚至复杂的存储过程实现。引入分析函数后,只需要简单的 SQL 语句,并且执行效率方面也有大幅提高。
与集函数的主要区别是,分析函数对于每组返回多行数据。多行形成的组称为窗口,窗口决定了执行当前行的计算范围,窗口的大小可以由组中定义的行数或者范围值滑动。
4.1.4.1 函数分类
分析函数可按照如下方式分类:
- COUNT(*);
- 完全分析函数 AVG|MAX|MIN|COUNT|SUM([ALL]<值表达式>),这 5 个分析函数的参数和作为集函数时的参数一致;
- 方差函数 VAR_POP、VAR_SAMP、VARIANCE、STDDEV_POP、STDDEV_SAMP、STDDEV;
- 协方差函数 COVAR_POP、COVAR_SAMP、CORR;
- FIRST_LAST 分析函数;
- 相邻函数 LAG 和 LEAD;
- 首尾函数 FIRST_VALUE、LAST_VALUE;
- 分组函数 NTILE;
- 排序函数 RANK、DENSE_RANK、ROW_NUMBER;
- 百分比函数 PERCENT_RANK、CUME_DIST、RATIO_TO_REPORT、PERCENTILE_CONT、PERCENTILE_DISC;
- 字符串函数 LISTAGG、WM_CONCAT;
- 指定行函数 NTH_VALUE;
- 中位数函数 MEDIAN;
- 线性回归曲线斜率函数 REGR_SLOPE。
4.1.4.2 使用说明
- 分析函数只能出现在选择项或者 ORDER BY 子句中;
- 分析函数中有 DISTINCT 的时候,除 MIN、MAX 外,不允许与 ORDER BY 一起使用;
- 分析函数参数、PARTITION BY 项和 ORDER BY 项中不允许使用分析函数,即不允许嵌套;
- <PARTITION BY 项 > 为分区子句,表示对结果集中的数据按指定列进行分区。不同的区互不相干。当 PARTITION BY 项包含常量表达式时,表示以整个结果集分区;当省略 PARTITION BY 项时,将所有行视为一个分组;
- <ORDER BY 项 > 为排序子句,对经 <PARTITION BY 项 > 分区后的各分区中的数据进行排序。ORDER BY 项中包含常量表达式时,表示以该常量排序,即保持原来结果集顺序;
- < 窗口子句 > 为分析函数指定的窗口。窗口就是分析函数在每个分区中的计算范围;< 窗口子句 > 必须和 <ORDER BY 子句 > 同时使用;
- AVG、COUNT、MAX、MIN、SUM 这 5 类分析函数的参数和返回的结果集的数据类型与对应的集函数保持一致,详细参见 4.1.3 小节 集函数部分;
- 只有 MIN、MAX、COUNT、SUM、AVG、STDDEV、VARIANCE 的参数支持 DISTINCT,其他分析函数的参数不允许为 DISTINCT;
- FIRST_VALUE 分析函数返回组中数据窗口的第一个值,LAST_VALUE 表示返回组中数据窗口 ORDER BY 项相同的最后一个值;
- FIRST_VALUE/LAST_VALUE/LAG/LEAD/NTH_VALUE 函数支持 RESPECT|IGNORE NULLS 子句,该子句用来指定计算中是否跳过 NULL 值;
- NTH_VALUE 函数支持 FROM FIRST/LAST 子句,该子句用来指定计算中是从第一行向后还是最后一行向前。
4.1.4.3 具体用法
分析函数的使用,按以下几种情况。
4.1.4.3.1 一般分析函数
分析函数的分析子句语法如下:
<分析函数>::=<函数名>([<参数>{,<参数>}]) OVER (<分析子句>)
<分析子句>::= [<PARTITION BY项>] [<ORDER BY项> [<窗口子句>]]
<PARTITION BY项>::= PARTITION BY <<常量表达式>| <列名>>
<ORDER BY项>::= ORDER BY <<常量表达式>| <列名>>
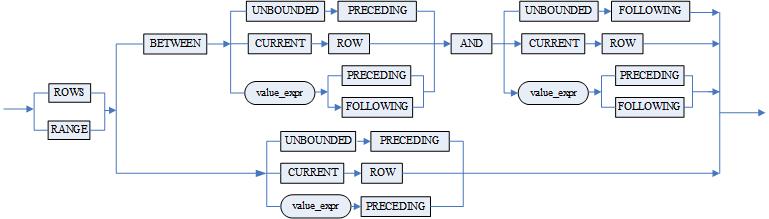
<窗口子句>::=<ROWS | RANGE> < <范围子句1>|<范围子句2> >
<范围子句1>::=
BETWEEN {<UNBOUNDED PRECEDING>|<CURRENT ROW>|<value_expr <PRECEDING|FOLLOWING> >}
AND {<UNBOUNDED FOLLOWING>|<CURRENT ROW>|<value_expr <PRECEDING|FOLLOWING> >}
<范围子句2>::=<UNBOUNDED PRECEDING>|<CURRENT ROW>| <value_expr PRECEDING>
<函数名>::=见下表
窗口子句: 不是所有的分析函数都可以使用窗口。其对应关系如下表所示:
| 序号 | 函数名 | 是否为集函数 | 是否允许使用窗口子句 |
|---|---|---|---|
| 1 | AVG | Y | Y |
| 2 | CORR | Y | Y |
| 3 | COUNT | Y | Y |
| 4 | COVAR_POP | Y | Y |
| 5 | COVAR_SAMP | Y | Y |
| 6 | CUME_DIST | Y | N |
| 7 | DENSE_RANK | N | N |
| 8 | FIRST | Y | Y |
| 9 | FIRST_VALUE | Y | Y |
| 10 | LAG | N | N |
| 11 | LAST | Y | Y |
| 12 | LAST_VALUE | N | Y |
| 13 | LEAD | N | N |
| 14 | LISTAGG | Y | N |
| 15 | NTH_VALUE | N | Y |
| 16 | MAX | Y | Y |
| 17 | MIN | Y | Y |
| 18 | NTILE | N | N |
| 19 | PERCENT_RANK | N | N |
| 20 | PERCENTILE_CONT | Y | N |
| 21 | PERCENTILE_DISC | Y | N |
| 22 | RANK | N | N |
| 23 | RATIO_TO_REPORT | N | N |
| 24 | ROW_NUMBER | N | N |
| 25 | STDDEV | Y | Y |
| 26 | STDDEV_POP | Y | Y |
| 27 | STDDEV_SAMP | Y | Y |
| 28 | SUM | Y | Y |
| 29 | VAR_POP | Y | Y |
| 30 | VAR_SAMP | Y | Y |
| 31 | VARIANCE | Y | Y |
| 32 | WM_CONCAT | Y | N |
| 33 | MEDIAN | Y | N |
| 34 | REGR_SLOPE | Y | Y |
< 窗口子句 > 通过指定滑动方式和 < 范围子句 > 两项来共同确定分析函数的计算窗口。每个分区的第一行开始往下滑动。
■ 滑动方式有两种:ROW 和 RANGE。
● ROWS
ROWS 用来指定窗口的物理行数。ROWS 根据 ORDER BY 子句排序后,取的前 value_expr 行或后 value_expr 行的数据进行计算。与当前行的值无关,只与排序后的行号有关。
对于 ROWS 来说,value_expr 必须是一个可以计算的非负数值类型的表达式或常量。
● RANGE
RANGE 用来指定窗口的逻辑偏移,即指定行值的取值范围。只要行值处于 RANGE 指定的取值范围内,该行就包含在窗口中。
- 逻辑偏移值(value_expr)必须为非负的常量、表达式或者 NUMERIC 类型数值;
- <ORDER BY 子句 > 中如果使用表达式,那么只能声明一个表达式;
- value_expr 类型和 ORDER BY expr 类型应为相同的或可隐式转换计算的。
■ < 范围子句 > 用来指定具体的窗口范围。ROW 和 RANGE 中用法不同,下面分别介绍。
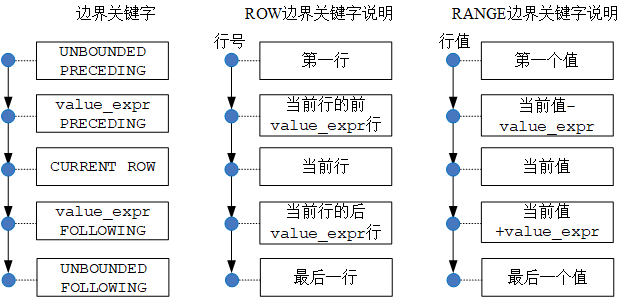
● < 范围子句 > 中的边界关键字介绍如下:
- UNBOUNDED PRECEDING 窗口的边界是分区中的第一行或第一个值;
- UNBOUNDED FOLLOWING 窗口的边界是分区中的最后一行或最后一个值;
- CURRENT ROW 窗口的边界是当前行或者当前行的值;
- value_expr PRECEDING 窗口的边界是当前行向前滑动 value_expr 的行或当前值-value_expr 的值;
- value_expr FOLLOWING 窗口的边界是当前行向后滑动 value_expr 的行或当前值 +value_expr 的值。
● < 范围子句 > 中的边界关键字在 RANGE 的用法介绍
- UNBOUNDED PRECEDING 窗口的边界是分区中的第一个值;
- UNBOUNDED FOLLOWING 窗口的边界是分区中的最后一个值;
- CURRENT ROW 窗口的边界是当前值;
- value_expr PRECEDING 窗口的边界是当前值-value_expr 的值;
- value_expr FOLLOWING 窗口的边界是当前值 +value_expr 的值。
● < 范围子句 > 中的边界关键字的使用须知:
- BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示该组的第一行到当前行,或表示第一个值到当前值;
- BETWEEN CURRENT ROW AND CURRENT ROW,表示当前行到当前行,或表示当前值到当前值;
- BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,表示该组的第一行到最后一行,或表示第一个值到最后一个值;
- UNBOUNDED PRECEDING,和 1)等价;
- CURRENT ROW,和 2)等价;
- value_expr PRECEDING,等价于 BETWEEN value_expr PRECEDING AND CURRENT ROW;
- 如果省略 < 窗口子句 >,缺省为 BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW;
- BETWEEN ... AND...:窗口的范围,如果只定义一个分支,其另一个分支为当前行 CURRENT ROW;
- CURRENT ROW 用法中有两种特殊情况:一是当窗口以 CURRENT ROW 为开始位置时,窗口的结束点不能是 value_expr PRECEDING。二是当窗口以 CURRENT ROW 为结束位置时,窗口的起始点不能是 value_expr FOLLOWING。
- value_expr PRECEDING 或 value_expr FOLLOWING 用法中有三种特殊情况:一是对于 ROWS 或 RANGE,如果 value_expr FOLLOWING 是起始位置,则结束位置也必须是 value_expr FOLLOWING;如果 value_expr PRECEDING 是结束位置,则起始位置必须是 value_expr PRECEDING。二是对于 ROWS,如果窗口函数的起始位置到结束位置没有记录,则分析函数的值返回 NULL。三是对于 RANGE,在 <ORDER BY 子句 > 中,只能指定一个表达式,即排序列不能多于一个,对于 ROWS,则无此限制。
图例
分析函数语法如下:

分析子句

partition by 项

order by 项

窗口子句
4.1.4.3.2 FIRST/LAST 函数
FIRST 和 LAST 作为分析函数时,计算方法和对应的集函数类似,只是一组返回多行。
语法格式
<函数名><参数> <KEEP子句> OVER ([<PARTITION BY项>])
<KEEP子句>::= KEEP (DENSE_RANK <FIRST|LAST> <ORDER BY项>)
<函数名> ::= AVG | MAX | MIN | COUNT | SUM
<KEEP 子句> 首先根据<ORDER BY 项>进行排序,然后根据 FIRST/LAST 计算出第一名(最小值)/最后一名(最大值)的函数值,排名按照奥林匹克排名法。
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
FIRST 和 LAST 分析函数语法如下:

4.1.4.3.3 LAG 和 LEAD 函数
LAG 分析函数表示返回组中和当前行向前相对偏移 offset 行的参数的值,LEAD 方向相反,表示向后相对偏移。如果超出组的总行数范围,则返回 DEFAULT 值。
语法格式
<LAG|LEAD> <参数选项1|参数选项2> OVER ([<PARTITION BY项>] <ORDER BY项>)
<参数选项1> ::= (<参数>[,<offset>[,<default>]])[<RESPECT|IGNORE> NULLS]
<参数选项2> ::= (<参数>[<RESPECT|IGNORE> NULLS] [,<offset>[,<default>]])
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
参数
<offset> 为常量或表达式,类型为整型,默认为 1;
<default> 不在 offset 偏移范围内的默认值,为常量或表达式,和 LAG 和 LEAD 的参数数据类型一致;
<RESPECT|IGNORE> NULLS 计算中是否跳过 NULL 值,RESPECT NULLS 为不跳过,IGNORE NULLS 为跳过,默认值为 RESPECT NULLS。
图例
LAG 和 LEAD 函数

arguments1

arguments2

4.1.4.3.4 FIRST_VALUE 和 LAST_VALUE 函数
FIRST_VALUE 返回排序数据集合的第一行,LAST_VALUE 返回其最后一行。
语法格式
<FIRST_VALUE|LAST_VALUE> <参数选项1|参数选项2> OVER <(<分析子句>) | <窗口名>>
<参数选项1> ::= (<参数>) [<RESPECT | IGNORE> NULLS ]
<参数选项2> ::= (<参数> [<RESPECT | IGNORE> NULLS ])
< 分析子句 > 请参考 4.1.4.3.1 一般分析函数
图例
FIRST_VALUE 和 LAST_VALUE 函数

arguments1

arguments2

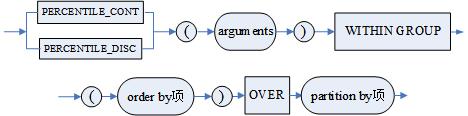
4.1.4.3.5 PERCENTILE_CONT 和 PERCENTILE_DISC 函数
连续百分比 PERCENTILE_CONT 和分布百分比 PERCENTILE_DISC 分析函数。
语法格式
<PERCENTILE_CONT|PERCENTILE_DISC> (<参数>) WITHIN GROUP(<ORDER BY项>) OVER ([<PARTITION BY项>])
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
PERCENTILE_CONT 和 PERCENTILE_DISC 函数
4.1.4.3.6 LISTAGG 函数
字符串分析函数 LISTAGG 按照指定的 PARTITION BY 项进行分组,组内按照 ORDER BY 项排序(没有指定排序则按数据组织顺序),将组内的参数通过分隔符拼接起来,返回的结果集行数为组数。
语法格式
LISTAGG (<参数> [,<分隔符>]) [WITHIN GROUP(<ORDER BY项>)] OVER ([<PARTITION BY项>])
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
LISTAGG 函数

4.1.4.3.7 NTH_VALUE 函数
指定行分析函数 NTH_VALUE 按照指定的 PARTITION BY 项进行分组,组内按照 ORDER BY 项排序,返回组内结果集的指定行的数据。
语法格式
NTH_VALUE (<参数1> ,<参数2>) [FROM <FIRST | LAST>] [<RESPECT | IGNORE> NULLS] OVER ([<PARTITION BY项>] [<ORDER BY项> [<窗口子句>]])
<PARTITION BY 项 >、<ORDER BY 项 >、< 窗口子句 > 请参考 4.1.4.3.1 一般分析函数
参数
- FROM <FIRST | LAST> 指定组内数据方向,FROM FISRT 指定从第一行往后,FROM LAST 指定从最后一行往前,默认值为 FROM FIRST;
- <RESPECT|IGNORE> NULLS 计算中是否跳过 NULL 值,RESPECT NULLS 为不跳过,IGNORE NULLS 为跳过,默认值为 RESPECT NULLS。
图例
NTH_VALUE 函数

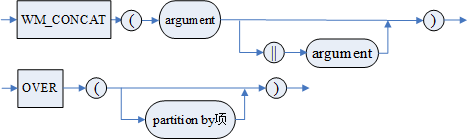
4.1.4.3.8 WM_CONCAT 函数
字符串分析函数 WM_CONCAT 按照指定的 PARTITION BY 项进行分组,组内按照 ORDER BY 项排序,然后将组内排序后的指定参数用“,”拼接起来,返回的结果集行数为组数。不支持 WITH IN 子句。
语法格式
WM_CONCAT (<参数> [|| <参数>]) OVER ([<PARTITION BY项>][<ORDER BY项>])
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
WM_CONCAT 函数
4.1.4.3.9 MEDIAN 函数
中位数计算函数 MEDIAN 按照指定的 PARTITION BY 项进行分组,不支持 WITH IN 子句,计算组内参数的中位数,返回的结果集行数为组数。
语法格式
MEDIAN (<参数>) OVER ([<PARTITION BY项>])
<PARTITION BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
MEDIAN 函数

4.1.4.3.10 NTILE 函数
NTILE 函数为分组函数。
语法格式
<分析函数>::=<函数名>(<参数>) OVER <(<分析子句>) | <窗口名>>
<分析子句>::= [<PARTITION BY项> | <窗口名>]<ORDER BY项>
<PARTITION BY 项 >、<ORDER BY 项 > 请参考 4.1.4.3.1 一般分析函数
图例
NTILE 函数
分析子句(analysis_clause)
4.1.4.4 举例说明
下面按分析函数的功能分别举例说明。
- 最大值 MAX 和最小值 MIN
例 查询折扣大于 7 的图书作者以及最大折扣。
SELECT AUTHOR, MAX(DISCOUNT) OVER (PARTITION BY AUTHOR) AS MAX FROM PRODUCTION.PRODUCT WHERE DISCOUNT > 7;
查询结果如下:
AUTHOR MAX
-------------- ---
曹雪芹,高鹗 8.0
施耐庵,罗贯中 7.5
严蔚敏,吴伟民 7.8
需要说明的是:如果使用的是集函数 MAX,那么得到的是所有图书中折扣的最大值,并不能查询出作者,使用了分析函数,就可以对作者进行分区,得到每个作者所写的图书中折扣最大的值。MIN 的含义和 MAX 类似。
- 平均值 AVG 和总和 SUM
例 1 求折扣小于 7 的图书作者和平均价格。
SELECT AUTHOR, AVG(NOWPRICE) OVER (PARTITION BY AUTHOR) as AVG FROM PRODUCTION.PRODUCT WHERE DISCOUNT < 7;
查询结果如下:
AUTHOR AVG
-------------- ----
(日)佐佐木洋子 42
陈满麒 11.4
海明威 6.1
金庸 21.7
鲁迅 20
王树增 37.7
例 2 求折扣大于 8 的图书作者和书的总价格。
SELECT AUTHOR, SUM(NOWPRICE) OVER (PARTITION BY AUTHOR) as SUM FROM PRODUCTION.PRODUCT WHERE DISCOUNT >8;
查询结果如下:
AUTHOR SUM
------------- ----
严蔚敏,吴伟民 25.5
- 样本个数 COUNT
例 查询信用级别为“很好”的已登记供应商的名称和个数。
SELECT NAME, COUNT(*) OVER (PARTITION BY CREDIT) AS CNT FROM PURCHASING.VENDOR WHERE CREDIT = 2;
查询结果如下:
NAME CNT
------------ -----------
长江文艺出版社 2
上海画报出版社 2
由此例可看出,COUNT(*)的结果是 VENDOR 表中的按 CREDIT 分组后的总行数。
4.分析函数总体协方差 COVAR_POP
例 求产品原始价格 ORIGINALPRICE 和当前销售价格 NOWPRICE 的总体协方差。
SELECT PUBLISHER, COVAR_POP(ORIGINALPRICE, NOWPRICE) OVER(PARTITION BY PUBLISHER) AS COVAR_POP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER COVAR_POP
-------------------- ---------
0
21世纪出版社 0
广州出版社 0
机械工业出版社 0
清华大学出版社 0
人民文学出版社 0
上海出版社 0
外语教学与研究出版社 0
中华书局 0
中华书局 0
- 分析函数样本协方差 COVAR_SAMP
例 求产品原始价格 ORIGINALPRICE 和当前销售价格 NOWPRICE 的样本协方差。
SELECT PUBLISHER, COVAR_SAMP(ORIGINALPRICE, NOWPRICE) OVER(PARTITION BY PUBLISHER) AS COVAR_SAMP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER COVAR_SAMP
-------------------- ----------
NULL
21世纪出版社 NULL
广州出版社 NULL
机械工业出版社 NULL
清华大学出版社 NULL
人民文学出版社 NULL
上海出版社 NULL
外语教学与研究出版社 NULL
中华书局 0
中华书局 0
6.系数 CORR
例 求产品原始价格 ORIGINALPRICE 和当前销售价格 NOWPRICE 的相关系数。
SELECT PUBLISHER, CORR(ORIGINALPRICE, NOWPRICE) OVER(PARTITION BY PUBLISHER) AS CORR FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER CORR
-------------------- -------------------------
NULL
21世纪出版社 NULL
广州出版社 NULL
机械工业出版社 NULL
清华大学出版社 NULL
人民文学出版社 NULL
上海出版社 NULL
外语教学与研究出版社 NULL
中华书局 NULL
中华书局 NULL
- 排名 RANK、DENSE_RANK 和 ROW_NUMBER
例 求按销售额排名的销售代表对应的雇员号和排名。
SELECT EMPLOYEEID, RANK() OVER (ORDER BY SALESLASTYEAR) AS RANK FROM SALES.SALESPERSON;
查询结果如下:
EMPLOYEEID RANK
----------- --------------------
4 1
5 2
RANK()排名函数按照指定 ORDER BY 项进行排名,如果值相同,则排名相同,例如销售额相同的排名相同,该函数使用非密集排名,例如两个第 1 名后,下一个就是第 3 名;与之对应的是 DENSE_RANK(),表示密集排名,例如两个第 1 名之后,下一个就是第 2 名。ROW_NUMBER()表示按照顺序编号,不区分相同值,即从 1 开始编号。
- FIRST 和 LAST
例 求每个用户最早定的商品中花费最多和最少的金额以及用户当前的花费金额。
SELECT CUSTOMERID, TOTAL,
MAX(TOTAL) KEEP (DENSE_RANK FIRST ORDER BY ORDERDATE) OVER (PARTITION BY CUSTOMERID) MAX_VAL,
MIN(TOTAL) KEEP (DENSE_RANK FIRST ORDER BY ORDERDATE) OVER (PARTITION BY CUSTOMERID) MIN_VAL
FROM SALES.SALESORDER_HEADER;
查询结果如下:
CUSTOMERID TOTAL MAX_VAL MIN_VAL
----------- ------- ------- -------
1 36.9 36.9 36.9
1 36.9 36.9 36.9
FIRST 和 LAST 分析函数计算方法和对应的集函数类似,作为分析函数时一组返回多行,而集函数只返回一行。
- FIRST_VALUE 和 LAST_VALUE 分析函数
例 求花费最多和最少金额的用户和花费金额。
SELECT NAME, TOTAL,
FIRST_VALUE(NAME) OVER (ORDER BY TOTAL) FIRST_PERSON,
LAST_VALUE(NAME) OVER (ORDER BY TOTAL) LAST_PERSON
FROM SALES.SALESORDER_HEADER S,SALES.CUSTOMER C,PERSON.PERSON P
WHERE S.CUSTOMERID = C.CUSTOMERID AND C.PERSONID = P.PERSONID;
查询结果如下:
NAME TOTAL FIRST_PERSON LAST_PERSON
---- ------- ------------ -----------
刘青 36.9 刘青 刘青
刘青 36.9 刘青 刘青
FIRST_VALUE 返回一组中的第一行数据,LAST_VALUE 相反,返回组中的最后一行数据。根据 ORDER BY 项就可以返回需要的列的值。
- LAG 和 LEAD
例 求当前订单的前一个和下一个订单的销售总额。
SELECT ORDERDATE,
LAG(TOTAL, 1, 0) OVER (ORDER BY ORDERDATE) PRV_TOTAL,
LEAD(TOTAL, 1, 0) OVER (ORDER BY ORDERDATE) NEXT_TOTAL
FROM SALES.SALESORDER_HEADER;
查询结果如下:
ORDERDATE PRV_TOTAL NEXT_TOTAL
---------- --------- ----------
2007-05-06 0 36.9
2007-05-07 36.9 0
LAG 返回当前组的前一个订单日期的 TOTAL 值,如果超出该组,则返回 DEFAULT 值 0。
- 窗口的使用
例 按照作者分类,求到目前为止图书价格最贵的作者和价格。
SELECT AUTHOR,
MAX(NOWPRICE) OVER(PARTITION BY AUTHOR ORDER BY NOWPRICE ROWS
UNBOUNDED PRECEDING) AS MAX_PRICE
FROM PRODUCTION.PRODUCT;
查询结果如下:
AUTHOR MAX_PRICE
-------------- ---------
(日)佐佐木洋子 42
曹雪芹,高鹗 15.2
陈满麒 11.4
海明威 6.1
金庸 21.7
刘毅 11.1
鲁迅 20
施耐庵,罗贯中 14.3
王树增 37.7
严蔚敏,吴伟民 25.5
分析函数中的窗口限定了计算的范围,ROWS UNBOUNDED PRECEDING 表示该组的第一行开始到当前行,等价于 ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW。
- 标准差 STDDEV
例 求每个出版社图书现价的标准差。
SELECT PUBLISHER, STDDEV(NOWPRICE) OVER(PARTITION BY PUBLISHER) AS STDDEV FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER STDDEV
-------------------- -----------------
0
21世纪出版社 0
广州出版社 0
机械工业出版社 0
清华大学出版社 0
人民文学出版社 0
上海出版社 0
外语教学与研究出版社 0
中华书局 0.636396103067893
中华书局 0.636396103067893
- 样本标准差 STDDEV_SAMP
例 求每个出版社图书现价的样本标准差。
SELECT PUBLISHER, STDDEV_SAMP(NOWPRICE) OVER(PARTITION BY PUBLISHER) AS STDDEV_SAMP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER STDDEV_SAMP
-------------------- -----------------
NULL
21世纪出版社 NULL
广州出版社 NULL
机械工业出版社 NULL
清华大学出版社 NULL
人民文学出版社 NULL
上海出版社 NULL
外语教学与研究出版社 NULL
中华书局 0.636396103067893
中华书局 0.636396103067893
- 总体标准差 STDDEV_POP
例 求每个出版社图书现价的总体标准差。
SELECT PUBLISHER, STDDEV_POP (NOWPRICE) OVER(PARTITION BY PUBLISHER) AS STDDEV_POP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER STDDEV_POP
-------------------- ----------
0
21世纪出版社 0
广州出版社 0
机械工业出版社 0
清华大学出版社 0
人民文学出版社 0
上海出版社 0
外语教学与研究出版社 0
中华书局 0.45
中华书局 0.45
- 样本方差 VAR_SAMP
例 求每个出版社图书现价的样本方差。
SELECT PUBLISHER, VAR_SAMP(NOWPRICE) OVER(PARTITION BY PUBLISHER) AS VAR_SAMP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER VAR_SAMP
-------------------- --------
NULL
21世纪出版社 NULL
广州出版社 NULL
机械工业出版社 NULL
清华大学出版社 NULL
人民文学出版社 NULL
上海出版社 NULL
外语教学与研究出版社 NULL
中华书局 0.405
中华书局 0.405
- 总体方差 VAR_POP
例 求每个出版社图书现价的总体方差。
SELECT PUBLISHER , VAR_POP(NOWPRICE) OVER(PARTITION BY PUBLISHER) AS VAR_POP FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER VAR_POP
-------------------- -------
0
21世纪出版社 0
广州出版社 0
机械工业出版社 0
清华大学出版社 0
人民文学出版社 0
上海出版社 0
外语教学与研究出版社 0
中华书局 0.2025
中华书局 0.2025
- 方差 VARIANCE
例 求每个出版社图书现价的方差。
SELECT PUBLISHER, VARIANCE (NOWPRICE) OVER(PARTITION BY PUBLISHER) AS VARIANCE FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER VARIANCE
-------------------- --------
0
21世纪出版社 0
广州出版社 0
机械工业出版社 0
清华大学出版社 0
人民文学出版社 0
上海出版社 0
外语教学与研究出版社 0
中华书局 0.405
中华书局 0.405
- 分组 NTILE
例 根据图书的现价将图书分成三个组。
SELECT NAME, NTILE (3) OVER(ORDER BY NOWPRICE) AS NTILE FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME NTILE
-------------------------------- --------------------
老人与海 1
突破英文基础词汇 1
工作中无小事 1
水浒传 1
红楼梦 2
鲁迅文集(小说、散文、杂文)全两册 2
射雕英雄传(全四册) 2
数据结构(C语言版)(附光盘) 3
长征 3
噼里啪啦丛书(全7册) 3
- 排列百分比 PERCENT_RANK
例 求图书的现价排列百分比。
SELECT NAME, PERCENT_RANK() OVER(ORDER BY NOWPRICE) AS PERCENT_RANK FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME PERCENT_RANK
-------------------------------- -------------------------
老人与海 0.000000000000000E+00
突破英文基础词汇 1.111111111111111E-01
工作中无小事 2.222222222222222E-01
水浒传 3.333333333333333E-01
红楼梦 4.444444444444444E-01
鲁迅文集(小说、散文、杂文)全两册 5.555555555555556E-01
射雕英雄传(全四册) 6.666666666666666E-01
数据结构(C语言版)(附光盘) 7.777777777777778E-01
长征 8.888888888888888E-01
噼里啪啦丛书(全7册) 1.000000000000000E+00
- 连续百分比对应的值 PERCENTILE_CONT
例 求连续百分比占 0.5 对应的图书现价值。
SELECT NAME, PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY NOWPRICE) OVER() AS PERCENTILE_CONT FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME PERCENTILE_CONT
-------------------------------- ---------------
老人与海 17.6
突破英文基础词汇 17.6
工作中无小事 17.6
水浒传 17.6
红楼梦 17.6
鲁迅文集(小说、散文、杂文)全两册 17.6
射雕英雄传(全四册) 17.6
数据结构(C语言版)(附光盘) 17.6
长征 17.6
噼里啪啦丛书(全7册) 17.6
- 分布百分比对应的值 PERCENTILE_DISC
例 求分布百分比占 0.5 对应的图书现价值。
SELECT NAME, PERCENTILE_DISC(0.5) WITHIN GROUP(ORDER BY NOWPRICE) OVER() AS PERCENTILE_DISC FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME PERCENTILE_DISC
-------------------------------- ---------------
老人与海 15.2
突破英文基础词汇 15.2
工作中无小事 15.2
水浒传 15.2
红楼梦 15.2
鲁迅文集(小说、散文、杂文)全两册 15.2
射雕英雄传(全四册) 15.2
数据结构(C语言版)(附光盘) 15.2
长征 15.2
噼里啪啦丛书(全7册) 15.2
- 累计百分比 CUME_DIST
例 求图书现价的累计百分比。
SELECT NAME, CUME_DIST() OVER(ORDER BY NOWPRICE) AS CUME_DIST FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME CUME_DIST
-------------------------------- -------------------------
老人与海 1.000000000000000E-01
突破英文基础词汇 2.000000000000000E-01
工作中无小事 3.000000000000000E-01
水浒传 4.000000000000000E-01
红楼梦 5.000000000000000E-01
鲁迅文集(小说、散文、杂文)全两册 6.000000000000000E-01
射雕英雄传(全四册) 7.000000000000000E-01
数据结构(C语言版)(附光盘) 8.000000000000000E-01
长征 9.000000000000000E-01
噼里啪啦丛书(全7册) 1.000000000000000E+00
- 某一样本值所占百分比 RATIO_TO_REPORT
例 求出版社每种图书现价所占的百分比。
SELECT NAME, RATIO_TO_REPORT(NOWPRICE) OVER(PARTITION BY PUBLISHER) AS RATIO_TO_REPORT FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME RATIO_TO_REPORT
-------------------------------- ---------------------------------------
鲁迅文集(小说、散文、杂文)全两册 1
噼里啪啦丛书(全7册) 1
射雕英雄传(全四册) 1
工作中无小事 1
数据结构(C语言版)(附光盘) 1
长征 1
老人与海 1
突破英文基础词汇 1
水浒传 0.4847457627118644067796610169491525423729
红楼梦 0.5152542372881355932203389830508474576271
- 组内指定行 NTH_VALUE
例 1 求每个出版社第二贵的书的价格。
SELECT PUBLISHER, NTH_VALUE(NOWPRICE, 2) FROM FIRST RESPECT NULLS OVER(PARTITION BY PUBLISHER ORDER BY NOWPRICE DESC) AS NTH_VALUE FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER NTH_VALUE
-------------------- ---------
NULL
21世纪出版社 NULL
广州出版社 NULL
机械工业出版社 NULL
清华大学出版社 NULL
人民文学出版社 NULL
上海出版社 NULL
外语教学与研究出版社 NULL
中华书局 NULL
中华书局 14.3
例 2 利用窗口子句求每个出版社第二贵的书的价格。
SELECT PUBLISHER, NTH_VALUE(NOWPRICE, 2) FROM FIRST RESPECT NULLS OVER(PARTITION BY PUBLISHER ORDER BY NOWPRICE DESC ROWS UNBOUNDED PRECEDING) AS NTH_VALUE FROM PRODUCTION.PRODUCT;
查询结果同例 1。
- 字符串分析函数 WM_CONCAT
例 求每个出版社出版的图书。先根据出版社进行分组,然后将每个出版社出版的图书按照销售价格进行排序,并将排好序的图书名称用“,”拼接起来。
SELECT PUBLISHER, WM_CONCAT(NAME) OVER (PARTITION BY PUBLISHER ORDER BY NOWPRICE ASC) AS WM_CONCAT FROM PRODUCTION.PRODUCT;
查询结果如下:
PUBLISHER WM_CONCAT
-------------------- --------------------------------
鲁迅文集(小说、散文、杂文)全两册
21世纪出版社 噼里啪啦丛书(全7册)
广州出版社 射雕英雄传(全四册)
机械工业出版社 工作中无小事
清华大学出版社 数据结构(C语言版)(附光盘)
人民文学出版社 长征
上海出版社 老人与海
外语教学与研究出版社 突破英文基础词汇
中华书局 水浒传
中华书局 水浒传,红楼梦
- 计算中位数 MEDIAN
例 求图书作者和其所著图书价格的中位数。先根据 PARTITION BY 项进行分组,然后计算组内参数的中位数。
SELECT AUTHOR, MEDIAN(NOWPRICE) OVER (PARTITION BY AUTHOR) as MED FROM PRODUCTION.PRODUCT;
查询结果如下:
AUTHOR MED
-------------- ----
(日)佐佐木洋子 42
曹雪芹,高鹗 15.2
陈满麒 11.4
海明威 6.1
金庸 21.7
刘毅 11.1
鲁迅 20
施耐庵,罗贯中 14.3
王树增 37.7
严蔚敏,吴伟民 25.5
27. 线性回归曲线斜率 REGR_SLOPE
例 以原始价格 ORIGINALPRICE 为自变量,现价 NOWPRICE 为因变量,对 ORIGINALPRICE 和 NOWPRICE 进行线性回归分析,求斜率。
SELECT TYPE, REGR_SLOPE(NOWPRICE, ORIGINALPRICE) OVER(PARTITION BY TYPE) AS REGR_SLOPE FROM PRODUCTION.PRODUCT;
查询结果如下:
TYPE REGR_SLOPE
---- ---------------------------------------
16 0.632129277566539923954372623574144486692
16 0.632129277566539923954372623574144486692
16 0.632129277566539923954372623574144486692
16 0.632129277566539923954372623574144486692
16 0.632129277566539923954372623574144486692
16 0.632129277566539923954372623574144486692
8 0.737522446307136791199102795983326526511
8 0.737522446307136791199102795983326526511
8 0.737522446307136791199102795983326526511
8 0.737522446307136791199102795983326526511
28.LISTAGG 函数
例 查询公司雇员中所有的销售代表,查询到的结果用“,”进行分隔。
SELECT TITLE, LISTAGG(NAME, ',')
WITHIN GROUP (ORDER BY TITLE) NAME
FROM RESOURCES.EMPLOYEE E
INNER JOIN PERSON.PERSON P on E.PERSONID = P.PERSONID
WHERE TITLE = '销售代表'
GROUP BY TITLE;
查询结果如下:
TITLE NAME
------- -------
销售代表 郭艳,孙丽
4.1.5 情况表达式
<值表达式>可以为一个<列引用>、<集函数>、<标量子查询>或<情况表达式>等等。
<情况表达式>包括<情况缩写词>和<情况说明>两大类。<情况缩写词>包括函数 NULLIF 和 COALESCE,在 DM 中被划分为空值判断函数。具体函数说明请见 8.4 节。下面详细介绍<情况说明>表达式。
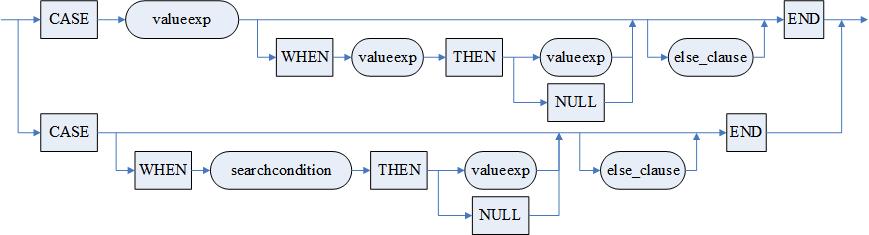
<CASE 情况说明>的语法和语义如下:
语法格式
<情况说明> ::= <简单情况> | <搜索情况>
<简单情况> ::= CASE
<值表达式>
{<简单WHEN 子句>}
[<ELSE 子句>]
END
<搜索情况> ::= CASE
[<搜索WHEN子句>]
[<ELSE 子句>]
END
<简单WHEN 子句> ::= WHEN <值表达式> THEN <结果>
<搜索WHEN子句> ::= WHEN <搜索条件> THEN <结果>
<结果> ::= <值表达式> | NULL
图例
情况表达式
功能
指明一个条件值。将搜索条件作为输入并返回一个标量值。
使用说明
1.在 < 情况说明 > 中至少有一个 < 结果 > 应该指明 < 值表达式 >;
2.如果未指明<ELSE 子句>,则隐含 ELSE NULL;
3.< 简单情况>中,CASE 运算数的数据类型必须与<简单 WHEN 子句>中的<值表达式>的数据类型是可比较的,且与 ELSE 子句的结果也是可比较的;
4.< 情况说明 > 的数据类型由 < 结果 > 中的所有 < 值表达式 > 的数据类型确定;
1)如果 < 结果 > 指明 NULL,则它的值是空值;
2)如果 < 结果 > 指明 < 值表达式 >,则它的值是该 < 值表达式 > 的值。
5.如果在<情况说明>中某个<搜索 WHEN 子句>的<搜索条件>为真,则<情况说明>的值是其<搜索条件>为真的第一个<搜索 WHEN 子句>的<结果>的值,并按照<情况说明>的数据类型来转换;
6.< 搜索 WHEN 子句 > 中支持多列,如:
SELECT CASE WHEN (C1,C2) IN (SELECT C1,C2 FROM T2) THEN 1 ELSE 0 END FROM T1;
7.如果在< 情况说明> 中没有一个< 搜索条件> 为真,则< 情况表达式> 的值是其显式或隐式的<ELSE 子句> 的< 结果> 的值,并按照< 情况说明> 的数据类型来转换。
举例说明
例 1 查询图书信息,如果当前销售价格大于 20 元,返回“昂贵”,如果当前销售价格小于等于 20 元,大于等于 10 元,返回“普通”,如果当前销售价格小于 10 元,返回“便宜”。
SELECT NAME,
CASE
WHEN NOWPRICE > 20 THEN '昂贵'
WHEN NOWPRICE <= 20 AND NOWPRICE >= 10 THEN '普通'
ELSE '便宜'
END AS 选择
FROM PRODUCTION.PRODUCT;
查询结果如下:
NAME 选择
-------------------------------- ----
红楼梦 普通
水浒传 普通
老人与海 便宜
射雕英雄传(全四册) 昂贵
鲁迅文集(小说、散文、杂文)全两册 普通
长征 昂贵
数据结构(C语言版)(附光盘) 昂贵
工作中无小事 普通
突破英文基础词汇 普通
噼里啪啦丛书(全7册) 昂贵
例 2 在 VERDOR 中如果 NAME 为中华书局或清华大学出版社,且 CREDIT 为 1 则返回“采购”,否则返回“考虑”。
SELECT NAME,
CASE
WHEN (NAME = '中华书局' OR NAME = '清华大学出版社') AND CREDIT = 1 THEN '采购'
ELSE '考虑'
END AS 选择
FROM PURCHASING.VENDOR;
查询结果如下:
NAME 选择
----------------- ----
上海画报出版社 考虑
长江文艺出版社 考虑
北京十月文艺出版社 考虑
人民邮电出版社 考虑
清华大学出版社 采购
中华书局 采购
广州出版社 考虑
上海出版社 考虑
21世纪出版社 考虑
外语教学与研究出版社 考虑
机械工业出版社 考虑
文学出版社 考虑
例 3 在上述表中将 NAME 为中华书局,CREDIT 为 1 的元组返回。
SELECT NAME, CREDIT FROM PURCHASING.VENDOR
WHERE NAME IN (SELECT CASE
WHEN CREDIT = 1 THEN '中华书局'
ELSE 'NOT EQUAL'
END
FROM PURCHASING.VENDOR);
查询结果如下:
NAME CREDIT
-------- -----------
中华书局 1
例 4 在上述表中,若 CREDIT 大于 1 则修改该值为 1。
UPDATE PURCHASING.VENDOR SET CREDIT = CASE
WHEN CREDIT > 1 THEN 1
ELSE CREDIT
END;
SELECT NAME, CREDIT FROM PURCHASING.VENDOR;
查询结果如下:
NAME CREDIT
------------------- -----------
上海画报出版社 1
长江文艺出版社 1
北京十月文艺出版社 1
人民邮电出版社 1
清华大学出版社 1
中华书局 1
广州出版社 1
上海出版社 1
21世纪出版社 1
外语教学与研究出版社 1
机械工业出版社 1
文学出版社 1
4.2 连接查询
如果一个查询包含多个表(>=2),则称这种方式的查询为连接查询。即 <FROM 子句 > 中使用的是 < 连接表 >。连接查询中,单个运算表达式包含的表个数不能超过 64。
DM 的连接查询方式包括:交叉连接(cross join)、自然连接(natural join)、内连接(inner)、外连接(outer)。下面分别举例说明。
4.2.1 交叉连接
- 无过滤条件
对连接的两张表记录做笛卡尔集,产生最终结果输出。
例 SALESPERSON 和 EMPLOYEE 通过交叉连接查询 HAIRDATE 和 SALESLASTYEAR。
SELECT T1.HAIRDATE, T2.SALESLASTYEAR FROM RESOURCES.EMPLOYEE T1 CROSS JOIN SALES.SALESPERSON T2;
查询结果如下:
HAIRDATE SALESLASTYEAR
---------- -------------
2002-05-02 10
2002-05-02 10
2002-05-02 10
2002-05-02 10
2002-05-02 10
2005-05-02 10
2002-05-02 10
2004-05-02 10
2002-05-02 20
2002-05-02 20
2002-05-02 20
2002-05-02 20
2002-05-02 20
2005-05-02 20
2002-05-02 20
2004-05-02 20
- 有过滤条件
对连接的两张表记录做笛卡尔集,根据 WHERE 条件进行过滤,产生最终结果输出。
例 查询性别为男性的员工的姓名与职务。
SELECT T1.NAME, T2.TITLE
FROM PERSON.PERSON T1, RESOURCES.EMPLOYEE T2
WHERE T1.PERSONID = T2.PERSONID AND T1.SEX = 'M';
查询结果如下:
NAME TITLE
---- ----------
王刚 销售经理
李勇 采购经理
黄非 采购代表
张平 系统管理员
本例中的查询数据必须来自 PERSON 和 EMPLOYEE 两个表。因此,应在 FROM 子句中给出这两个表的表名(为了简化采用了别名),在 WHERE 子句中给出连接条件(即要求两个表中 PERSONID 的列值相等)。当参加连接的表中出现相同列名时,为了避免混淆,可在这些列名前加表名前缀。
该例的查询结果是 PERSON 和 EMPLOYEE 在 PERSONID 列上做等值连接产生的。条件“T1.PERSONID=T2.PERSONID”称为连接条件或连接谓词。当连接运算符为“=”号时,称为等值连接,使用其它运算符则称非等值连接。
说明:
- 连接谓词中的列类型必须是可比较的,但不一定要相同,只要可以隐式转换即可;
- 不要求连接谓词中的列同名;
- 连接谓词中的比较操作符可以是>、>=、<、<=、=、< >;
- WHERE 子句中可同时包含连接条件和其它非连接条件。
4.2.2 自然连接(NATURAL JOIN)
把两张连接表中的同名列作为连接条件,进行等值连接,我们称这样的连接为自然连接。
自然连接具有以下特点:
- 连接表中存在同名列;
- 如果有多个同名列,则会产生多个等值连接条件;
- 如果连接表中的同名列类型不匹配,则报错处理。
例 查询销售人员的入职时间和去年销售总额。
SELECT HAIRDATE, SALESLASTYEAR FROM RESOURCES.EMPLOYEE NATURAL JOIN SALES.SALESPERSON;
查询结果如下:
HAIRDATE SALESLASTYEAR
---------- -------------
2002-05-02 10
2002-05-02 20
4.2.3 JOIN … USING
这是自然连接的另一种写法,JOIN 关键字指定连接的两张表,USING 指明连接列。要求 USING 中的列存在于两张连接表中。
例 查询销售人员的入职时间和去年销售总额。
SELECT HAIRDATE, SALESLASTYEAR FROM RESOURCES.EMPLOYEE JOIN SALES.SALESPERSON USING(EMPLOYEEID);
查询结果如下:
HAIRDATE SALESLASTYEAR
---------- -------------
2002-05-02 10
2002-05-02 20
4.2.4 JOIN … ON
这是一种连接查询的常用写法,说明是一个连接查询。JOIN 关键字指定连接的两张表,ON 子句指定连接条件表达式,其中不允许出现 ROWNUM。具体采用何种连接方式,由数据库内部分析确定。
例 查询销售人员的入职时间和去年销售总额。
SELECT T1.HAIRDATE,
T2.SALESLASTYEAR
FROM RESOURCES.EMPLOYEE T1 JOIN SALES.SALESPERSON T2
ON T1.EMPLOYEEID=T2.EMPLOYEEID;
查询结果如下:
HAIRDATE SALESLASTYEAR
---------- -------------
2002-05-02 10
2002-05-02 20
4.2.5 自连接
数据表与自身进行连接,我们称这种连接为自连接。
自连接查询至少要对一张表起别名,否则,服务器无法识别要处理的是哪张表。
例 对 PURCHASING.VENDOR 表进行自连接查询
SELECT T1.NAME, T2.NAME, T1.ACTIVEFLAG
FROM PURCHASING.VENDOR T1, PURCHASING.VENDOR T2
WHERE T1.NAME = T2.NAME;
查询结果如下:
NAME NAME ACTIVEFLAG
------------------ ------------------- ----------
上海画报出版社 上海画报出版社 1
文学出版社 文学出版社 1
机械工业出版社 机械工业出版社 1
外语教学与研究出版社 外语教学与研究出版社 1
21世纪出版社 21世纪出版社 1
上海出版社 上海出版社 1
广州出版社 广州出版社 1
中华书局 中华书局 1
清华大学出版社 清华大学出版社 1
人民邮电出版社 人民邮电出版社 1
北京十月文艺出版社 北京十月文艺出版社 1
长江文艺出版社 长江文艺出版社 1
4.2.6 内连接(INNER JOIN)
根据连接条件,结果集仅包含满足全部连接条件的记录,我们称这样的连接为内连接。
例 从 PRODUCT_CATEGORY、PRODUCT_SUBCATEGORY 中查询图书的目录名称和子目录名称。
SELECT T1.NAME, T2.NAME
FROM PRODUCTION.PRODUCT_CATEGORY T1 INNER JOIN
PRODUCTION.PRODUCT_SUBCATEGORY T2
ON T1.PRODUCT_CATEGORYID = T2.PRODUCT_CATEGORYID;
查询结果如下:
NAME NAME
---- --------------
小说 世界名著
少儿 少儿英语
少儿 励志
少儿 卡通
少儿 童话
少儿 益智游戏
少儿 幼儿启蒙
管理 财务管理
管理 经营管理
管理 商业道德
管理 质量管理与控制
管理 项目管理
管理 行政管理
英语 英语写作
英语 英语阅读
英语 英语口语
英语 英语听力
英语 英语语法
英语 英语词汇
计算机 多媒体
计算机 信息安全
计算机 软件工程
计算机 数据库
计算机 程序设计
计算机 操作系统
计算机 计算机体系结构
计算机 计算机理论
文学 民间文学
文学 戏剧
文学 中国现当代诗
文学 中国古诗词
文学 文学理论
文学 纪实文学
文学 文集
小说 社会
小说 军事
小说 四大名著
小说 科幻
小说 武侠
因为 PRODUCT_CATEGORY 中的 NAME 为金融的没有对应的子目录,所以结果集中没有金融类的图书信息。
4.2.7 外连接(OUTER JOIN)
外连接对结果集进行了扩展,会返回一张表的所有记录,对于另一张表无法匹配的字段用 NULL 填充返回。DM 数据库支持三种方式的外连接:左外连接、右外连接、全外连接。
外连接中常用到的术语:左表、右表。根据表所在外连接中的位置来确定,位于左侧的表,称为左表;位于右侧的表,称为右表。例如
SELECT * FROM T1 LEFT JOIN T2 ON T1.C1=T2.D1,T1 表为左表,T2 表为右表。
返回所有记录的表根据外连接的方式而定。
- 左外连接:返回左表所有记录;
- 右外连接:返回右表所有记录;
- 全外连接:返回两张表所有记录。处理过程为分别对两张表进行左外连接和右外连接,然后合并结果集。
在左外连接和右外连接中,如果需要对未能匹配的缺失数据进行填充,可以使用分区外连接(PARTITION OUTER JOIN),分区外连接通常用于处理稀疏数据以得到分析报表。
下面举例说明。
例 1 从 PRODUCT_CATEGORY、PRODUCT_SUBCATEGORY 中查询图书的所有目录名称和子目录名称,包括没有子目录的目录。
SELECT T1.NAME, T2.NAME
FROM PRODUCTION.PRODUCT_CATEGORY T1 LEFT OUTER JOIN
PRODUCTION.PRODUCT_SUBCATEGORY T2
ON T1.PRODUCT_CATEGORYID = T2.PRODUCT_CATEGORYID;
查询结果如下:
NAME NAME
---- ------------
小说 世界名著
小说 武侠
小说 科幻
小说 四大名著
小说 军事
小说 社会
文学 文集
文学 纪实文学
文学 文学理论
文学 中国古诗词
文学 中国现当代诗
文学 戏剧
文学 民间文学
计算机 计算机理论
计算机 计算机体系结构
计算机 操作系统
计算机 程序设计
计算机 数据库
计算机 软件工程
计算机 信息安全
计算机 多媒体
英语 英语词汇
英语 英语语法
英语 英语听力
英语 英语口语
英语 英语阅读
英语 英语写作
管理 行政管理
管理 项目管理
管理 质量管理与控制
管理 商业道德
管理 经营管理
管理 财务管理
少儿 幼儿启蒙
少儿 益智游戏
少儿 童话
少儿 卡通
少儿 励志
少儿 少儿英语
金融 NULL
例 2 从 PRODUCT_CATEGORY、PRODUCT_SUBCATEGORY 中查询图书的目录名称和所有子目录名称,包括没有目录的子目录。
SELECT T1.NAME, T2.NAME
FROM PRODUCTION.PRODUCT_CATEGORY T1 RIGHT OUTER JOIN
PRODUCTION.PRODUCT_SUBCATEGORY T2
ON T1.PRODUCT_CATEGORYID = T2.PRODUCT_CATEGORYID;
查询结果如下:
NAME NAME
---- ----------
小说 世界名著
小说 武侠
小说 科幻
小说 四大名著
小说 军事
小说 社会
NULL 历史
文学 文集
文学 纪实文学
文学 文学理论
文学 中国古诗词
文学 中国现当代诗
文学 戏剧
文学 民间文学
计算机 计算机理论
计算机 计算机体系结构
计算机 操作系统
计算机 程序设计
计算机 数据库
计算机 软件工程
计算机 信息安全
计算机 多媒体
英语 英语词汇
英语 英语语法
英语 英语听力
英语 英语口语
英语 英语阅读
英语 英语写作
管理 行政管理
管理 项目管理
管理 质量管理与控制
管理 商业道德
管理 经营管理
管理 财务管理
少儿 幼儿启蒙
少儿 益智游戏
少儿 童话
少儿 卡通
少儿 励志
少儿 少儿英语
例 3 从 PRODUCT_CATEGORY、PRODUCT_SUBCATEGORY 中查询图书的所有目录名称和所有子目录名称。
SELECT T1.NAME, T2.NAME
FROM PRODUCTION.PRODUCT_CATEGORY T1 FULL OUTER JOIN
PRODUCTION.PRODUCT_SUBCATEGORY T2 ON T1.PRODUCT_CATEGORYID = T2.PRODUCT_CATEGORYID;
查询结果如下:
NAME NAME
---- ----------
小说 世界名著
小说 武侠
小说 科幻
小说 四大名著
小说 军事
小说 社会
NULL 历史
文学 文集
文学 纪实文学
文学 文学理论
文学 中国古诗词
文学 中国现当代诗
文学 戏剧
文学 民间文学
计算机 计算机理论
计算机 计算机体系结构
计算机 操作系统
计算机 程序设计
计算机 数据库
计算机 软件工程
计算机 信息安全
计算机 多媒体
英语 英语词汇
英语 英语语法
英语 英语听力
英语 英语口语
英语 英语阅读
英语 英语写作
管理 行政管理
管理 项目管理
管理 质量管理与控制
管理 商业道德
管理 经营管理
管理 财务管理
少儿 幼儿启蒙
少儿 益智游戏
少儿 童话
少儿 卡通
少儿 励志
少儿 少儿英语
金融 NULL
外连接还有一种写法,在连接条件或 WHERE 条件中,在列后面增加(+)指示左外连接或者右外连接。如果表 A 和表 B 连接,连接条件或者 where 条件中,A 的列带有(+)后缀,则认为是 B LEFT JOIN A。带有(+)后缀的列不能连接到子查询。如果(+)引起了外连接环,则报错。在使用过程中需要注意,如果连接的列是虚拟列,则不支持这种写法。下面举例说明。
例 4 从 PRODUCT_CATEGORY、PRODUCT_SUBCATEGORY 中查询图书的目录名称和所有子目录名称,包括没有目录的子目录。
SELECT T1.NAME, T2.NAME
FROM PRODUCTION.PRODUCT_CATEGORY T1, PRODUCTION.PRODUCT_SUBCATEGORY T2
WHERE T1.PRODUCT_CATEGORYID(+) = T2.PRODUCT_CATEGORYID;
查询结果与例 2 所示结果一致。
例 5 新建产品区域销售统计表 SALES.SALESREGION 并插入数据。
CREATE TABLE SALES.SALESREGION(REGION CHAR(10), PRODUCTID INT, AMOUNT INT);
INSERT INTO SALES.SALESREGION VALUES('大陆', 2, 19800);
INSERT INTO SALES.SALESREGION VALUES('大陆', 4, 20090);
INSERT INTO SALES.SALESREGION VALUES('港澳台', 6, 5698);
INSERT INTO SALES.SALESREGION VALUES('外国', 9, 3756);
COMMIT;
统计每个产品在各个区域的销售量,没有销售则显示 NULL,此时可使用 PARTITON OUTER JOIN 将稀疏数据转为稠密数据。
SELECT A.PRODUCTID, B.REGION, B.AMOUNT
FROM PRODUCTION.PRODUCT A LEFT JOIN SALES.SALESREGION B
PARTITION BY(B.REGION) ON A.PRODUCTID=B.PRODUCTID
ORDER BY A.PRODUCTID, B.REGION;
查询结果如下:
PRODUCTID REGION AMOUNT
---------- ------- -----------
1 大陆 NULL
1 港澳台 NULL
1 外国 NULL
2 大陆 19800
2 港澳台 NULL
2 外国 NULL
3 大陆 NULL
3 港澳台 NULL
3 外国 NULL
4 大陆 20090
4 港澳台 NULL
4 外国 NULL
5 大陆 NULL
5 港澳台 NULL
5 外国 NULL
6 大陆 NULL
6 港澳台 5698
6 外国 NULL
7 大陆 NULL
7 港澳台 NULL
7 外国 NULL
8 大陆 NULL
8 港澳台 NULL
8 外国 NULL
9 大陆 NULL
9 港澳台 NULL
9 外国 3756
10 大陆 NULL
10 港澳台 NULL
10 外国 NULL
4.2.8 JOIN APPLY
JOIN APPLY 是指连接中的右表可以引用左表列,即同层列引用。通过对 APPLY 右侧输入求值来获得左侧输入每一行的计算结果,生成的行最终组合起来作为最终结果。CROSS APPLY 与 CROSS JOIN 功能类似,相当于不包含连接条件的 CROSS JOIN。OUTER APPLY 与 LEFT OUTER JOIN 功能类似,相当于不包含连接条件的 LEFT OUTER JOIN。
例1 CROSS APPLY右侧输入没有左侧输入的相关条件时,等价于CROSS JOIN。
--数据准备
CREATE TABLE T1(C1 INT,C2 INT);
CREATE TABLE T2(D1 INT,D2 INT);
INSERT INTO T1 VALUES(1,1);
INSERT INTO T1 VALUES(2,2);
INSERT INTO T2 VALUES(2,2);
INSERT INTO T2 VALUES(3,3);
COMMIT;
--查询
SELECT * FROM T1 CROSS APPLY T2;
查询结果如下:
C1 C2 D1 D2
---------- ----------- ----------- -----------
1 1 2 2
1 1 3 3
2 2 2 2
2 2 3 3
例 2 CROSS APPLY 右侧输入有左侧输入的相关条件时,通过对 CROSS APPLY 右侧输入求值来获得左侧输入每一行的计算结果,生成的结果行最终组合起来作为最终结果。
SELECT * FROM T1 CROSS APPLY(SELECT * FROM T2 WHERE C1=D1);
查询结果如下:
C1 C2 D1 D2
---------- ----------- ----------- -----------
2 2 2 2
例 3 OUTER APPLY 结果集中既会返回结果集的行,又会返回不生成结果集的行。不生成结果集的行左孩子原样输出,右孩子补 NULL。
SELECT * FROM T1 OUTER APPLY(SELECT * FROM T2 WHERE C1=D1);
查询结果如下:
C1 C2 D1 D2
---------- ----------- ----------- -----------
1 1 NULL NULL
2 2 2 2
4.3 子查询
在 DM_SQL 语言中,一个 SELECT-FROM-WHERE 语句称为一个查询块,如果在一个查询块中嵌套一个或多个查询块,我们称这种查询为子查询。子查询会返回一个值(标量子查询)或一个表(表子查询)。它通常采用(SELECT…)的形式嵌套在表达式中。子查询语法如下:
<子查询> ::= (<查询表达式>)
即子查询是嵌入括弧的 < 查询表达式 >,而这个 < 查询表达式 > 通常是一个 SELECT 语句。它有下列限制:
- 子查询允许 TEXT 类型与 CHAR 类型值比较。比较时,取出 TEXT 类型字段的最多 32767 字节与 CHAR 类型字段进行比较;
- 在子查询中允许嵌套子查询。
按子查询返回结果的形式,DM 子查询可分为两大类:
- 标量子查询:只返回一行一列;
- 表子查询:可返回多行多列。
4.3.1 标量子查询
标量子查询是一个普通 SELECT 查询,它只应该返回一行一列记录。如果返回结果多于一行则会提示单行子查询返回多行,返回结果多于一列则会提示 SELECT 语句列数超长。
下面是一个标量子查询的例子(请先关闭自动提交功能,否则 COMMIT 与 ROLLBACK 会失去效果):
SELECT 'VALUE IS', (SELECT ADDRESS1 FROM PERSON.ADDRESS WHERE ADDRESSID =
1)
FROM PERSON.ADDRESS_TYPE;
//子查询只有一列,结果正确
SELECT 'VALUE IS', LEFT((SELECT ADDRESS1 FROM PERSON. ADDRESS WHERE ADDRESSID = 1), 8) FROM PERSON.ADDRESS_TYPE;
//函数+标量子查询,结果正确
SELECT 'VALUE IS', (SELECT ADDRESS1, CITY FROM PERSON.ADDRESS WHERE ADDRESSID = 1) FROM PERSON.ADDRESS_TYPE;
//返回列数不为1,报错
SELECT 'VALUES IS', (SELECT ADDRESS1 FROM PERSON.ADDRESS) FROM PERSON.ADDRESS_TYPE;
//查询返回行值多于一个,报错
DELETE FROM SALES.SALESORDER_DETAIL;
SELECT 'VALUE IS', (SELECT ORDERQTY FROM SALES.SALESORDER_DETAIL) FROM SALES.CUSTOMER;
//子查询有0行,结果返回NULL
UPDATE PRODUCTION.PRODUCT SET PUBLISHER =
(SELECT NAME FROM PURCHASING.VENDOR WHERE VENDORID = 2)
WHERE PRODUCTID = 5;
UPDATE PRODUCTION.PRODUCT_VENDOR SET STANDARDPRICE =
(SELECT AVG(NOWPRICE) FROM PRODUCTION.PRODUCT)
WHERE PRODUCTID = 1;
//Update语句中允许使用标量子查询
INSERT INTO PRODUCTION.PRODUCT_CATEGORY(NAME) VALUES
(( SELECT NAME FROM PRODUCTION.PRODUCT_SUBCATEGORY
WHERE PRODUCT_SUBCATEGORYID= 40));
//Insert语句中允许使用标量子查询
例如,查询通常价格最小的供应商的名称和最小价格:
SELECT NAME, (SELECT MIN(STANDARDPRICE)
FROM PRODUCTION.PRODUCT_VENDOR T1
WHERE T1.VENDORID = T2.VENDORID)
FROM PURCHASING.VENDOR T2;
4.3.2 表子查询
和标量子查询不同的是,表子查询的查询结果可以是多行多列。
一般情况下,表子查询类似标量子查询,单列构成了表子查询的选择清单,但它的查询结果允许返回多行。可以从上下文中区分出表子查询:在其前面始终有一个只对表子查询的算符:<比较算符>ALL、<比较算符>ANY(或是其同义词<比较算符> SOME)、IN 和 EXISTS。
其中,在 IN/NOT IN 表子查询的情况下,DM 支持查询结果返回多列。
例 1 查询职务为销售代表的员工的编号、今年销售总额和去年销售总额。
SELECT EMPLOYEEID, SALESTHISYEAR, SALESLASTYEAR
FROM SALES.SALESPERSON
WHERE EMPLOYEEID IN
( SELECT EMPLOYEEID
FROM RESOURCES.EMPLOYEE
WHERE TITLE = '销售代表'
);
查询结果如下:
EMPLOYEEID SALESTHISYEAR SALESLASTYEAR
----------- ------------- -------------
4 8 10
5 8 20
该查询语句的求解方式是:首先通过子查询“SELECT EMPLOYEEID FROM RESOURCES.EMPLOYEE WHERE TITLE = '销售代表'”查到职务为销售代表的 EMPLOYEEID 的集合,然后,在 SALESPERSON 表中找到与子查询结果集中的 EMPLOYEEID 所对应员工的 SALESTHISYEAR 和 SALESLASTYEAR。
在带有子查询的查询语句中,通常也将子查询称内层查询或下层查询。由于子查询还可以嵌套子查询,相对于下一层的子查询,上层查询又称为父查询或外层查询。
由于 DM_SQL 语言所支持的嵌套查询功能可以将一系列简单查询构造成复杂的查询,从而有效地增强了 DM_SQL 语句的查询功能。以嵌套的方式构造语句是 DM_SQL 的“结构化”的特点。
需要说明的是:上例的外层查询只能用 IN 谓词而不能用比较算符“=”,因为子查询的结果包含多个元组,除非能确定子查询的结果只有一个元组时,才可用等号比较。上例语句也可以用连接查询的方式实现。
SELECT T1.EMPLOYEEID, T1.SALESTHISYEAR, T1.SALESLASTYEAR
FROM SALES.SALESPERSON T1 , RESOURCES.EMPLOYEE T2
WHERE T1.EMPLOYEEID = T2.EMPLOYEEID AND T2.TITLE = '销售代表';
例 2 查询对目录名为小说的图书进行评论的人员名称和评论日期。
采用子查询嵌套方式写出以下查询语句:
SELECT DISTINCT NAME, REVIEWDATE
FROM PRODUCTION.PRODUCT_REVIEW
WHERE PRODUCTID IN
( SELECT PRODUCTID
FROM PRODUCTION.PRODUCT
WHERE PRODUCT_SUBCATEGORYID IN
( SELECT PRODUCT_SUBCATEGORYID
FROM PRODUCTION.PRODUCT_SUBCATEGORY
WHERE PRODUCT_CATEGORYID IN
( SELECT PRODUCT_CATEGORYID
FROM PRODUCTION.PRODUCT_CATEGORY
WHERE NAME = '小说'
)
)
);
查询结果如下:
NAME REVIEWDATE
------ ----------
刘青 2007-05-06
桑泽恩 2007-05-06
该语句采用了四层嵌套查询方式,首先通过最内层子查询从 PRODUCT_CATEGORY 中查出目录名为小说的目录编号,然后从 PRODUCT_SUBCATEGORY 中查出这些目录编号对应的子目录编号,接着从 PRODUCT 表中查出这些子目录编号对应的图书的编号,最后由最外层查询查出这些图书编号对应的评论人员和评论日期。
此例也可用四个表的连接来完成。
从上例可以看出,当查询涉及到多个基表时,嵌套子查询与连接查询相比,前者由于是逐步求解,层次清晰,易于阅读和理解,具有结构化程序设计的优点。
在许多情况下,外层子查询与内层子查询常常引用同一个表,如下例所示。
例 3 查询当前价格低于红楼梦的图书的名称、作者和当前价格。
SELECT NAME, AUTHOR, NOWPRICE
FROM PRODUCTION.PRODUCT
WHERE NOWPRICE < ( SELECT NOWPRICE FROM PRODUCTION.PRODUCT
WHERE NAME = '红楼梦');
查询结果如下:
NAME AUTHOR NOWPRICE
--------------- ----------------- --------
水浒传 施耐庵,罗贯中 14.3
老人与海 海明威 6.1
工作中无小事 陈满麒 11.4
突破英文基础词汇 刘毅 11.1
此例的子查询与外层查询尽管使用了同一表名,但作用是不一样的。子查询是在该表中红楼梦的图书价格,而外查询是在 PRODUCT 表 NOWPRICE 列查找小于该值的集合,从而得到这些值所对应的名称和作者。DM_SQL 语言允许为这样的表引用定义别名:
SELECT NAME, AUTHOR, NOWPRICE
FROM PRODUCTION.PRODUCT T1
WHERE T1.NOWPRICE < ( SELECT T2.NOWPRICE
FROM PRODUCTION.PRODUCT T2
WHERE T2.NAME = '红楼梦');
该语句也可以采用连接方式实现:
SELECT T1.NAME, T1.AUTHOR, T1.NOWPRICE
FROM PRODUCTION.PRODUCT T1 , PRODUCTION.PRODUCT T2
WHERE T2.NAME = '红楼梦' AND T1.NOWPRICE < T2.NOWPRICE;
例 4 查询图书的出版社和产品供应商名称相同的图书编号和名称。
SELECT T1.PRODUCTID, T1.NAME
FROM PRODUCTION.PRODUCT T1, PRODUCTION.PRODUCT_VENDOR T2
WHERE T1.PRODUCTID = T2.PRODUCTID AND T1.PUBLISHER = ANY
( SELECT NAME FROM PURCHASING.VENDOR T3
WHERE T2.VENDORID = T3.VENDORID);
查询结果如下:
PRODUCTID NAME
----------- -------------------------
1 红楼梦
2 水浒传
3 老人与海
4 射雕英雄传(全四册)
7 数据结构(C语言版)(附光盘)
8 工作中无小事
9 突破英文基础词汇
10 噼里啪啦丛书(全7册)
此例有一点需要注意:子查询的 WHERE 子句涉及到 PRODUCT_VENDOR.VENDORID(即 T2.VENDORID),但是其 FROM 子句中却没有提到 PRODUCT_VENDOR。在外部子查询 FROM 子句中命名了 PRODUCT_VENDOR——这就是外部引用。当一个子查询含有一个外部引用时,它就与外部语句相关联,称这种子查询为相关子查询。
例 5 查询图书的出版社和产品供应商名称不相同的图书编号和名称。
SELECT T1.PRODUCTID, T1.NAME
FROM PRODUCTION.PRODUCT T1
WHERE T1.PUBLISHER <> ALL(SELECT NAME FROM PURCHASING.VENDOR );
查询结果如下:
PRODUCTID NAME
----------- --------------------------------
6 长征
5 鲁迅文集(小说、散文、杂文)全两册
4.3.3 派生表子查询
派生表子查询是一种特殊的表子查询。所谓派生表是指 FROM 子句中的查询表达式,可以以别名对其进行引用。在 SELECT 语句的 FROM 子句中可以包含一个或多个派生表。派生表嵌套层次不能超过 60 层。
例 查询每个目录的编号、名称和对应的子目录的数量,并按数量递减排列。
SELECT T1.PRODUCT_CATEGORYID, T1.NAME, T2.NUM
FROM PRODUCTION.PRODUCT_CATEGORY T1,
( SELECT PRODUCT_CATEGORYID, COUNT(PRODUCT_SUBCATEGORYID)
FROM PRODUCTION.PRODUCT_SUBCATEGORY
GROUP BY PRODUCT_CATEGORYID
) AS T2(PRODUCT_CATEGORYID,NUM)
WHERE T1.PRODUCT_CATEGORYID = T2.PRODUCT_CATEGORYID
ORDER BY T2.NUM
DESC;
查询结果如下:
PRODUCT_CATEGORYID NAME NUM
------------------ ------ --------------------
3 计算机 8
2 文学 7
6 少儿 6
5 管理 6
4 英语 6
1 小说 6
4.3.4 定量比较
量化符 ALL、SOME、ANY 可以用于将一个<数据类型>的值和一个由表子查询返回的值的集合进行比较。
1.ALL
ALL 定量比较要求的语法如下:
<标量表达式> <比较算符> ALL <表子查询>
其中:
1)< 标量表达式>可以是对任意单值计算的表达式;
2)< 比较算符>包括 =、>、<、>=、<= 或 <>。
若表子查询返回 0 行或比较算符对表子查询返回的每一行都为 TRUE,则返回 TRUE。若比较算符对于表子查询返回的至少一行是 FALSE,则 ALL 返回 FALSE。
例 1 查询没有分配部门的员工的编号、姓名和身份证号码。
SELECT T1.EMPLOYEEID, T2.NAME, T1.NATIONALNO
FROM RESOURCES.EMPLOYEE T1 , PERSON.PERSON T2
WHERE T1.PERSONID = T2.PERSONID AND T1.EMPLOYEEID <> ALL
( SELECT EMPLOYEEID FROM RESOURCES.EMPLOYEE_DEPARTMENT);
查询结果如下:
EMPLOYEEID NAME NATIONALNO
----------- ---- ------------------
7 王菲 420921197708051523
例 2 查询比中华书局所供应的所有图书都贵的图书的编号、名称和现在销售价格。
SELECT PRODUCTID, NAME, NOWPRICE
FROM PRODUCTION.PRODUCT
WHERE NOWPRICE > ALL
( SELECT T1.NOWPRICE
FROM PRODUCTION.PRODUCT T1 , PRODUCTION.PRODUCT_VENDOR T2
WHERE T1.PRODUCTID = T2.PRODUCTID AND T2.VENDORID =
( SELECT VENDORID FROM PURCHASING.VENDOR
WHERE NAME = '中华书局'
)
)
AND PRODUCTID <> ALL
( SELECT T1.PRODUCTID
FROM PRODUCTION.PRODUCT_VENDOR T1 , PURCHASING.VENDOR T2
WHERE T1.VENDORID = T2.VENDORID AND T2.NAME = '中华书局'
);
查询结果如下:
PRODUCTID NAME NOWPRICE
----------- ----------------------------- --------
10 噼里啪啦丛书(全7册) 42
7 数据结构(C语言版)(附光盘) 25.5
6 长征 37.7
5 鲁迅文集(小说、散文、杂文)全两册 20
4 射雕英雄传(全四册) 21.7
2.ANY 或 SOME
ANY 或 SOME 定量比较要求的语法如下:
<标量表达式> <比较算符> ANY | SOME <表子查询>
SOME 和 ANY 是同义词。如果它们对于表子查询返回的至少一行为 TRUE,则返回为 TRUE。若表子查询返回 0 行或比较算符对表子查询返回的每一行都为 FALSE,则返回 FALSE。
ANY 和 ALL 与集函数的对应关系如表 4.3.1 所示。
| = | <> | < | <= | > | >= | |
|---|---|---|---|---|---|---|
| ANY | IN | 不存在 | <MAX | <=MAX | >MIN | >=MIN |
| ALL | 不存在 | NOT IN | <MIN | <=MIN | >MAX | >=MAX |
在具体使用时,读者完全可根据自己的习惯和需要选用。
4.3.5 带 EXISTS 谓词的子查询
带 EXISTS 谓词的子查询语法如下:
<EXISTS谓词> ::= [NOT] EXISTS <表子查询>
EXISTS 判断是对非空集合的测试并返回 TRUE 或 FALSE。若表子查询返回至少一行,则 EXISTS 返回 TRUE,否则返回 FALSE。若表子查询返回 0 行,则 NOT
EXISTS 返回 TRUE,否则返回 FALSE。
例 查询职务为销售代表的员工的编号和入职时间。
SELECT T1.EMPLOYEEID , T1.STARTDATE
FROM RESOURCES.EMPLOYEE_DEPARTMENT T1
WHERE EXISTS
( SELECT * FROM RESOURCES.EMPLOYEE T2
WHERE T2.EMPLOYEEID = T1.EMPLOYEEID AND T2.TITLE = '销售代表');
查询结果如下:
EMPLOYEEID STARTDATE
----------- ----------
4 2005-02-01
5 2005-02-01
此例查询需要 EMPLOYEE_DEPARTMENT 表和 EMPLOYEE 表中的数据,其执行方式为:首先在 EMPLOYEE_DEPARTMENT 表的第一行取 EMPLOYEEID 的值为 2,这样对内层子查询则为:
(SELECT * FROM RESOURCES.EMPLOYEE T2
WHERE T2.EMPLOYEEID='2' AND T2.TITLE='销售代表');
在 EMPLOYEE 表中,不存在满足该条件的行,子查询返回值为假,说明不能取 EMPLOYEE_DEPARTMENT 表的第一行作为结果。系统接着取 EMPLOYEE_DEPARTMENT 表的第二行,又得到 EMPLOYEEID 的值为 4,执行内层查询,此时子查询返回值为真,说明可以取该行作为结果。重复以上步骤……。只有外层子查询 WHERE 子句结果为真时,方可将 EMPLOYEE_DEPARTMENT 表中的对应行送入结果表,如此继续,直到把 EMPLOYEE_DEPARTMENT 表的各行处理完。
从以上分析得出,EXISTS 子查询的查询结果与外表相关,即连接条件中包含内表和外表列,我们称这种类型的子查询为相关子查询;反之,子查询的连接条件不包含外表列,即查询结果不受外表影响,我们称这种类型的子查询为非相关子查询。
4.3.6 多列表子查询
为了满足应用需求,DM 数据库扩展了子查询功能,目前支持多列 IN/NOT IN 子查询。
子查询可以是值列表或者查询块。
例 1 查询活动标志为 1 且信誉为 2 的供应商编号和名称。
SELECT VENDORID, NAME
FROM PURCHASING.VENDOR
WHERE (ACTIVEFLAG, CREDIT) IN ((1, 2));
查询结果如下:
VENDORID NAME
----------- --------------
1 上海画报出版社
2 长江文艺出版社
上例中子查询的选择清单为多列,而看到子查询算符后面跟着的形如((1,2))的表达式我们称之为多列表达式链表,这个多列表达式链表以一个或多个多列数据集构成的集合构成。上述的例子中的多列表达式链表中的元素有两个。
例 2 查询作者为海明威且出版社为上海出版社或作者为王树增且出版社为人民文学出版社的图书名称和现在销售价格。
SELECT NAME, NOWPRICE
FROM PRODUCTION.PRODUCT
WHERE (AUTHOR, PUBLISHER) IN
(( '海明威', '上海出版社'), ('王树增', '人民文学出版社'));
查询结果如下:
NAME NOWPRICE
-------- --------
老人与海 6.1
长征 37.7
子查询为值列表时,需要注意以下三点:
- 值列表需要用括号;
- 值列表之间以逗号分割;
- 值列表的个数与查询列个数相同。
子查询为查询块的情况如下例所示:
例 3
查询由采购代表下的供应商是清华大学出版社的订单的创建日期、状态和应付款总额。
SELECT ORDERDATE, STATUS, TOTAL
FROM PURCHASING.PURCHASEORDER_HEADER
WHERE (EMPLOYEEID, VENDORID) IN
(SELECT T1.EMPLOYEEID, T2.VENDORID
FROM RESOURCES.EMPLOYEE T1, PURCHASING.VENDOR T2
WHERE T1.TITLE = '采购代表' AND T2.NAME = '清华大学出版社');
查询结果如下:
ORDERDATE STATUS TOTAL
---------- ----------- ---------
2006-07-21 1 6400
由例子可以看到,WHERE 子句中有两个条件列,IN 子查询的查询项也由两列构成。
DM 对多列子查询的支持,满足了更多的应用场景。
4.4 WITH 子句
WITH 子句语法如下:
<WITH 子句> ::= [<WITH FUNCTION子句>] [<WITH CTE子句>]
4.4.1 WITH FUNCTION 子句
WITH FUNCTION 子句用于在 SQL 语句中临时声明并定义存储函数,这些存储函数可以在其作用域内被引用。相比模式对象中的存储函数,通过 WITH FUNCTION 定义的存储函数在对象名解析时拥有更高的优先级。
和公用表表达式 CTE 类似,WITH FUNCTION 定义的存储函数对象也不会存储到系统表中,且只在当前 SQL 语句内有效。
WITH FUNCTION 子句适用于偶尔需要使用存储函数的场景。和模式对象中的存储函数相比,它可以清楚地看到函数定义并避免了 DDL 操作带来的开销。
语法格式
WITH [RECURSIVE] <函数> {<函数>}
参数
1.<函数> 语法遵照《DM8_SQL 程序设计》中存储函数的语法规则。
图例
with function 子句
语句功能
供用户定义同一语句内临时使用的存储函数。
使用说明
- <WITH FUNCTION 子句>中定义的函数的作用域为<WITH 子句>所在的查询表达式内;
- 同一<WITH FUNCTION 子句>中函数名不得重复;
- <WITH FUNCTION 子句> 中定义的函数不能是自定义集函数和外部函数;
- 该语句的使用者并不需要 CREATE PROCEDURE 数据库权限。
举例说明
例 1 WITH FUNCTION 中定义的函数优先级高于模式对象的例子。
WITH FUNCTION f1(C INT) RETURN INT AS BEGIN RETURN C \* 10; END;
SELECT f1(5236) FROM DUAL;
/
查询结果如下:
52360
例 2 WITH FUNCTION 和公用表表达式混合的例子。
WITH FUNCTION f21(C1 INT) RETURN INT AS BEGIN RETURN C1; END;
SELECT f21(1) FROM dual WHERE 100 IN
(
WITH FUNCTION f22(C1 INT) RETURN INT AS BEGIN RETURN C1 + 2; END;
FUNCTION f23(C1 INT) RETURN INT AS BEGIN RETURN C1 - 2; END;
v21(C) AS (SELECT 50 FROM dual)
SELECT f22(C) +f23(C) FROM v21
);
/
查询结果如下:
1
4.4.2 WITH CTE 子句
嵌套 SQL 语句如果层次过多,会使 SQL 语句难以阅读和维护。如果将子查询放在临时表中,会使 SQL 语句更容易维护,但同时也增加了额外的 I/O 开销,因此,临时表并不太适合数据量大且频繁查询的情况。为此,在 DM 中引入了公用表表达式(CTE,COMMON TABLE EXPRESSION),使用 CTE 可以提高 SQL 语句的可维护性,同时 CTE 要比临时表的效率高很多。
CTE 与派生表类似,具体表现在不存储为对象,并且只在查询期间有效。与派生表的不同之处在于,CTE 可自引用,还可在同一查询中引用多次。
WITH CTE 子句会定义一个公用表达式,该公用表达式会被整个 SQL 语句所用到。它可以有效提高 SQL 语句的可读性,也可以用在 UNION ALL 中,作为提供数据的部分。
WITH CTE 子句根据 CTE 是否递归执行 CTE 自身,DM 将 WITH CTE 子句分为递归 WITH 和非递归 WITH 两种情况。
4.4.2.1 公用表表达式的作用
公用表表达式(CTE)是一个在查询中定义的临时命名结果集,将在 FROM 子句中使用它。每个 CTE 仅被定义一次(但在其作用域内可以被引用任意次),并且在该查询生存期间将一直生存,而且可以使用 CTE 来执行递归操作。
因为 UNION ALL 的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高,所以可以使用 WITH CTE 子句,则只要执行一遍即可。如果 WITH CTE 子句所定义的表名被调用两次以上,则优化器会自动将 WITH CTE 子句所获取的数据放入一个临时表里,如果只是被调用一次则不会,很多查询通过这种方法都可以提高速度。
4.4.2.2 非递归 WITH 的使用
语法格式
WITH [RECURSIVE] <非递归with cte子句>{,<非递归with cte子句>}<cte查询语句>;
<非递归with cte子句>::= <公用表表达式的名称> [<列名> ({,<列名>})] AS ( <公用表表达式子查询语句>)
参数
1.RECURSIVE 一般为可选项,但在使用 RECURSIVE 本身作为公用表表达式的名称时,RECURSIVE 为必选项,即需要写成 WITH RECURSIVE RECURSIVE()的形式。
2.<列名> 指明被创建的公用表表达式中列的名称。
3.<公用表表达式子查询语句> 标识公用表表达式所基于的表的行和列,其语法遵照 SELECT 语句的语法规则。
图例
非递归 with
<非递归 with cte 子句>

语句功能
供用户定义非递归公用表表达式,也就是非递归 WITH 语句。
使用说明
- < 公用表表达式的名称 >必须与在同一 WITH 子句中定义的任何其他公用表表达式的名称不同,但公用表表达式名可以与基表或基视图的名称相同。在查询中对公用表表达式名的任何引用都会使用公用表表达式,而不使用基对象;
- 在一个 CTE 定义中不允许出现重复的列名。指定的列名数必须与<公用表表达式子查询语句>结果集中列数匹配。只有在查询定义中为所有结果列都提供了不同的名称时,列名称列表才是可选的;
- <公用表表达式子查询语句>指定一个结果集填充公用表表达式的 SELECT 语句。除了 CTE 不能定义另一个 CTE 以外,<公用表表达式子查询语句> 的 SELECT 语句必须满足与创建视图时相同的要求;
- <cte 查询语句> 支持 SELECT、UPDATE、DELETE 和 INSERT 语句,用户对语句中涉及的表必须具备相应的 SELECT、UPDATE、DELETE 或 INSERT 权限。此处,语法上 <cte 查询语句 > 支持任意 SELECT、UPDATE、DELETE 和 INSERT 语句,但是对于 CTE 而言,只有 <cte 查询语句 > 中使用 < 公用表表达式的名称 >,CTE 才有意义。
举例说明
例 1 创建一个表 TEST1 和表 TEST2,并利用公用表表达式对它们进行连接运算。
CREATE TABLE TEST1(I INT);
INSERT INTO TEST1 VALUES(1);
INSERT INTO TEST1 VALUES(2);
CREATE TABLE TEST2(J INT);
INSERT INTO TEST2 VALUES(5);
INSERT INTO TEST2 VALUES(6);
INSERT INTO TEST2 VALUES(7);
WITH CTE1(K) AS(SELECT I FROM TEST1 WHERE I > 1),
CTE2(G) AS(SELECT J FROM TEST2 WHERE J > 5)
SELECT K, G FROM CTE1, CTE2;
查询结果如下:
K G
--------- -----------
2 6
2 7
例 2 利用公用表表达式,更新表 TEST1 中的数据。
WITH CTE1(K) AS(SELECT I FROM TEST1) UPDATE CTE1 SET K=K+1;
查询表 TEST1 中的数据。
SELECT * FROM TEST1;
查询结果如下:
I
-----------
2
3
例 3 利用公用表表达式,删除表 TEST2 中的数据。
WITH CTE1(K) AS(SELECT J FROM TEST2) DELETE FROM CTE1 WHERE K=5;
查询表 TEST2 中的数据。
SELECT * FROM TEST2;
查询结果如下:
J
-----------
6
7
例 4 利用公用表表达式,往 TEST3 中插入数据。
DROP TABLE TEST1;
CREATE TABLE TEST1(I INT);
INSERT INTO TEST1 VALUES(1);
INSERT INTO TEST1 VALUES(2);
CREATE TABLE TEST3(C1 INT);
WITH CTE1(K) AS(SELECT I FROM TEST1) INSERT INTO TEST3 TABLE CTE1;
查询表 TEST3 中的数据。
SELECT * FROM TEST3;
查询结果如下:
C1
----------
1
2
4.4.2.3 递归 WITH 的使用
递归 WITH 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式。递归 WITH 通常用于返回分层数据。
语法格式
WITH [RECURSIVE] <递归with cte子句>{,<递归with cte子句>}<cte查询语句>;
<递归with cte子句>::=<公用表表达式的名称> (<列名>{,<列名>}) AS (<定位点成员> UNION ALL <递归成员>)
参数
1.RECURSIVE 一般为可选项,但在使用 RECURSIVE 本身作为公用表表达式的名称时,RECURSIVE 为必选项,即需要写成 WITH RECURSIVE RECURSIVE()的形式。
2.<列名> 指明被创建的递归 WITH 中列的名称;各列不能同名,列名和 AS 后的列名没有关系,类似建视图时为视图指定的列别名。
3.< 定位点成员> 任何不包含< 公用表表达式的名称> 的 SELECT 查询语句。定位点成员的查询结果集是递归成员迭代的基础。
4.<递归成员> 引用<公用表表达式的名称>的 SELECT 查询语句。递归成员通过引用自身<公用表表 4 式的名称>反复迭代执行,下一次迭代的数据基于上一次迭代的查询结果,当且仅当本次迭代结果为空集时才终止迭代。
5.<cte 查询语句> SELECT 查询语句。此处,语法上<cte 查询语句>支持任意 SELECT 语句,但是对于 CTE 而言,只有<cte 查询语句>中使用<公用表表达式的名称>,CTE 才有意义。
图例
递归 with
<递归 with cte 子句>

语句功能
供用户定义递归公用表表达式,也就是递归 WITH 语句。
与递归 WITH 有关的两个 INI 参数为 CTE_MAXRECURSION 和 CTE_OPT_FLAG。CTE_MAXRECURSION 用来指定递归 CTE 迭代层次,取值范围 1~ULINT_MAX,缺省为 100。CTE_OPT_FLAG 用来指定递归 WITH 相关子查询是否转换为 WITH FUNCTION 优化,取值 0 或 1,缺省为 1。
递归 WITH 的执行流程如下:
- 将递归 WITH 拆分为定位点成员和递归成员;
- 运行定位点成员,创建第一个基准结果集 (T0);
- 运行递归成员,将 TI 作为输入(初始 i=0),将 TI+1 作为输出,I=I++;
- 重复步骤 3,直到返回空集;
- 返回结果集为 T0 到 TN 执行 UNION ALL 的结果。
使用说明
- <公用表表达式的名称>在定位点成员中不能出现。<公用表表达式的名称>在递归成员中有且只能引用一次;
- 递归成员中不能包含下面元素:
- DISTINCT;
- GROUP BY;
- 集函数,但支持分析函数;
- <公用表表达式的名称>不能作为<递归成员>中外连接 OUTER JOIN 的右表。
- <递归成员>中列的数据类型必须与定位点成员中相应列的数据类型兼容。
举例说明
DROP TABLE MYEMPLOYEES;
CREATE TABLE MYEMPLOYEES(
EMPLOYEEID SMALLINT,
FIRST_NAME VARCHAR2 (30) NOT NULL,
LAST_NAME VARCHAR2 (40) NOT NULL,
TITLE VARCHAR2 (50) NOT NULL,
DEPTID SMALLINT NOT NULL,
MANAGERID INT NULL);
INSERT INTO MYEMPLOYEES VALUES (1, 'KEN', 'SANCHEZ', 'CHIEF EXECUTIVE OFFICER', 16, NULL);
INSERT INTO MYEMPLOYEES VALUES (273, 'BRIAN', 'WELCKER', 'VICE PRESIDENT OF SALES', 3, 1);
INSERT INTO MYEMPLOYEES VALUES (274, 'STEPHEN','JIANG', 'NORTH AMERICAN SALES MANAGER',3, 273);
INSERT INTO MYEMPLOYEES VALUES (275, 'MICHAEL', 'BLYTHE', 'SALES REPRESENTATIVE', 3, 274);
INSERT INTO MYEMPLOYEES VALUES (276, 'LINDA', 'MITCHELL', 'SALES REPRESENTATIVE', 3, 274);
INSERT INTO MYEMPLOYEES VALUES (285, 'SYED', 'ABBAS', 'PACIFIC SALES MANAGER', 3, 273);
INSERT INTO MYEMPLOYEES VALUES (286, 'LYNN', 'TSOFLIAS', 'SALES REPRESENTATIVE', 3, 285);
INSERT INTO MYEMPLOYEES VALUES (16, 'DAVID', 'BRADLEY', 'MARKETING MANAGER', 4, 273);
INSERT INTO MYEMPLOYEES VALUES (23, 'MARY', 'GIBSON', 'MARKETING SPECIALIST', 4, 16);
commit;
上下级关系如下图所示:
WITH DIRECTREPORTS(MANAGERID, EMPLOYEEID, TITLE, DEPTID) AS
(SELECT MANAGERID, EMPLOYEEID, TITLE, DEPTID
FROM MYEMPLOYEES
WHERE MANAGERID IS NULL //定位点成员
UNION ALL
SELECT E.MANAGERID, E.EMPLOYEEID, E.TITLE, E.DEPTID
FROM MYEMPLOYEES E
INNER JOIN DIRECTREPORTS D
ON E.MANAGERID = D.EMPLOYEEID //递归成员
)
SELECT MANAGERID, EMPLOYEEID, TITLE FROM DIRECTREPORTS;
递归调用执行步骤:
(1)产生定位点成员
MANAGERID EMPLOYEEID TITLE
--------- ---------- ------------------
NULL 1 CHIEF EXECUTIVE OFFICER
(2)第一次迭代,返回一个成员
MANAGERID EMPLOYEEID TITLE
--------- ---------- ---------------------------
1 273 VICE PRESIDENT OF SALES
(3)第二次迭代,返回三个成员
MANAGERIDEMPLOYEEID TITLE
--- ----------------------------- ------
273 16 MARKETING MANAGER
273 274 NORTH AMERICAN SALES MANAGER
273 285 PACIFIC SALES MANAGER
(4)第三次迭代,返回四个成员
MANAGERID EMPLOYEEID TITLE
--------- ---------- -----------------------------
16 23 MARKETING SPECIALIST
274 275 SALES REPRESENTATIVE
274 276 SALES REPRESENTATIVE
285 286 SALES REPRESENTATIVE
(5)第四次迭代,返回空集。递归结束。
(6)正在运行的查询返回的最终结果集是定位点成员和递归成员生成的所有结果集的并集(UNION
ALL)。
MANAGERID EMPLOYEEID TITLE
--------- ---------- -----------------------------
NULL 1 CHIEF EXECUTIVE OFFICER
1 273 VICE PRESIDENT OF SALES
273 16 MARKETING MANAGER
273 274 NORTH AMERICAN SALES MANAGER
273 285 PACIFIC SALES MANAGER
16 23 MARKETING SPECIALIST
274 275 SALES REPRESENTATIVE
274 276 SALES REPRESENTATIVE
285 286 SALES REPRESENTATIVE
4.5 集合查询
集合查询是指使用了集合运算符的查询。集合运算符包括 UNION、EXCEPT、MINUS 和 INTERSECT。
语法格式
<select_clause> <集合运算符> [ALL | DISTINCT | UNIQUE] [CORRESPONDING [BY (<列名> {,<列名>})]] <select_clause>
<集合运算符>::=UNION| EXCEPT| MINUS| INTERSECT
<select_clause>和[CORRESPONDING [BY (<列名> {,<列名>})]]请参考<查询表达式>
使用说明
1. < 集合运算符 > UNION 运算符返回两个结果集的并集;EXCEPT 和 MINUS 运算符功能完全一样,返回两个集合的差集;INTERSECT 运算符返回两个集合的交集,INTERSECT 运算符会自动删除重复行,如果需要保留重复行,需要使用 INTERSECT ALL;
2. 两个查询块 <select_clause> 的查询列数目必须相同,数据类型必须兼容;
3. ALL|DISTINCT|UNIQUE。ALL 表示集合查询结果中保持所有重复;DISTINCT 表示删除所有重复。DISTINCT 与 UNIQUE 等价。缺省为 DISTINCT;
4. EXCEPT/MINUS/INTERSECT 集合运算中,查询列不能含有 BLOB、CLOB 或 IMAGE、TEXT 等大字段类型。
举例说明
例 1 查询所有图书的出版商,查询所有图书供应商的名称,将两者连接,并去掉重复行。
SELECT PUBLISHER FROM PRODUCTION.PRODUCT
UNION
SELECT NAME FROM PURCHASING.VENDOR ORDER BY 1;
查询结果如下:
行号 PUBLISHER
---------- ------------------
1
2 21世纪出版社
3 北京十月文艺出版社
4 长江文艺出版社
5 广州出版社
6 机械工业出版社
7 清华大学出版社
8 人民文学出版社
9 人民邮电出版社
10 上海出版社
11 上海画报出版社
12 外语教学与研究出版社
13 文学出版社
14 中华书局
例 2 UNION ALL。
SELECT PUBLISHER FROM PRODUCTION.PRODUCT
UNION ALL
SELECT NAME FROM PURCHASING.VENDOR ORDER BY 1;
查询结果如下:
行号 PUBLISHER
---------- ------------------
1
2 21世纪出版社
3 21世纪出版社
4 北京十月文艺出版社
5 长江文艺出版社
6 广州出版社
7 广州出版社
8 机械工业出版社
9 机械工业出版社
10 清华大学出版社
11 清华大学出版社
12 人民文学出版社
13 人民邮电出版社
14 上海出版社
15 上海出版社
16 上海画报出版社
17 外语教学与研究出版社
18 外语教学与研究出版社
19 文学出版社
20 中华书局
21 中华书局
22 中华书局
例 3 查询所有图书的出版商,查询所有图书供应商的名称,返回两者的差集,并去掉重复行。
SELECT PUBLISHER FROM PRODUCTION.PRODUCT
EXCEPT
SELECT NAME FROM PURCHASING.VENDOR ORDER BY 1;
查询结果如下:
行号 PUBLISHER
---------- ---------------
1
2 人民文学出版社
例 4 查询所有图书的出版商,查询所有图书供应商的名称,返回两者的交集,并去掉重复行。
SELECT PUBLISHER FROM PRODUCTION.PRODUCT
INTERSECT
SELECT NAME FROM PURCHASING.VENDOR ORDER BY 1;
查询结果如下:
行号 PUBLISHER
---------- --------------------
1 21世纪出版社
2 广州出版社
3 机械工业出版社
4 清华大学出版社
5 上海出版社
6 外语教学与研究出版社
7 中华书局
4.6 GROUP BY 和 HAVING 子句
GROUP BY 子句主要用法是分类汇总。GROUP BY 子句一般与集函数一起使用,常见集函数包括 COUNT、SUM、AVG、MAX 和 MIN 等。
GROUP BY 子句将由 WHERE 子句返回的临时结果按一个或多个分组项进行分组,分组项相同的为一组。分组结果是行的集合。
HAVING 子句用于为组设置检索条件。
4.6.1 GROUP BY 子句的使用
GROUP BY 子句是 SELECT 语句的可选项部分。它定义了分组表。
语法如下:
<GROUP BY 子句> ::= GROUP BY <group_by项>
<group_by项>::=<group_by子项 > {,<group_by子项>}
<group_by子项>::=<group_by分组项> | <ROLLUP项> | <CUBE项> | <GROUPING SETS项>
<group_by分组项>=<分组项集>|
<分组项集>{,<分组项集>}
<分组项集>::=<分组项>|(<分组项>{,<分组项>})| ()
<分组项>::=<列说明> | <无符号整数>
<ROLLUP项>::=ROLLUP (<rollup分组项>)
<rollup分组项>::= <列说明> | <无符号整数>
<CUBE项>::=CUBE (<cube分组项>)
<cube分组项>::= <列说明名> | <无符号整数>
<GROUPING SETS项>::=GROUPING SETS(<group_by分组项>)
参数
1.< 分组项集 > 用于指定分组方式。分组项集可以是单个分组项、多个分组项的集合或(),()表示将当前所有数据作为一个整体。当分组项集用于 GROUP BY 时,多个分组项集涉及的分组列会被合并去重,并按照出现顺序确定最终分组列进行分组。当分组项集用于 GROUPING SETS 时,将按照每个分组项集独立进行分组,最后把每个分组结果进行 UNION ALL 输出最终结果,这种情况下()不能单独使用,必须和其它分组项集组合使用。
2.< 分组项 > 用于指定分组列。分组列可以是 < 列说明 >、< 无符号整数 >。
3.< 列说明 > 用于指定分组列。分组列可以是任何在查询清单中的列名、可以是列计算的表达式、可以是子查询、也可以是 NULL。
4.< 无符号整数 > 用于指定分组键的序号,对应 SELECT 查询结果中列的序号。仅在兼容模式下(COMPATIBLE_MODE=4/6/7)有实际作用。当用 < 无符号整数 > 代替列名时,< 无符号整数 > 不应大于 SELECT 后查询结果列的个数。例如,在“SELECT MAX(C1),C2 FROM T GROUP BY 2;”中 GROUP BY 2 表示按照查询列中的第二列进行分组;但是如果在该例子中使用 GROUP BY 3,则会因查询结果列只有 2 列,无法进行分组,系统将报错。
当存在分组项时,若查询项包含列,则只能是分组项中的列,或者是作用于当前分组的集函数。当 GROUP_OPT_FLAG 参数取值包含 1 或 COMPATIBLE_MODE=4 时,也允许查询项为非分组项的列,此时该非分组列返回的是集函数 FIRST_VALUE(非分组列)的值。
例 1 统计每个部门的员工数。
SELECT DEPARTMENTID,COUNT(*) FROM RESOURCES.EMPLOYEE_DEPARTMENT GROUP BY DEPARTMENTID;
查询结果如下:
DEPARTMENTID COUNT(*)
------------ --------------------
2 3
1 2
3 1
4 1
系统执行此语句时,首先将 EMPLOYEE_DEPARTMENT 表按 DEPARTMENTID 列进行分组,相同的 DEPARTMENTID 为一组,然后对每一组使用集函数 COUNT(*),统计该组内的记录个数,如此继续,直到处理完最后一组,返回查询结果。
如果存在 WHERE 子句,系统先根据 WHERE 条件进行过滤,然后对满足条件的记录进行分组。
此外,GROUP BY 不会对结果集排序。如果需要排序,可以使用 ORDER BY 子句。
例 2 求小说类别包含的子类别所对应的产品数量,并按子类别编号的升序排列。
SELECT A1.PRODUCT_SUBCATEGORYID AS 子分类编号,A3.NAME AS 子分类名,count(*)AS
数量
FROM PRODUCTION.PRODUCT A1,
PRODUCTION.PRODUCT_CATEGORY A2,
PRODUCTION.PRODUCT_SUBCATEGORY A3
WHERE A1.PRODUCT_SUBCATEGORYID=A3.PRODUCT_SUBCATEGORYID
AND A2.PRODUCT_CATEGORYID=A3.PRODUCT_CATEGORYID
AND A2.NAME='小说'
GROUP BY A1.PRODUCT_SUBCATEGORYID,A3.NAME
ORDER BY A1.PRODUCT_SUBCATEGORYID;
查询结果如下:
子分类编号 子分类名 数量
----------- -------- --------------------
1 世界名著 1
2 武侠 1
4 四大名著 2
使用 GROUP BY 要注意以下问题:
- 分组列不能为集函数表达式或者在 SELECT 子句中定义的别名;
- 当分组列值包含空值时,则空值作为一个独立组;
- 当分组列包含多个列名时,则按照 GROUP BY 子句中列出现的顺序进行分组;
- GROUP BY 子句中至多可包含 512 个分组项;
- ROLLUP\CUBE\GROUPING SETS 组合项不能超过 8 个,且组合项产生的分支数不能超过 512 个,否则将触发报错。
4.6.2 ROLLUP 的使用
ROLLUP 主要用于统计分析,对分组列以及分组列的部分子集进行分组,输出用户需要的结果。
语法如下:
GROUP BY ROLLUP (<rollup分组项>{,<rollup分组项>} )
<rollup分组项>::= <列名> | <值表达式>
假如 ROLLUP 分组列为(A, B, C),首先对(A,B,C)进行分组,然后对(A,B)进行分组,接着对(A)进行分组,最后对全表进行查询,无分组列,其中查询项中出现在 ROLLUP 中的列设为 NULL。查询结果是把每种分组的结果集进行 UNION ALL 合并输出。如果分组列为 n 列,则共有 n+1 种组合方式。
例 按小区住址和所属行政区域统计员工居住分布情况。
SELECT CITY , ADDRESS1, COUNT(*) as NUMS FROM PERSON.ADDRESS GROUP BY ROLLUP(CITY, ADDRESS1);
查询结果如下:
CITY ADDRESS1 NUMS
------------ ----------------------------- --------------------
武汉市洪山区 洪山区369号金地太阳城56-1-202 1
武汉市洪山区 洪山区369号金地太阳城57-2-302 1
武汉市青山区 青山区青翠苑1号 1
武汉市武昌区 武昌区武船新村115号 1
武汉市汉阳区 汉阳大道熊家湾15号 1
武汉市洪山区 洪山区保利花园50-1-304 1
武汉市洪山区 洪山区保利花园51-1-702 1
武汉市洪山区 洪山区关山春晓51-1-702 1
武汉市江汉区 江汉区发展大道561号 1
武汉市江汉区 江汉区发展大道555号 1
武汉市武昌区 武昌区武船新村1号 1
武汉市江汉区 江汉区发展大道423号 1
武汉市洪山区 洪山区关山春晓55-1-202 1
武汉市洪山区 洪山区关山春晓10-1-202 1
武汉市洪山区 洪山区关山春晓11-1-202 1
武汉市洪山区 洪山区光谷软件园C1_501 1
武汉市洪山区 NULL 9
武汉市青山区 NULL 1
武汉市武昌区 NULL 2
武汉市汉阳区 NULL 1
武汉市江汉区 NULL 3
NULL NULL 16
上例中的查询等价于:
SELECT CITY , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY
CITY, ADDRESS1
UNION ALL
SELECT CITY , NULL, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY CITY
UNION ALL
SELECT NULL , NULL, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY 0;
使用 ROLLUP 要注意以下事项:
- ROLLUP 项不能包含集函数;
- 不支持包含 WITH FUNCTION 的相关查询;
- 不支持包含存在 ROLLUP 的嵌套相关子查询;
- 不支持数组查询;
- ROLLUP 项最多支持 511 个;
- ROLLUP 项不能引用外层列。
4.6.3 CUBE 的使用
CUBE 的使用场景与 ROLLUP 类似,常用于统计分析,对分组列以及分区列的所有子集进行分组,输出所有分组结果。
语法如下:
GROUP BY CUBE (<cube分组项>{,<cube分组项>})
<cube分组项>::= <列名> | <值表达式>
假如,CUBE 分组列为(A, B, C),则首先对(A,B,C)进行分组,然后依次对(B,C)、(A,C)、(C)、(A,B)、(B)、(A)六种情况进行分组,最后对全表进行查询,无分组列,其中查询项存在于 CUBE 列表的列设置为 NULL。输出为每种分组的结果集进行 UNION ALL。CUBE 分组共有 2 的 n 次方种组合方式。CUBE 最多支持 9 列。
例 按小区住址、所属行政区域统计员工居住分布情况。
SELECT CITY , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY
CUBE(CITY, ADDRESS1);
查询结果如下:
CITY ADDRESS1 NUMS
------------ ----------------------------- --------------------
武汉市洪山区 洪山区369号金地太阳城56-1-202 1
武汉市洪山区 洪山区369号金地太阳城57-2-302 1
武汉市青山区 青山区青翠苑1号 1
武汉市武昌区 武昌区武船新村115号 1
武汉市汉阳区 汉阳大道熊家湾15号 1
武汉市洪山区 洪山区保利花园50-1-304 1
武汉市洪山区 洪山区保利花园51-1-702 1
武汉市洪山区 洪山区关山春晓51-1-702 1
武汉市江汉区 江汉区发展大道561号 1
武汉市江汉区 江汉区发展大道555号 1
武汉市武昌区 武昌区武船新村1号 1
武汉市江汉区 江汉区发展大道423号 1
武汉市洪山区 洪山区关山春晓55-1-202 1
武汉市洪山区 洪山区关山春晓10-1-202 1
武汉市洪山区 洪山区关山春晓11-1-202 1
武汉市洪山区 洪山区光谷软件园C1_501 1
NULL 洪山区369号金地太阳城56-1-202 1
NULL 洪山区369号金地太阳城57-2-302 1
NULL 青山区青翠苑1号 1
NULL 武昌区武船新村115号 1
NULL 汉阳大道熊家湾15号 1
NULL 洪山区保利花园50-1-304 1
NULL 洪山区保利花园51-1-702 1
NULL 洪山区关山春晓51-1-702 1
NULL 江汉区发展大道561号 1
NULL 江汉区发展大道555号 1
NULL 武昌区武船新村1号 1
NULL 江汉区发展大道423号 1
NULL 洪山区关山春晓55-1-202 1
NULL 洪山区关山春晓10-1-202 1
NULL 洪山区关山春晓11-1-202 1
NULL 洪山区光谷软件园C1_501 1
武汉市洪山区 NULL 9
武汉市青山区 NULL 1
武汉市武昌区 NULL 2
武汉市汉阳区 NULL 1
武汉市江汉区 NULL 3
NULL NULL 16
上例中的查询等价于:
SELECT CITY , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY
CITY, ADDRESS1
UNION ALL
SELECT CITY , NULL, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY CITY
UNION ALL
SELECT NULL , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY
ADDRESS1
UNION ALL
SELECT NULL , NULL, COUNT(*) AS NUMS FROM PERSON.ADDRESS;
使用 CUBE 要注意以下事项:
- CUBE 项不能包含集函数;
- 不支持包含 WITH FUNCTION 的相关查询;
- 不支持包含存在 CUBE 的嵌套相关子查询;
- 不支持数组查询;
- CUBE 项最多支持 9 个;
- CUBE 项不能引用外层列。
4.6.4 GROUPING 的使用
GROUPING 可以视为集函数,一般用于含 GROUP BY 的语句中,标识某子结果集是否是按指定分组项分组的结果,如果是,GROUPING 值为 0;否则为 1。
语法如下:
<GROUPING项>::=GROUPING (<grouping分组项>)
<grouping分组项>::= <列名> | <值表达式>
使用约束说明:
- GROUPING 中只能包含一列;
- GROUPING 只能在 GROUP BY 查询中使用;
- GROUPING 不能在 WHERE 或连接条件中使用;
- GROUPING 支持表达式运算。例如 GROUPING(c1) + GROUPING(c2)。
例 按小区住址和所属行政区域统计员工居住分布情况。
SELECT GROUPING(CITY) AS G_CITY,GROUPING(ADDRESS1) AS G_ADD, CITY , ADDRESS1,
COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY ROLLUP(CITY, ADDRESS1);
查询结果如下:
G_CITY G_ADD CITY ADDRESS1 NUMS
-------- ------- ---------- ------------------------------- -----------
0 0 武汉市洪山区 洪山区369号金地太阳城56-1-202 1
0 0 武汉市洪山区 洪山区369号金地太阳城57-2-302 1
0 0 武汉市青山区 青山区青翠苑1号 1
0 0 武汉市武昌区 武昌区武船新村115号 1
0 0 武汉市汉阳区 汉阳大道熊家湾15号 1
0 0 武汉市洪山区 洪山区保利花园50-1-304 1
0 0 武汉市洪山区 洪山区保利花园51-1-702 1
0 0 武汉市洪山区 洪山区关山春晓51-1-702 1
0 0 武汉市江汉区 江汉区发展大道561号 1
0 0 武汉市江汉区 江汉区发展大道555号 1
0 0 武汉市武昌区 武昌区武船新村1号 1
0 0 武汉市江汉区 江汉区发展大道423号 1
0 0 武汉市洪山区 洪山区关山春晓55-1-202 1
0 0 武汉市洪山区 洪山区关山春晓10-1-202 1
0 0 武汉市洪山区 洪山区关山春晓11-1-202 1
0 0 武汉市洪山区 洪山区光谷软件园C1_501 1
0 1 武汉市洪山区 NULL 9
0 1 武汉市青山区 NULL 1
0 1 武汉市武昌区 NULL 2
0 1 武汉市汉阳区 NULL 1
0 1 武汉市江汉区 NULL 3
1 1 NULL NULL 16
4.6.5 GROUPING SETS 的使用
GROUPING SETS 是对 GROUP BY 的扩展,可以指定不同的列进行分组,每个分组列集作为一个分组单元。使用 GROUPING SETS,用户可以灵活的指定分组方式,避免 ROLLUP/CUBE 过多的分组情况,满足实际应用需求。GROUPING SETS 的分组过程为依次按照每一个分组单元进行分组,最后把每个分组结果进行 UNION ALL 输出最终结果。如果查询项不属于分组列,则用 NULL 代替。
语法如下:
GROUP BY GROUPING SETS(<group_by分组项>)
<group_by分组项>::=请参考GROUP BY子句
例 按照邮编、住址和行政区域统计员工住址分布情况。
SELECT CITY , ADDRESS1, POSTALCODE, COUNT(*) AS NUMS FROM PERSON.ADDRESS
GROUP BY GROUPING SETS((CITY, ADDRESS1), POSTALCODE);
查询结果如下:
CITY ADDRESS1 POSTALCODE NUMS
------------ -------------------------- ---------- -------------
武汉市洪山区 洪山区369号金地太阳城56-1-202 NULL 1
武汉市洪山区 洪山区369号金地太阳城57-2-302 NULL 1
武汉市青山区 青山区青翠苑1号 NULL 1
武汉市武昌区 武昌区武船新村115号 NULL 1
武汉市汉阳区 汉阳大道熊家湾15号 NULL 1
武汉市洪山区 洪山区保利花园50-1-304 NULL 1
武汉市洪山区 洪山区保利花园51-1-702 NULL 1
武汉市洪山区 洪山区关山春晓51-1-702 NULL 1
武汉市江汉区 江汉区发展大道561号 NULL 1
武汉市江汉区 江汉区发展大道555号 NULL 1
武汉市武昌区 武昌区武船新村1号 NULL 1
武汉市江汉区 江汉区发展大道423号 NULL 1
武汉市洪山区 洪山区关山春晓55-1-202 NULL 1
武汉市洪山区 洪山区关山春晓10-1-202 NULL 1
武汉市洪山区 洪山区关山春晓11-1-202 NULL 1
武汉市洪山区 洪山区光谷软件园C1_501 NULL 1
NULL NULL 430073 9
NULL NULL 430080 1
NULL NULL 430063 2
NULL NULL 430050 1
NULL NULL 430023 3
上例中的查询等价于:
SELECT CITY , ADDRESS1, NULL , COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP
BY CITY, ADDRESS1
UNION ALL
SELECT NULL , NULL, POSTALCODE ,COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY POSTALCODE;
使用 GROUPING SETS 要注意以下事项:
- GROUPING SETS 项不能包含集函数;
- 不支持包含 WITH FUNCTION 的相关查询;
- 不支持包含存在 GROUPING SETS 的嵌套相关子查询;
- GROUPING SETS 项最多支持 512 个;
- GROUPING SETS 项不能引用外层列。
4.6.6 GROUPING_ID 的使用
GROUPING_ID 表示参数列是否为分组列。返回值的每一个二进制位表示对应的参数列是否为分组列,如果是分组列,该位值为 0;否则为 1。
使用 GROUPING_ID 可以按照列的分组情况过滤结果集。
语法如下:
<GROUPING_ID项>::=GROUPING_ID (<grouping_id分组项>{,<grouping_id分组项>)
<grouping_id分组项>::= <列名> | <值表达式>
使用约束说明:
- GROUPING_ID 中至少包含一列,最多包含 63 列;
- GROUPING_ID 只能与分组项一起使用;
- GROUPING_ID 支持表达式运算;
- GROUPING_ID 作为分组函数,不能出现在 where 或连接条件中。
例 按小区住址和所属行政区域统计员工居住分布情况。
SELECT GROUPING(CITY) AS G_CITY,GROUPING(ADDRESS1) AS G_ADD, GROUPING_ID(CITY, ADDRESS1) AS G_CA,CITY , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY ROLLUP(CITY, ADDRESS1);
查询结果如下:
G_CITY G_ADD G_CA CITY ADDRESS1 NUMS
------ ------ ------ --------- --------------------------- ------
0 0 0 武汉市洪山区 洪山区369号金地太阳城56-1-202 1
0 0 0 武汉市洪山区 洪山区369号金地太阳城57-2-302 1
0 0 0 武汉市青山区 青山区青翠苑1号 1
0 0 0 武汉市武昌区 武昌区武船新村115号 1
0 0 0 武汉市汉阳区 汉阳大道熊家湾15号 1
0 0 0 武汉市洪山区 洪山区保利花园50-1-304 1
0 0 0 武汉市洪山区 洪山区保利花园51-1-702 1
0 0 0 武汉市洪山区 洪山区关山春晓51-1-702 1
0 0 0 武汉市江汉区 江汉区发展大道561号 1
0 0 0 武汉市江汉区 江汉区发展大道555号 1
0 0 0 武汉市武昌区 武昌区武船新村1号 1
0 0 0 武汉市江汉区 江汉区发展大道423号 1
0 0 0 武汉市洪山区 洪山区关山春晓55-1-202 1
0 0 0 武汉市洪山区 洪山区关山春晓10-1-202 1
0 0 0 武汉市洪山区 洪山区关山春晓11-1-202 1
0 0 0 武汉市洪山区 洪山区光谷软件园C1_501 1
0 1 1 武汉市洪山区 NULL 9
0 1 1 武汉市青山区 NULL 1
0 1 1 武汉市武昌区 NULL 2
0 1 1 武汉市汉阳区 NULL 1
0 1 1 武汉市江汉区 NULL 3
1 1 3 NULL NULL 16
4.6.7 GROUP_ID 的使用
GROUP_ID 表示结果集来自于哪一个分组,用于区别相同分组的结果集。如果有 N 个相同分组,则 GROUP_ID 取值范围为 0~N-1。每组的初始值为 0。
当查询包含多个分组时,使用 GROUP_ID 可以方便的过滤相同分组的结果集。
语法如下:
<GROUP_ID项>::=GROUP_ID()
使用约束说明:
- GROUP_ID 不包含参数;
- GROUP_ID 只能与分组项一起使用;
- GROUP_ID 支持表达式运算;
- GROUP_ID 作为分组函数,不能出现在 WHERE 或连接条件中。
例 按小区住址和所属行政区域统计员工居住分布情况。
SELECT GROUPING(CITY) AS G_CITY,GROUPING(ADDRESS1) AS G_ADD, GROUP_ID() AS
GID,CITY , ADDRESS1, COUNT(*) AS NUMS FROM PERSON.ADDRESS GROUP BY ROLLUP(CITY, ADDRESS1), CITY;
查询结果如下:
G_CITY G_ADD GID CITY ADDRESS1 NUMS
------ ----- ---- --------- ----------------------------- -----
0 0 0 武汉市洪山区 洪山区369号金地太阳城56-1-202 1
0 0 0 武汉市洪山区 洪山区369号金地太阳城57-2-302 1
0 0 0 武汉市青山区 青山区青翠苑1号 1
0 0 0 武汉市武昌区 武昌区武船新村115号 1
0 0 0 武汉市汉阳区 汉阳大道熊家湾15号 1
0 0 0 武汉市洪山区 洪山区保利花园50-1-304 1
0 0 0 武汉市洪山区 洪山区保利花园51-1-702 1
0 0 0 武汉市洪山区 洪山区关山春晓51-1-702 1
0 0 0 武汉市江汉区 江汉区发展大道561号 1
0 0 0 武汉市江汉区 江汉区发展大道555号 1
0 0 0 武汉市武昌区 武昌区武船新村1号 1
0 0 0 武汉市江汉区 江汉区发展大道423号 1
0 0 0 武汉市洪山区 洪山区关山春晓55-1-202 1
0 0 0 武汉市洪山区 洪山区关山春晓10-1-202 1
0 0 0 武汉市洪山区 洪山区关山春晓11-1-202 1
0 0 0 武汉市洪山区 洪山区光谷软件园C1_501 1
0 1 1 武汉市洪山区 NULL 9
0 1 1 武汉市青山区 NULL 1
0 1 1 武汉市武昌区 NULL 2
0 1 1 武汉市汉阳区 NULL 1
0 1 1 武汉市江汉区 NULL 3
0 1 0 武汉市洪山区 NULL 9
0 1 0 武汉市青山区 NULL 1
0 1 0 武汉市武昌区 NULL 2
0 1 0 武汉市汉阳区 NULL 1
0 1 0 武汉市江汉区 NULL 3
4.6.8 HAVING 子句的使用
HAVING 子句是 SELECT 语句的可选项部分,它也定义了一个分组表。
语法如下:
<HAVING 子句> ::= HAVING <搜索条件>
<搜索条件>::= <表达式>
HAVING 子句定义了一个分组表,其中只含有搜索条件为 TRUE 的那些组,且通常跟随一个 GROUP BY 子句。HAVING 子句与组的关系正如 WHERE 子句与表中行的关系。WHERE 子句用于选择表中满足条件的行,而 HAVING 子句用于选择满足条件的组。
例 统计出同一子类别的产品数量大于 1 的子类别名称,数量,并按数量从小到大的顺序排列。
SELECT A2.NAME AS 子分类名, COUNT (*)AS 数量
FROM PRODUCTION.PRODUCT A1,
PRODUCTION.PRODUCT_SUBCATEGORY A2
WHERE A1.PRODUCT_SUBCATEGORYID=A2.PRODUCT_SUBCATEGORYID
GROUP BY A2.NAME
HAVING COUNT(*)>1
ORDER BY 2;
查询结果如下:
子分类名 数量
-------- --------------------
四大名著 2
系统执行此语句时,首先将 PRODUCT 表和 PRODUCT_SUBCATEGORY 表中的各行按相同的 SUBCATEGORYID 作连接,再按子类别名的取值进行分组,相同的子类别名为一组,然后对每一组使用集函数 COUNT(*),统计该组内产品的数量,如此继续,直到最后一组。再选择产品数量大于 1 的组作为查询结果。
4.7 ORDER BY 子句
ORDER BY 子句可以选择性地出现在<查询表达式>之后,它规定了当行由查询返回时应具有的顺序。ORDER BY 子句的语法如下:
<ORDER BY 子句> ::= ORDER [SIBLINGS] BY <order_by_list>
<order_by_list>::= <order_by_item >{,<order_by_item>}
<order_by_item>::= <exp> [COLLATE <collation_name>] [ASC|DESC] [NULLS FIRST|LAST]
<exp>::=<列说明>|<无符号整数>|<值表达式>|<布尔表达式>
使用说明
-
ORDER BY 子句提供了要排序的项目清单和他们的排序顺序:递增顺序(ASC,默认)或是递减顺序(DESC)。它必须跟随在<查询表达式>之后,因为它是在查询计算得出的最终结果上进行操作的;
-
SIBLINGS 关键字必须与 CONNECT BY 一起配合使用,专门用于指定层次查询中相同层次数据返回的顺序。详见 4.13.5 层次查询层内排序;
-
*<*exp> 用于指定排序列。支持 < 列说明 >、< 无符号整数 >、< 值表达式 > 或 < 布尔表达式 > 四种指定方式;
-
COLLATE 关键字指定该排序项根据 collation_name 中指定的排序规则进行排序。目前 collation_name 仅支持指定为 Chinese_PRC_CS_AS_KS_WS,当指定为该规则时,该排序项按照中文拼音排序。COLLATE 关键字仅适用于 VARCHAR 类型的列;
-
< 列说明 > 用于指定排序列。排序列可以是任何在查询清单中的列名、可以是列计算的表达式(即使这一列不在选择清单中)、可以是子查询、也可以是 NULL。
当排序列包含多个列名时,系统则按列名从左到右排列的顺序,先按左边列将查询结果排序,当左边排序列值相等时,再按右边排序列排序……如此右推,逐个检查调整,最后得到排序结果。
当排序列为列计算表达式时,则按照该列进行排序。例如,当排序列为 3C1 时,系统则按照每一行的排序键值为 3C1 进行排序。当排序列为 ORDER BY C1=3 ASC 时,则将符合 C1=3 的列放在整个结果集的最后面,不符合 C1=3 的列只输出在结果集中但不排序。
当排序列为子查询时,则按照子查询的结果进行排序。例如,在 select * from T order by (SELECT C1 FROM T WHERE C2=10);中子查询 SELECT C1 FROM T WHERE C2=10 的结果为 5,那么系统按照每一行的排序键值均为 5 进行排序。
当排序列为 NULL 时,不进行排序。
对于 UNION 查询语句,排序键必须在第一个查询子句中出现;对于 GROUP BY 分组的排序,排序键可以使用集函数,但 GROUP BY 分组中必须包含查询列中所有列;
-
< 无符号整数 > 指定排序键的序号,对应 SELECT 后查询结果列的序号。当用 < 无符号整数 > 代替列名时,< 无符号整数 > 不应大于 SELECT 后查询结果列的个数。例如,在 select C1,C2 from T order by 2;中表示按照查询列中的第二列进行排序。但是如果例子中使用 ORDER BY 3,则因查询结果列只有 2 列,无法进行排序,系统将会报错。
如果排序列不是数值类型,则会直接被忽略。例如,在 select C1,C2 from T order by '2';中,order by '2'会被直接忽略掉;
-
< 值表达式 > 语法支持,实际不起作用。例如,值表达式(如:-1,3×6)作为排序列,将不影响最终结果表的行输出顺序。select * from T order by 3*6;和 select * from T;效果一样;
-
< 布尔表达式 > 如果指定了布尔表达式,则按照布尔表达式的结果 1 或 0 进行排序。例如:在 select * from T order by 1=2;语句中,因为布尔表达式 1=2 结果为 0,那么系统按照每一行的排序键值均为 0 进行排序;
-
当排序列值包含 NULL 时,根据指定的“NULLS FIRST|LAST”决定包含空值的行是排在最前还是最后,缺省为 NULLS FIRST;
-
由于 ORDER BY 只能在最终结果上操作,不能将其放在查询中;
-
如果 ORDER BY 后面使用集函数,则必须使用 GROUP BY 分组,且 GROUP BY 分组中必须包含查询列中所有列;
-
ORDER BY 子句中至多可包含 255 个排序列。
例 1 将 RESOURCES.DEPARTMENT 表中的资产总值按从大到小的顺序排列。
SELECT * FROM RESOURCES.DEPARTMENT ORDER BY DEPARTMENTID DESC;
等价于:
SELECT * FROM RESOURCES.DEPARTMENT ORDER BY 1 DESC;
查询结果如下:
DEPARTMENTID NAME
------------ --------
5 广告部
4 行政部门
3 人力资源
2 销售部门
1 采购部门
例 2 因为查询列只有两列,而 ORDER BY 指定了第 3 列为排序列,则报错。
SELECT DEPARTMENTID,NAME FROM RESOURCES.DEPARTMENT ORDER BY 3;
4.8 FOR UPDATE 子句
FOR UPDATE 子句可以选择性地出现在<查询表达式>之后。普通 SELECT 查询不会修改行数据物理记录上的 TID 事务号,FOR UPDATE 会修改行数据物理记录上的 TID 事务号并对该 TID 上锁,以保证该更新操作的待更新数据不被其他事务修改。
语法格式
<FOR UPDATE 子句> ::= FOR READ ONLY|
<FOR UPDATE 选项>
<FOR UPDATE 选项> ::= FOR UPDATE [OF <选择列表>] [<面对上锁的处理方式>]
<面对上锁的处理方式>::= NOWAIT |
WAIT N |
[N] SKIP LOCKED
<选择列表>::=<选择列> {,<选择列>}
<选择列>::=[[<模式名>.]<基表名>.] <列名>|
[[<模式名>.]<视图名>.] <列名>
参数
- FOR READ ONLY 表示查询不可更新;
- OF <选择列表>指定待更新表的列。指定某张表的列,即为锁定某张表。游标更新时,仅能更新指定的列;
- < 面对上锁的处理方式 > 用于指定试图上锁的行数据 TID 已经被其他事务上锁后,当前事务的处理方式:
- NOWAIT 表示不等待,直接报错返回;
- WAIT N 表示等待一段时间,其中的 N 值由用户指定,单位为秒。等待成功继续上锁,失败则报错返回。WAIT 的指定值必须大于 0,如果设置 0 自动转成 NOWAIT 方式;
- [N] SKIP LOCKED 表示上锁时跳过已经被其他事务锁住的行,不返回这些行给客户端。N 是正整数。N>0 表示当取得了 N 条数据后,便不再取数据了,直接返回 N 条结果(DMDPC 环境下实际封锁的行数可能会大于 N);N=0 表示返回除了锁定行之外的所有行;
- 如果 FOR UPDATE 不设置以上三种子句,则会一直等待锁被其他事务释放;
- INI 参数 LOCK_TID_MODE 用来标记 SELECT FOR UPDATE 封锁方式。0 表示结果集小于 100 行时,直接封锁 TID,超过 100 行升级为表锁。1 表示不升级表锁,一律使用 TID 锁。默认为 1。
例 查询 RESOURCES.DEPARTMENT 表中的资产。
SELECT * FROM RESOURCES.DEPARTMENT FOR UPDATE;
//只要FOR UPDATE语句不提交,其他会话就不能修改此结果集。
查询结果如下:
DEPARTMENTID NAME
------------ --------
1 采购部门
2 销售部门
3 人力资源
4 行政部门
5 广告部
需要说明的是:
-
SELECT FOR UPDATE 不支持的情况:
- 带 GROUP BY 子句的查询,如 SELECT C1, COUNT(C2) FROM TEST GROUP BY C1 FOR UPDATE;
- 带集函数的查询,如 SELECT MAX(C1)FROM TEST FOR UPDATE;
- 带 DISTINCT 的查询,如 SELECT DISTINCT C1 FROM TEST FOR UPDATE;
- 对以下表类型的查询:外部表、物化视图、系统表和 HUGE 表;
- WITH 子句,如 WITH TEST(C1) AS (SELECT C1 FROM T FOR UPDATE )SELECT * FROM TEST;
- 带层次查询子句的查询;
- 带 PIVOT 子句或 UNPIVOT 子句的查询。
-
涉及 DBLINK 的 SELECT FOR UPDATE 查询支持外部链接的单表、多表查询,不支持外部链接表与模式内的表的连接查询;
-
如果结果集中包含 LOB 对象,会再封锁 LOB 对象;
-
支持多表连接的情况,会封锁涉及到的所有表的行数据;
-
多表连接的时候,如果用 OF <选择列表>指定具体列,只会检测和封锁对应的表。例如:SELECT C1 FROM TEST, TESTB FOR UPDATE OF TEST.C1 即使 TESTB 表类型不支持 FOR UPDATE,上述语句还是可以成功;
-
DM 数据守护环境中,备库执行 SELECT FOR UPDATE 查询时,会直接忽略其中的 FOR UPDATE 子句。
4.9 TOP 子句
在 DM 中,可以使用 TOP 子句来筛选结果。语法如下:
<TOP子句>::=TOP <n>
| <n1>,<n2>
| <n> PERCENT
| <n> WITH TIES
| <n> PERCENT WITH TIES
<n>::=整数(>=0)
参数
- TOP <n> 选择结果的前 n 条记录;
- TOP <n1>,<n2> 选择第 n1 条记录之后的 n2 条记录;
- TOP <n> PERCENT 表示选择结果的前 n% 条记录,当记录总数*n% 的取值不是整数时,进行向上取整;
- TOP <n> PERCENT WITH TIES 表示选择结果的前 n% 条记录,同时指定结果集可以返回额外的行。额外的行是指与最后一行以相同的排序键排序的所有行。WITH TIES 必须与 ORDER BY 子句同时出现,如果没有 ORDER BY 子句,则忽略 WITH TIES。
例 1 查询现价最贵的两种产品的编号和名称。
SELECT TOP 2 PRODUCTID,NAME FROM PRODUCTION.PRODUCT ORDER BY NOWPRICE DESC;
查询结果如下:
PRODUCTID NAME
----------- -------------------
10 噼里啪啦丛书(全7册)
6 长征
例 2 查询现价第二贵的产品的编号和名称。
SELECT TOP 1,1 PRODUCTID,NAME FROM PRODUCTION.PRODUCT ORDER BY NOWPRICE DESC;
查询结果如下:
PRODUCTID NAME
----------- ----
6 长征
例 3 查询最新出版日期的 70% 的产品编号、名称和出版日期。
SELECT TOP 70 PERCENT WITH TIES PRODUCTID,NAME,PUBLISHTIME FROM
PRODUCTION.PRODUCT ORDER BY PUBLISHTIME DESC;
查询结果如下:
PRODUCTID NAME PUBLISHTIME
----------- -------------------------------- -----------
7 数据结构(C语言版)(附光盘) 2007-03-01
5 鲁迅文集(小说、散文、杂文)全两册 2006-09-01
6 长征 2006-09-01
3 老人与海 2006-08-01
8 工作中无小事 2006-01-01
4 射雕英雄传(全四册) 2005-12-01
2 水浒传 2005-04-01
1 红楼梦 2005-04-01
4.10 LIMIT 限定条件
在 DM 中,可以使用限定条件对结果集做出筛选,支持 LIMIT 子句和 ROW_LIMIT 子句两种方式。
4.10.1 LIMIT 子句
LIMIT 子句按顺序选取结果集中某条记录开始的 N 条记录。语法如下
<LIMIT子句>::=<LIMIT子句1> | <LIMIT子句2>
<LIMIT子句1>::= LIMIT <记录数>
| <记录数>,<记录数>
| <记录数> OFFSET <偏移量>
<LIMIT子句2>::= OFFSET <偏移量> LIMIT <记录数>
<记录数>::=<整数>
<偏移量>::=<整数>
共支持四种方式:
- LIMIT N:选择前 N 条记录;
- LIMIT M,N:选择第 M 条记录之后的 N 条记录;
- LIMIT M OFFSET N:选择第 N 条记录之后的 M 条记录;
- OFFSET N LIMIT M:选择第 N 条记录之后的 M 条记录。
注意:
- 一个查询表达式中不能同时包含 LIMIT 和 TOP 子句;
- LIMIT 子句可用在 UPDATE 或 DELETE 操作之后,形式如“DELETE FROM T1 LIMIT 2;”。
例 1 查询前 2 条记录
SELECT PRODUCTID , NAME FROM PRODUCTION.PRODUCT LIMIT 2;
查询结果如下:
PRODUCTID NAME
----------- ------
1 红楼梦
2 水浒传
例 2 查询第 3,4 个登记的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT LIMIT 2 OFFSET 2;
查询结果如下:
PRODUCTID NAME
----------- ------------------
3 老人与海
4 射雕英雄传(全四册)
例 3 查询前第 5,6,7 个登记的姓名。
SELECT PERSONID,NAME FROM PERSON.PERSON LIMIT 4,3;
查询结果如下:
PERSONID NAME
----------- ----
5 孙丽
6 黄非
7 王菲
4.10.2 ROW_LIMIT 子句
ROW_LIMIT 子句用于指定查询结果中偏移的行数,或从指定偏移开始返回的行数或总行数的百分比,以便更为灵活地获取查询结果。语法如下:
<ROW_LIMIT子句>::= [OFFSET <offset> ROW[S] ] [<FETCH说明>]
<FETCH说明>::= FETCH <FIRST | NEXT> [<大小> | <大小> PERCENT] ROW[S] <ONLY | WITH TIES>
参数
- OFFSET <offset> ROW[S] 指定偏移的行数,<offset> 必须为数字。offset 为负数时视为 0;为 NULL 或大于等于所返回的行数时,返回 0 行;为小数时,小数部分四舍五入。ROW 也可写为 ROWS;
- <FIRST | NEXT> 指定是否从指定偏移位置开始获取结果。FIRST 表示从指定偏移位置开始获取结果,NEXT 表示从指定偏移的下一行开始获取结果。只做注释说明的作用,没有实际的限定作用;
- [< 大小 > | < 大小 > PERCENT] 指定返回行的行数或者百分比。其中 < 大小 > 只能为数字。PERCENT 指定为负数时,视为 0%;为 NULL 时返回 0 行;如果没有指定 PERCENT 而指定了 < 大小 >,返回为从偏移开始,< 大小 > 指定的行数;如果省略返回行数和 PERCENT,默认返回偏移位置的下一行数据;
- <ONLY | WITH TIES> 指定结果集是否返回额外的行。额外的行是指与最后一行以相同的排序键排序的所有行。ONLY 为只返回指定的行数。WITH TIES 必须与 ORDER BY 子句同时出现,如果没有 ORDER BY 子句,则忽略 WITH TIES。
使用说明
物化视图的查询定义中包含有 ROW_LIMIT 子句时,该物化视图不能增量刷新。
举例说明
例 1 查询价格最便宜的 50% 的商品
SELECT NAME, NOWPRICE FROM PRODUCTION.PRODUCT ORDER BY NOWPRICE FETCH FIRST 50 PERCENT ROWS ONLY;
查询结果如下:
NAME NOWPRICE
---------------- --------
老人与海 6.1
突破英文基础词汇 11.1
工作中无小事 11.4
水浒传 14.3
红楼梦 15.2
例 2 查询价格第 3 便宜开始的 3 条记录
SELECT NAME, NOWPRICE FROM PRODUCTION.PRODUCT ORDER BY NOWPRICE OFFSET 2 ROWS FETCH FIRST 3 ROWS ONLY;
查询结果如下:
NAME NOWPRICE
------------ --------
工作中无小事 11.4
水浒传 14.3
红楼梦 15.2
4.11 PIVOT 和 UNPIVOT 子句
在 DM 中,可以使用 PIVOT 子句或 UNPIVOT 子句,将一组数据从行转换为列,或者从列转换为行。
4.11.1 PIVOT 子句
PIVOT 子句将一组数据从行转换为列。语法如下:
<PIVOT子句> ::= PIVOT [XML] (<set_func_clause> FOR <pivot_for_clause> IN (<pivot_in_clause>))
<set_func_clause> ::= <集函数> [[AS] <别名>] {,<集函数> [[AS] <别名>]}
<pivot_for_clause> ::= <列名> |
(<列名> {,<列名>})
<pivot_in_clause> ::= <exp_clause> [[AS] <别名>] {,<exp_clause> [[AS] <别名>]} |
<select_clause> |
ANY
<exp_clause> ::= <表达式> |
(<表达式> {,<表达式>})
<select_clause> ::= 请参考第4章 数据查询语句
参数
-
XML 指定使用 XML 格式输出数据,指定 XML 时必须使用 <select_clause> 或 ANY;
-
<set_func_clause> 指定对表或视图中的字段使用集函数;
-
<pivot_for_clause> 指定表或视图的原始列名;
-
<pivot_in_clause> 对 <pivot_for_clause> 指定列中的数据进行筛选,指定的数据值或别名将作为转换后新列的列名。支持以下三种筛选方式:
- <exp_clause> 直接指定 <pivot_for_clause> 列中的数据值,< 表达式 > 即实际数据值,仅支持常量表达式;
- <select_clause> 使用子查询语句选取 <pivot_for_clause> 列中的数据值,仅在指定 XML 时生效;
- ANY 指定 <pivot_for_clause> 列中的所有数据值,仅在指定 XML 时生效。
使用说明
- 使用多个集函数时,必须为每个集函数指定别名;
- 不支持 COVAR_SAMP、COVAR_POP、COLLECT、CORR 和 REGR_XXX(除了 REGR_COUNT)集函数;
- <pivot_for_clause> 或 <exp_clause> 中,针对多个 < 列名 > 或 < 表达式 >,必须使用小括号括起来;针对单个 < 列名 > 或 < 表达式 >,使用或者不使用小括号均可;
- 当 <pivot_for_clause> 中指定了多个列时,列个数与 <exp_clause> 中的表达式个数应一致,且列与表达式一一对应,例如 <pivot_for_clause> 为(C1,C2),<exp_clause> 应当为(<C1 的数据值 >,<C2 的数据值 >);可以在 <pivot_in_clause> 中指定多个 <exp_clause> 来表示多组数据值;
- 指定的 < 集函数 > 个数与 <pivot_in_clause> 中表达式个数的乘积不能超过 2048;
- 指定 XML 时,结果集返回类型为 TEXT;
- PIVOT 子句中未涉及的所有查询项,都将作为分组项;
- 不支持 FOR UPDATE 子句。
举例说明
创建测试表 SALES_ORDER 并插入数据。
CREATE TABLE SALES_ORDER (
SALESORDERID INT, //订单编号
SALESMAN VARCHAR(10), //销售员姓名
PRODUCT_NAME VARCHAR(10), //产品名称
AMOUNT DEC(10,2) //订单金额
);
//插入数据
INSERT INTO SALES_ORDER VALUES(1,'李兰','苹果',860);
INSERT INTO SALES_ORDER VALUES(2,'李兰','苹果',820);
INSERT INTO SALES_ORDER VALUES(3,'李兰','橘子',1566);
INSERT INTO SALES_ORDER VALUES(4,'李兰','草莓',3200);
INSERT INTO SALES_ORDER VALUES(5,'李兰','草莓',2750);
INSERT INTO SALES_ORDER VALUES(6,'王勇','苹果',630);
INSERT INTO SALES_ORDER VALUES(7,'王勇','苹果',750);
INSERT INTO SALES_ORDER VALUES(8,'王勇','橘子',1200);
INSERT INTO SALES_ORDER VALUES(9,'王勇','草莓',2700);
INSERT INTO SALES_ORDER VALUES(10,'王勇','草莓',3280);
INSERT INTO SALES_ORDER VALUES(11,'孙晓萌','橘子',1350);
INSERT INTO SALES_ORDER VALUES(12,'孙晓萌','橘子',1180);
INSERT INTO SALES_ORDER VALUES(13,'孙晓萌','草莓',3300);
INSERT INTO SALES_ORDER VALUES(14,'孙晓萌','草莓',3170);
查询 SALES_ORDER 表中数据。
SELECT * FROM SALES_ORDER;
查询结果如下:
SALESORDERID SALESMAN PRODUCT_NAME AMOUNT
------------ -------- ------------ ---------
1 李兰 苹果 860
2 李兰 苹果 820
3 李兰 橘子 1566
4 李兰 草莓 3200
5 李兰 草莓 2750
6 王勇 苹果 630
7 王勇 苹果 750
8 王勇 橘子 1200
9 王勇 草莓 2700
10 王勇 草莓 3280
11 孙晓萌 橘子 1350
12 孙晓萌 橘子 1180
13 孙晓萌 草莓 3300
14 孙晓萌 草莓 3170
例 1 使用 PIVOT 子句,将 PRODUCT_NAME 列中的 3 种产品所对应的行数据转换为列进行展示。
SELECT * FROM SALES_ORDER
PIVOT (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN('苹果','橘子','草莓')
);
查询结果如下:
SALESORDERID SALESMAN '苹果' '橘子' '草莓'
------------ -------- -------- -------- --------
1 李兰 860 NULL NULL
2 李兰 820 NULL NULL
3 李兰 NULL 1566 NULL
4 李兰 NULL NULL 3200
5 李兰 NULL NULL 2750
6 王勇 630 NULL NULL
7 王勇 750 NULL NULL
8 王勇 NULL 1200 NULL
9 王勇 NULL NULL 2700
10 王勇 NULL NULL 3280
11 孙晓萌 NULL 1350 NULL
12 孙晓萌 NULL 1180 NULL
13 孙晓萌 NULL NULL 3300
14 孙晓萌 NULL NULL 3170
PIVOT 子句中未提及的所有查询项都将作为分组项,因此上述语句的分组项为 SALESORDERID 和 SALESMAN。
PIVOT 子句所在层级的 SELECT 语句的查询项应当未出现在 PIVOT 子句中,或为“*”,否则将报错。例如,执行以下语句,SELECT 语句的查询项在 PIVOT 子句中,将报错:
SELECT SALESMAN,PRODUCT_NAME,AMOUNT
FROM SALES_ORDER
PIVOT (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN('苹果','橘子','草莓')
);
第7 行附近出现错误[-2111]:无效的列名[PRODUCT_NAME].
又例如,执行以下语句,SELECT 语句的查询项未在 PIVOT 子句中,可以成功执行:
SELECT SALESORDERID,SALESMAN
FROM SALES_ORDER
PIVOT (
SUM(AMOUNT)
FOR (PRODUCT_NAME)
IN('苹果','橘子','草莓')
);
查询结果如下:
SALESORDERID SALESMAN
------------ --------
1 李兰
2 李兰
3 李兰
4 李兰
5 李兰
6 王勇
7 王勇
8 王勇
9 王勇
10 王勇
11 孙晓萌
12 孙晓萌
13 孙晓萌
14 孙晓萌
用户可以借助子查询来指定表或视图中的部分字段作为查询项。例如利用子查询选择 SALESMAN、PRODUCT_NAME 和 AMOUNT 作为查询项。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN('苹果','橘子','草莓')
);
查询结果如下:
SALESMAN '苹果' '橘子' '草莓'
--------- -------- -------- --------
李兰 1680 1566 5950
王勇 1380 1200 5980
孙晓萌 NULL 2530 6470
上述语句利用子查询选择 SALESMAN、PRODUCT_NAME 和 AMOUNT 作为查询项,其中的分组项为 SALESMAN,有利于统计各销售人员针对不同产品的销售总额。
例 2 可以在 IN 子句中为每个数据值指定别名,指定的别名将作为转换后各列的列名。例如可以通过指定别名,去除列名中的单引号。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN ('苹果' AS 苹果,'橘子' AS 橘子,'草莓' AS 草莓)
);
查询结果如下:
SALESMAN 苹果 橘子 草莓
--------- ------ ------ ------
李兰 1680 1566 5950
王勇 1380 1200 5980
孙晓萌 NULL 2530 6470
例 3 使用多个集函数,此时需要为每个集函数指定别名。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT) AS 订单总额,
COUNT(AMOUNT) AS 订单数量
FOR PRODUCT_NAME
IN('苹果' AS 苹果, '橘子' AS 橘子)
);
查询结果如下:
SALESMAN 苹果_订单总额 苹果_订单数量 橘子_订单总额 橘子_订单数量
--------- ------------------- -------------------- -------------------
李兰 1680 2 1566 1
王勇 1380 2 1200 1
孙晓萌 NULL 0 2530 2
例 4 FOR 子句中指定多列,此时需要在 IN 子句中同时指定多列的数据值。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT)
FOR (SALESMAN,PRODUCT_NAME)
IN(
('李兰','橘子') AS 李兰_橘子总额,
('王勇','橘子') AS 王勇_橘子总额,
('孙晓萌','橘子') AS 孙晓萌_橘子总额)
);
查询结果如下:
李兰_橘子总额 王勇_橘子总额 孙晓萌_橘子总额
------------------- --------- ---------
1566 1200 2530
例 5 指定 XML,使用 XML 格式输出数据,同时指定 ANY 关键字,表示选择 PRODUCT_NAME 列中的全部产品。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT XML (
SUM (AMOUNT)
FOR PRODUCT_NAME
IN (ANY)
);
查询结果如下:
SALESMAN PRODUCT_NAME_XML
------------ -----------------------------------
李兰
<PivotSet><item><column name = "PRODUCT_NAME">草莓</column><column name = "SUM(AMOUNT)">5950</column></item><item><column name = "PRODUCT_NAME">苹果</column><column name = "SUM(AMOUNT)">1680</column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">1566</column></item></PivotSet>
孙晓萌
<PivotSet><item><column name = "PRODUCT_NAME">草莓</column><column name = "SUM(AMOUNT)">6470</column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">2530</column></item></PivotSet>
王勇
<PivotSet><item><column name = "PRODUCT_NAME">草莓</column><column name = "SUM(AMOUNT)">5980</column></item><item><column name = "PRODUCT_NAME">苹果</column><column name = "SUM(AMOUNT)">1380</column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">1200</column></item></PivotSet>
例 6 指定 XML,使用 XML 格式输出数据,同时使用子查询语句选择 PRODUCT_NAME 列中的产品。
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT XML (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN(
SELECT PRODUCT_NAME
FROM SALES_ORDER
WHERE PRODUCT_NAME='苹果' OR PRODUCT_NAME='橘子')
);
查询结果如下:
SALESMAN PRODUCT_NAME_XML
------------ -----------------------------------
李兰
<PivotSet><item><column name = "PRODUCT_NAME">苹果</column><column name = "SUM(AMOUNT)">1680</column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">1566</column></item></PivotSet>
孙晓萌
<PivotSet><item><column name = "PRODUCT_NAME">苹果</column><column name = "SUM(AMOUNT)"></column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">2530</column></item></PivotSet>
王勇
<PivotSet><item><column name = "PRODUCT_NAME">苹果</column><column name = "SUM(AMOUNT)">1380</column></item><item><column name = "PRODUCT_NAME">橘子</column><column name = "SUM(AMOUNT)">1200</column></item></PivotSet>
4.11.2 UNPIVOT 子句
UNPIVOT 子句将一组数据从列转换为行。语法如下:
<UNPIVOT子句> ::= UNPIVOT [<include_null_clause>](<unpivot_val_col_lst> FOR <unpivot_for_clause> IN (<unpivot_in_clause_low> ))
<include_null_clause> ::= INCLUDE NULLS |
EXCLUDE NULLS
<unpivot_val_col_lst> ::= <表达式> |
(<表达式> {,<表达式>})
<unpivot_for_clause> ::= <表达式> |
(<表达式> {,<表达式>})
<unpivot_in_clause_low> ::= <unpivot_in_clause>{,<unpivot_in_clause>}
<unpivot_in_clause> ::= <列名> [AS <别名>] |
(<列名> {,<列名>}) [AS (<别名> {,<别名>})]
参数
- INCLUDE NULLS 转换后的结果中包含 NULL 值;
- EXCLUDE NULLS 转换后的结果中不包含 NULL 值,缺省为 EXCLUDE NULLS;
- <unpivot_val_col_lst> 指定转换后新列的列名,<unpivot_in_clause_low> 指定列的数据将作为该列数据。< 表达式 > 仅支持常量表达式;
- <unpivot_for_clause> 指定转换后新列的列名,<unpivot_in_clause_low> 指定列的列名或别名将作为该列数据。< 表达式 > 仅支持常量表达式;
- <unpivot_in_clause_low> 指定表或视图的原始列名。
使用说明
- <unpivot_val_col_lst>、<unpivot_for_clause> 或 <unpivot_in_clause> 中,针对多个 < 表达式 >、< 列名 > 或 < 别名 >,必须使用小括号括起来;针对单个 < 表达式 >、< 列名 > 或 < 别名 >,使用或者不使用小括号均可;
- <unpivot_val_col_lst> 和 <unpivot_for_clause> 中的表达式个数保持一致;
- <unpivot_for_clause> 中的表达式个数与 <unpivot_in_clause> 中的 AS 项别名个数保持一致;
- 多个 <unpivot_in_clause> 之间指定的列数据类型要保持一致;
- 仅支持对单表、视图、DBLINK 进行 UNPIVOT 转换;
- INI 参数 UNPIVOT_OPT_FLAG 可控制输出结果的顺序,UNPIVOT_OPT_FLAG 取值包含 1 时按照不包含在 UNPIVOT 中的列进行排序;
- UNPIVOT 中自定义的列名不能为保留字;
- <unpivot_in_clause_low> 中指定的转换列个数不能超过 1000 个;
- <unpivot_in_clause_low> 中指定的转换列不能是 ROWID、TRXID 等伪列,也不能是虚拟列;
- UNPIVOT 不支持 ROLLUP、CUBE、大于等于两个查询项的 GROUPING SETS、FOR UPDATE 子句、不能同时存在 PIVOT 子句。
举例说明
首先创建测试表 SALES_ORDER 并插入数据。相关 SQL 语句可参考 4.11.1 PIVOT 子句。由于 UNPIVOT 子句功能与 PIVOT 子句功能正好相反,因此可以利用 PIVOT 子句创建测试视图,方便展示 UNPIVOT 子句使用示例。
例 1 创建测试视图 PIVOT_SALES_ORDER_1。
CREATE VIEW PIVOT_SALES_ORDER_1 AS
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT)
FOR PRODUCT_NAME
IN('苹果' AS 苹果,'橘子' AS 橘子,'草莓' AS 草莓)
);
查询 PIVOT_SALES_ORDER_1 视图中数据。
SELECT * FROM PIVOT_SALES_ORDER_1;
查询结果如下:
SALESMAN 苹果 橘子 草莓
--------- ------ ------ ------
李兰 1680 1566 5950
王勇 1380 1200 5980
孙晓萌 NULL 2530 6470
使用 UNPIVOT 子句,将苹果、橘子、草莓三列数据转换为行。
SELECT * FROM PIVOT_SALES_ORDER_1
UNPIVOT (
TOTAL_AMOUNT
FOR PRODUCT_NAME
IN(苹果,橘子,草莓)
);
查询结果如下:
SALESMAN PRODUCT_NAME TOTAL_AMOUNT
--------- ------------ ------------
李兰 苹果 1680
王勇 苹果 1380
李兰 橘子 1566
王勇 橘子 1200
孙晓萌 橘子 2530
李兰 草莓 5950
王勇 草莓 5980
孙晓萌 草莓 6470
可以看到,由于缺省不显示 NULL 值,因此以上结果集中并未包含孙晓萌对苹果的销售金额信息。用户可使用 INCLUDE NULLS 来指定结果集中包含 NULL 值。
SELECT * FROM PIVOT_SALES_ORDER_1
UNPIVOT INCLUDE NULLS (
TOTAL_AMOUNT
FOR PRODUCT_NAME
IN(苹果,橘子,草莓)
);
查询结果如下:
SALESMAN PRODUCT_NAME TOTAL_AMOUNT
--------- ------------ ------------
李兰 苹果 1680
王勇 苹果 1380
孙晓萌 苹果 NULL
李兰 橘子 1566
王勇 橘子 1200
孙晓萌 橘子 2530
李兰 草莓 5950
王勇 草莓 5980
孙晓萌 草莓 6470
例 2 创建测试视图 PIVOT_SALES_ORDER_2。
CREATE VIEW PIVOT_SALES_ORDER_2 AS
SELECT *
FROM (SELECT SALESMAN,PRODUCT_NAME,AMOUNT FROM SALES_ORDER)
PIVOT (
SUM(AMOUNT) AS 金额,
COUNT(AMOUNT) AS 订单量
FOR PRODUCT_NAME
IN('苹果' AS 苹果,'橘子' AS 橘子,'草莓' AS 草莓)
);
查询 PIVOT_SALES_ORDER_2 视图中数据。
SELECT * FROM PIVOT_SALES_ORDER_2;
查询结果如下:
SALESMAN 苹果_金额 苹果_订单量 橘子_金额 橘子_订单量 草莓_金额 草莓_订单量
--------- ------------- -------------------- ------------- --------------------
李兰 1680 2 1566 1 5950 2
王勇 1380 2 1200 1 5980 2
孙晓萌 NULL 0 2530 2 6470 2
使用 UNPIVOT 子句,将所有金额列和订单量列转换为行。
SELECT * FROM PIVOT_SALES_ORDER_2
UNPIVOT (
(SUM_AMOUNT,COUNT_AMOUNT)
FOR (PRODUCT_NAME_SUM,PRODUCT_NAME_COUNT)
IN(
(苹果_金额,苹果_订单量) AS ('苹果销售额','苹果订单量'),
(橘子_金额,橘子_订单量) AS ('橘子销售额','橘子订单量'),
(草莓_金额,草莓_订单量) AS ('草莓销售额','草莓订单量')
)
);
查询结果如下:
SALESMAN PRODUCT_NAME_SUM PRODUCT_NAME_COUNT SUM_AMOUNT COUNT_AMOUNT
--------- ---------------- ------------------ ---------- --------------------
李兰 苹果销售额 苹果订单量 1680 2
王勇 苹果销售额 苹果订单量 1380 2
孙晓萌 苹果销售额 苹果订单量 NULL 0
李兰 橘子销售额 橘子订单量 1566 1
王勇 橘子销售额 橘子订单量 1200 1
孙晓萌 橘子销售额 橘子订单量 2530 2
李兰 草莓销售额 草莓订单量 5950 2
王勇 草莓销售额 草莓订单量 5980 2
孙晓萌 草莓销售额 草莓订单量 6470 2
UNPIVOT 子句缺省不显示 NULL 值,但仅当 SUM_AMOUNT 和 COUNT_AMOUNT 同时为 NULL 时才不显示,因此以上结果集中仍然包含孙晓萌对苹果的销售金额和订单量信息。
4.12 全文检索
DM 数据库提供多文本数据检索服务,包括全文索引和全文检索。全文索引为在字符串数据中进行复杂的词搜索提供了有效支持。全文索引存储关于词和词在特定列中的位置信息,全文检索利用这些信息,可以快速搜索包含某个词或某一组词的记录。
执行全文检索涉及到以下这些任务:
- 对需要进行全文检索的表和列进行注册;
- 对注册了的列的数据建立全文索引;
- 对注册了的列查询填充后的全文索引。
执行全文检索步骤如下:
1.建立全文索引;
2.修改(填充)全文索引;
3.使用带 CONTAINS 谓词的查询语句进行全文检索;
4.当数据表的全文索引列数据发生变化,则需要进行增量或者完全填充全文索引,以便可以查询到更新后的数据;
5.若不再需要全文索引,可以删除该索引;
6.在全文索引定义并填充后,才可进行全文检索。
全文检索通过在查询语句的 WHERE < 搜索条件 > 中,指定 < 搜索条件 > 为 CONTAINS 子句进行。此处对 CONTAINS 子句进行说明。
语法格式
CONTAINS ( <列名> , <检索条件>[,<CONTAINS号>] )
<检索条件>::= <布尔项> | <检索条件> <AND | OR | AND NOT> <布尔项>
<布尔项>::= '字符串'
图例
全文检索
使用说明
- CONTAINS 子句仅支持在对基表的查询语句中使用;使用 CONTAINS 子句查询时,< 列名 > 必须是已经建立了全文索引并填充后的基表列,否则系统会报错;
- 一条 sql 中的同一个表对象最多包含 10 个 CONTAINS 子句,CONTAINS 子句的 <CONTAINS 号 > 不能相同。其中,<CONTAINS 号 > 为 CONTAINS 子句的标识号,INT 类型,取值范围为 0~100000;
- 支持精确字、词、短语及一段文字的查询,CONTAINS 谓词内支持 AND | AND NOT | OR 的使用,AND 的优先级高于 OR 的优先级;
- 支持对每个精确词(单字节语言中没有空格或标点符号的一个或多个字符)或短语(单字节语言中由空格和可选的标点符号分隔的一个或多个连续的词)的匹配。对词或短语中字符的搜索不区分大小写;
- 对于短语或一段文字的查询,根据词库,单个查找串被分解为若干个关键词,忽略词库中没有的词和标点符号,在索引上进行(关键词 AND 关键词)匹配查找。因而,不一定是精确查询;
- 英文查询不区分大小写和全角半角中英文字符;
- 不提供 Noise 文件,即不考虑忽略词或干扰词;
- 不支持通配符“*”;
- 不提供对模糊词或变形词的查找;
- 不支持对结果集的相关度排名;
- 检索条件子句可以和其他子句共同组成 WHERE 的检索条件。
举例说明
例 全文检索综合实例,以 PRODUCT 表为例。
(1)在 DESCRIPTION 列上定义全文索引。
CREATE CONTEXT INDEX INDEX1 ON PRODUCTION.PRODUCT(DESCRIPTION) LEXER CHINESE_VGRAM_LEXER;
(2)完全填充全文索引。
ALTER CONTEXT INDEX INDEX1 ON PRODUCTION.PRODUCT REBUILD;
(3)进行全文检索,查找描述里有“语言”字样的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT WHERE CONTAINS(DESCRIPTION,'语言');
查询结果如下:
PRODUCTID NAME
----------- -------------------------
2 水浒传
7 数据结构(C语言版)(附光盘)
(4) 进行全文检索,查找描述里有“语言”及“中国”字样的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT WHERE CONTAINS(DESCRIPTION,'语言' AND '中国');
查询结果如下:
PRODUCTID NAME
----------- ------
2 水浒传
(5)进行全文检索,查找描述里有“语言”或“中国”字样的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT WHERE CONTAINS(DESCRIPTION,'语言' OR '中国');
查询结果如下:
PRODUCTID NAME
----------- -------------------------
2 水浒传
7 数据结构(C语言版)(附光盘)
1 红楼梦
(6)进行全文检索,查找描述里无“中国”字样的雇员的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT WHERE NOT CONTAINS(DESCRIPTION,'中国');
查询结果如下:
PRODUCTID NAME
----------- --------------------------------
3 老人与海
4 射雕英雄传(全四册)
5 鲁迅文集(小说、散文、杂文)全两册
6 长征
7 数据结构(C语言版)(附光盘)
8 工作中无小事
9 突破英文基础词汇
10 噼里啪啦丛书(全7册)
(7)进行全文检索,查找描述里有“C 语言”字样的产品的编号和名称。
SELECT PRODUCTID, NAME FROM PRODUCTION.PRODUCT WHERE CONTAINS(DESCRIPTION,'C语言');
查询结果如下:
PRODUCTID NAME
----------- -------------------------
7 数据结构(C语言版)(附光盘)
(8)对不再需要的全文索引进行删除。
DROP CONTEXT INDEX INDEX1 ON PRODUCTION.PRODUCT;
4.13 层次查询子句
可通过层次查询子句进行层次查询,得到数据间的层次关系。在使用层次查询子句时,可以使用层次查询相关的伪列、函数或操作符来明确层次查询结果中的相应层次信息。
4.13.1 层次查询子句
语法格式
<层次查询子句> ::=
CONNECT BY [NOCYCLE] <连接条件> [ START WITH <起始条件> ] |
START WITH <起始条件> CONNECT BY [NOCYCLE] <连接条件>
<连接条件>::= <逻辑表达式>
<起始条件>::= <逻辑表达式>
参数
- <连接条件> 逻辑表达式,指明层次数据间的层次连接关系;
- <起始条件> 逻辑表达式,指明选择层次数据根数据的条件;
- NOCYCLE 关键字用于指定数据导致环的处理方式,如果在层次查询子句中指定 NOCYCLE 关键字,会忽略导致环元组的儿子数据。否则,返回错误。
4.13.2 层次查询相关伪列
在使用层次查询子句时,可以通过相关的伪列来明确数据的层次信息。层次查询相关的伪列有:
1.LEVEL 该伪列表示当前元组在层次数据形成的树结构中的层数。LEVEL 的初始值为 1,即层次数据的根节点数据的 LEVEL 值为 1,之后其子孙节点的 LEVEL 依次递增。
2.CONNECT_BY_ISLEAF 该伪列表示当前元组在层次数据形成的树结构中是否是叶节点(即该元组根据连接条件不存在子结点)。是叶节点时为 1,否则为 0。
3.CONNECT_BY_ISCYCLE 该伪列表示当前元组是否会将层次数据形成环,该伪列只有在层次查询子句中表明 NOCYCLE 关键字时才有意义。如果元组的存在会导致层次数据形成环,该伪列值为 1,否则为 0。
4.13.3 层次查询相关操作符
1.PRIOR
PRIOR 操作符主要使用在层次查询子句中,指明 PRIOR 之后的参数为逻辑表达式中的父节点。
PRIOR exp 属于层次查询条件,只能出在包含层次查询的 SQL 语句中。在这类语句中,PRIOR exp 可以充当普通表达式,没有额外使用限制,例如:PRIOR 操作符可以出现在查询项、WHERE 条件,GROUP BY 子句、ORDER BY 子句中等,当这类 SQL 语句中使用函数时,PRIOR 关键字甚至出现在函数参数中。
例
SELECT HIGH_DEP, DEP_NAME FROM OTHER.DEPARTMENT CONNECT BY NOCYCLE PRIOR DEP_NAME = HIGH_DEP;
//DEP_NAME为父节点。下一条记录的HIGH_DEP等于前一条记录的DEP_NAME
或者
SELECT HIGH_DEP, DEP_NAME FROM OTHER.DEPARTMENT CONNECT BY NOCYCLE DEP_NAME = PRIOR HIGH_DEP;
//HIGH_DEP 为父节点。下一条记录的DEP_NAME等于前一条记录的HIGH_DEP
2.CONNECT_BY_ROOT
该操作符作为查询项,查询在层次查询结果中根节点的某列的值。
4.13.4 层次查询相关函数
语法格式
SYS_CONNECT_BY_PATH(col_name,char)
语句功能
层次查询。
使用说明
该函数得到从根节点到当前节点路径上所有节点名为 col_name 的某列的值,之间用 char 指明的字符分隔开。
4.13.5 层次查询层内排序
语法格式
ORDER SIBLINGS BY <order_by_list>
<order_by_list>请参考4.7 ORDER BY子句
语句功能
层次查询。
使用说明
ORDER SIBLINGS BY 用于指定层次查询中相同层次数据返回的顺序。在层次查询中使用 ORDER SIBLINGS BY,必须与 CONNECT BY 一起配合使用。但是,ORDER SIBLINGS BY 不能和 GROUP BY 一起使用。
4.13.6 层次查询的限制
- CONNECT BY 子句中不支持集函数、嵌套集函数、TRXID 以及 GROUPING 函数;START WITH 子句中不支持集函数、嵌套集函数、TRXID、GROUPING 函数、层次查询相关伪列、层次查询相关函数、层次查询相关操作符、FOR UPDATE 子句;
- ORDER SIBLINGS BY 子句中不能使用层次查询相关伪列、层次查询相关函数、层次查询相关操作符、ROWNUM 以及子查询;
- 层次查询子句不能使用伪列 CONNECT_BY_ISLEAF、CONNECT_BY_ISCYCLE、SYS_CONNECT_BY_PATH 伪函数和 CONNECT_BY_ROOT 操作符;
- JOIN ON 子句中不允许出现层次查询相关伪列、层次查询相关函数、层次查询相关操作符;
- PRIOR、CONNECT_BY_ROOT 操作符后不能使用层次查询相关伪列、层次查询相关函数、层次查询相关操作符以及 ROWNUM;SYS_CONNECT_BY_PATH 函数的第一个参数不能使用层次查询的 CONNECT_BY_ISLEAF 或 CONNECT_BY_ISCYCLE 伪列、层次查询相关函数、层次查询相关操作符,SYS_CONNECT_BY_PATH 的第一个参数允许出现 LEVEL 伪列且第二个参数必须是常量字符串;
- 函数 SYS_CONNECT_BY_PATH 的最大返回长度为 32767,超长就会报错;
- INI 参数 CNNTB_MAX_LEVEL 表示支持层次查询的最大层次,缺省为 20000。该参数的有效取值范围为 1~100000。
- 同一层查询中不同 SYS_CONNECT_BY_PATH 函数的个数上限为 64 个。
例如,对 OTHER.DEPARTMENT 数据进行层次查询,HIGH_DEP 表示上级部门;DEP_NAME 表示部门名称。
层次数据所建立起来的树形结构如下图:
例 1 不带起始选择根节点起始条件的层次查询
SELECT HIGH_DEP, DEP_NAME FROM OTHER.DEPARTMENT CONNECT BY PRIOR DEP_NAME = HIGH_DEP;
查询结果如下:
HIGH_DEP DEP_NAME
---------- --------------
NULL 总公司
总公司 财务部
总公司 采购部
总公司 服务部
服务部 企业服务部
服务部 读者服务部
读者服务部 书籍阅览服务部
读者服务部 书籍借阅服务部
服务部 网络服务部
总公司 服务部
服务部 企业服务部
服务部 读者服务部
读者服务部 书籍阅览服务部
读者服务部 书籍借阅服务部
服务部 网络服务部
总公司 采购部
总公司 财务部
服务部 网络服务部
服务部 读者服务部
读者服务部 书籍阅览服务部
读者服务部 书籍借阅服务部
服务部 企业服务部
读者服务部 书籍借阅服务部
读者服务部 书籍阅览服务部
结果是以表中所有的节点为根节点进行先根遍历进行层次查询。
例 2 带起始选择根节点起始条件的层次查询
SELECT HIGH_DEP, DEP_NAME FROM OTHER.DEPARTMENT CONNECT BY PRIOR DEP_NAME=HIGH_DEP START WITH DEP_NAME='总公司';
查询结果如下:
HIGH_DEP DEP_NAME
---------- --------------
NULL 总公司
总公司 财务部
总公司 采购部
总公司 服务部
服务部 企业服务部
服务部 读者服务部
读者服务部 书籍阅览服务部
读者服务部 书籍借阅服务部
服务部 网络服务部
例 3 层次查询伪列的使用
在层次查询中,伪列的使用可以更明确层次数据之间的关系。
SELECT LEVEL,
CONNECT_BY_ISLEAF ISLEAF,
CONNECT_BY_ISCYCLE ISCYCLE,
HIGH_DEP, DEP_NAME FROM OTHER.DEPARTMENT
CONNECT BY PRIOR DEP_NAME=HIGH_DEP
START WITH DEP_NAME='总公司';
查询结果如下:
LEVEL ISLEAF ISCYCLE HIGH_DEP DEP_NAME
--------- -------- ----------- ---------- --------------
1 0 0 NULL 总公司
2 1 0 总公司 财务部
2 1 0 总公司 采购部
2 0 0 总公司 服务部
3 1 0 服务部 企业服务部
3 0 0 服务部 读者服务部
4 1 0 读者服务部 书籍阅览服务部
4 1 0 读者服务部 书籍借阅服务部
3 1 0 服务部 网络服务部
通过伪列,可以清楚地看到层次数据之间的层次结构。
例 4 含有过滤条件的层次查询
在层次查询中加入过滤条件,将会先进行层次查询,然后进行过滤。
SELECT LEVEL,* FROM OTHER.DEPARTMENT WHERE HIGH_DEP = '总公司' CONNECT BY PRIOR DEP_NAME=HIGH_DEP;
查询结果如下:
LEVEL HIGH_DEP DEP_NAME
----------- -------- --------
2 总公司 财务部
2 总公司 采购部
2 总公司 服务部
1 总公司 服务部
1 总公司 采购部
1 总公司 财务部
例 5 含有排序子句的层次查询
在层次查询中加入排序,查询将会按照排序子句指明的要求排序,不再按照层次查询的排序顺序排序。
SELECT * FROM OTHER.DEPARTMENT CONNECT BY PRIOR DEP_NAME=HIGH_DEP START WITH DEP_NAME='总公司' ORDER BY HIGH_DEP;
查询结果如下:
HIGH_DEP DEP_NAME
---------- --------------
NULL 总公司
读者服务部 书籍阅览服务部
读者服务部 书籍借阅服务部
服务部 企业服务部
服务部 读者服务部
服务部 网络服务部
总公司 服务部
总公司 采购部
总公司 财务部
例 6 含层内排序子句的层次查询
在层次查询中加入 ORDER SIBLINGS BY,查询会对相同层次的数据进行排序后返回数据,即 LEVEL 相同的数据进行排序。
SELECT HIGH_DEP, DEP_NAME, LEVEL FROM OTHER.DEPARTMENT CONNECT BY PRIOR
DEP_NAME=HIGH_DEP START WITH DEP_NAME='总公司' ORDER SIBLINGS BY DEP_NAME;
查询结果如下:
HIGH_DEP DEP_NAME LEVEL
---------- -------------- -----------
NULL 总公司 1
总公司 财务部 2
总公司 采购部 2
总公司 服务部 2
服务部 读者服务部 3
读者服务部 书籍借阅服务部 4
读者服务部 书籍阅览服务部 4
服务部 企业服务部 3
服务部 网络服务部 3
例 7 CONNECT_BY_ROOT 操作符的使用
CONNECT_BY_ROOT 操作符之后跟某列的列名,例如:
CONNECT_BY_ROOT DEP_NAME
进行如下查询:
SELECT CONNECT_BY_ROOT DEP_NAME,* FROM OTHER.DEPARTMENT CONNECT BY PRIOR DEP_NAME=HIGH_DEP START WITH DEP_NAME='总公司' ;
查询结果如下:
CONNECT_BY_ROOT(DEP_NAME) HIGH_DEP DEP_NAME
------------------------- ---------- --------------
总公司 NULL 总公司
总公司 总公司 财务部
总公司 总公司 采购部
总公司 总公司 服务部
总公司 服务部 企业服务部
总公司 服务部 读者服务部
总公司 读者服务部 书籍阅览服务部
总公司 读者服务部 书籍借阅服务部
总公司 服务部 网络服务部
例 8 SYS_CONNECT_BY_PATH 函数的使用
函数的使用方式,如:
SYS_CONNECT_BY_PATH(DEP_NAME, '/')
进行如下查询:
SELECT SYS_CONNECT_BY_PATH(DEP_NAME, '/') PATH,* FROM OTHER.DEPARTMENT CONNECT
BY PRIOR DEP_NAME=HIGH_DEP START WITH DEP_NAME='总公司' ;
查询结果如下:
PATH HIGH_DEP DEP_NAME
---------------------------------------- ---------- --------------
/总公司 NULL 总公司
/总公司/财务部 总公司 财务部
/总公司/采购部 总公司 采购部
/总公司/服务部 总公司 服务部
/总公司/服务部/企业服务部 服务部 企业服务部
/总公司/服务部/读者服务部 服务部 读者服务部
/总公司/服务部/读者服务部/书籍阅览服务部 读者服务部 书籍阅览服务部
/总公司/服务部/读者服务部/书籍借阅服务部 读者服务部 书籍借阅服务部
/总公司/服务部/网络服务部 服务部 网络服务部
4.14 并行查询
达梦支持并行查询。并行查询的详细用法请参考《DM8 系统管理员手册》。
使用并行查询,可选择如下任一方式实现:
方式一 自动并行。先设置好并行查询 INI 参数(PARALLEL_POLICY =1、PARALLEL_THRD_NUM 、MAX_PARALLEL_DEGREE),然后执行 SQL 语句,即可使用并行查询。如果既使用了 MAX_PARALLEL_DEGREE 设置并行度,又在 SQL 语句中使用了 HINT PARALLEL 设置并行度,则 HINT PARALLEL 优先。
方式二 手动并行。先设置好并行查询 INI 参数(PARALLEL_POLICY=2 、PARALLEL_THRD_NUM),然后执行使用 HINT PARALLEL 指定并行度的 SQL 语句,即可使用并行查询。
例 1 使用自动并行。
首先,设置并行查询 INI 参数。PARALLEL_POLICY=1 表示自动并行;PARALLEL_THRD_NUM=32 表示服务器并行线程池中并行线程总个数为 32;MAX_PARALLEL_DEGREE 表示并行度为 8,即最大并行线程数。PARALLEL_THRD_NUM 参数须重启生效。
PARALLEL_POLICY 1
PARALLEL_THRD_NUM 32
MAX_PARALLEL_DEGREE 8
其次,执行 SQL 语句,SQL 语句即可使用并行查询,并行度为 8。现实环境中,也可能因为实际可用线程不足,导致查询使用的实际并行度低于 8 的情况。
SELECT * FROM SYSOBJECTS;
例 2 使用手动并行。
首先,设置并行查询 INI 参数。PARALLEL_POLICY=1 表示自动并行;PARALLEL_THRD_NUM=32 表示服务器并行线程池中并行线程总个数为 32。
PARALLEL_POLICY 1
PARALLEL_THRD_NUM 32
其次,执行使用 HINT PARALLEL 指定并行度的 SQL 语句,即可使用并行查询。PARALLEL(8)表示并行度为 8。现实环境中,也可能因为实际可用线程不足,导致查询使用的实际并行度低于 8 的情况。
SELECT /*+ PARALLEL(8) */ * FROM SYSOBJECTS;
例 3 查看执行计划。并行查询执行计划中会出现并行操作符 LOCAL COLLECT。LOCAL COLLECT 操作符用于并行模式下进行数据收集处理。例如上一个示例的执行计划如下:
EXPLAIN SELECT /*+ PARALLEL(8) */ * FROM SYSOBJECTS;
1 #NSET2: [1, 1124, 397]
2 #LOCAL COLLECT: [1, 1124, 397]; op_id(1) n_grp_by (0) n_cols(0) n_keys(0) for_sync(FALSE)
3 #PRJT2: [1, 1124, 397]; exp_num(17), is_atom(FALSE); INFO_BITS(0); ...; spl_info(NULL)
4 #CSCN2: [1, 1124, 397]; SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS); btr_scan(1); need_slct(0); prejudge_iescn(0)
4.15 ROWNUM
ROWNUM 是一个伪列,表示从表中查询的行号,或者连接查询的结果集行数。它将被分配为 1,2,3,4,...N,N 是行的数量。通过使用 ROWNUM 可以限制查询返回的行数。例如,以下语句执行只会返回前 5 行数据。
SELECT * FROM RESOURCES.EMPLOYEE WHERE ROWNUM < 6;
一个 ROWNUM 值不是被永久的分配给一行。表中的某一行并没有标号,不可以查询 ROWNUM 值为 5 的行。ROWNUM 值只有当被分配之后才会增长,并且初始值为 1。即只有满足一行后,ROWNUM 值才会加 1,否则只会维持原值不变。因此,以下语句在任何时候都不能返回数据。
SELECT * FROM RESOURCES.EMPLOYEE WHERE ROWNUM > 11;
SELECT * FROM RESOURCES.EMPLOYEE WHERE ROWNUM = 5;
ROWNUM 的一个重要作用是控制返回结果集的规模,可以避免查询在磁盘中排序。
因为 ROWNUM 值的分配是在查询的谓词解析之后,任何排序和聚合之前进行的。因此,在排序和聚合使用 ROWNUM 时需要注意,可能得到并非预期的结果,例如:
SELECT * FROM RESOURCES.EMPLOYEE WHERE ROWNUM < 11 ORDER BY EMPLOYEEID;
以上语句只会对 EMPLOYEE 表前 10 行数据按 EMPLOYEEID 排序输出,并不是表的所有数据按 EMPLOYEEID 排序后输出前 10 行,要实现后者,需要使用如下语句:
SELECT * FROM (SELECT * FROM RESOURCES.EMPLOYEE ORDER BY EMPLOYEEID) WHERE ROWNUM < 11;
SELECT TOP 10 * FROM RESOURCES.EMPLOYEE ORDER BY EMPLOYEEID;
使用说明
1.在查询中,ROWNUM 可与任何数字类型表达式进行比较及运算;
2.ROWNUM 可以在非相关子查询中使用;当参数 ENABLE_RQ_TO_INV 等于 1 时,部分相关子查询支持使用;
3.在非相关子查询中,ROWNUM 只能实现与 TOP 相同的功能,因此子查询不能含 ORDER BY 和 GROUP BY;
4.ROWNUM 所处的子谓词只能为如下形式: ROWNUM op exp,exp 的类型只能是立即数、参数和变量值,op ∈ {<, <=, >, >=, =,<>}。
4.16 BINARY 前缀
数据库是否大小写敏感通过建库参数 CASE_SENSITIVE 控制,初始化后便无法修改,可以通过系统函数 SF_GET_CASE_SENSITIVE_FLAG()或 CASE_SENSITIVE()查询设置的参数值。为了便于用户在数据库初始化后依旧可以按需求进行局部大小写敏感的字符比较操作,提供 BINARY 前缀方式用于设置表达式比较时为大小写敏感。字符的局部大小写敏感还可以通过设置会话属性进行,请参考 3.15.5 大小写敏感。
BINARY 前缀支持范围:
- SQL 项:查询项、过滤条件、连接条件、层次查询条件、having 条件、排序项、分组项。
- 表达式类型:逻辑比较表达式、模糊查询表达式(包括 row like)、查询表达式(例如:in、逻辑比较,但不支持多列 in、多列逻辑比较)等。
BINARY 前缀在顶层查询项的含义是将查询项转换为原始值字符串 ASCII 码的十六进制形式,例如:将 123abc 转换为 0x313233616263;在除顶层查询项外的其他位置则表示该前缀修饰的表达式将按照大小写敏感进行比较,无论当前数据库为大小写敏感或不敏感。
例 在顶层查询中添加 BINARY 前缀与在子查询中添加 BINARY 前缀。
CREATE TABLE BT(C1 VARCHAR, C2 VARCHAR, C3 VARCHAR);
INSERT INTO BT VALUES('AaBbCc','a','A');
INSERT INTO BT VALUES('KkKkKk','B','b');
INSERT INTO BT VALUES('A','b','C');
INSERT INTO BT VALUES('avcs','A','b');
在顶层查询中添加 BINARY 前缀。
SELECT BINARY C1 FROM BT;
查询结果如下:
行号 BINARYC1
---------- --------------
1 0x416142624363
2 0x4B6B4B6B4B6B
3 0x41
4 0x61766373
在子查询中添加 BINARY 前缀。
SELECT * FROM (SELECT BINARY C1 FROM BT);
查询结果如下:
行号 C1
---------- ------
1 AaBbCc
2 KkKkKk
3 A
4 avcs
在条件查询的子查询中添加 BINARY 前缀。
SELECT C1 FROM BT WHERE C1 = (SELECT TOP 1 BINARY C1 FROM BT);
行号 C1
---------- ------
1 AaBbCc
BINARY 前缀位于过滤条件、连接条件、HAVING 条件或层次查询条件中的表达式之前时,该表达式在比较时按照大小写敏感比较,且 BINARY 前缀只对当前 and/or 子句生效。例如:在表达式 c1 = 'a' and binary c2 = 'b' and c3 = 'c'中只有第二个条件一定按照大小写敏感比较,其它两个条件仍按照数据库参数是否大小写敏感比较。
例 1 在数据库初始化为大小写不敏感的情况下(即参数 CASE_SENSITIVE=0),执行查询语句,其中只有一条 and 子句添加 BINARY 前缀。
SELECT C1,C2,C3 FROM BT WHERE C1 = 'a' AND BINARY C2 = 'b' AND C3 = 'c';
查询结果如下:
行号 C1 C2 C3
---------- -- -- --
1 A b C
例 2 在数据库初始化为大小写敏感的情况下(即参数 CASE_SENSITIVE=1),执行查询语句,其中只有一条 and 子句添加 BINARY 前缀。
SELECT C1,C2,C3 FROM BT WHERE C1 = 'a' AND BINARY C2 = 'b' AND C3 = 'c';
查询结果如下:
未选定行
BINARY 前缀位于排序项或分组项中的表达式之前时,该表达式按照大小写敏感进行排序/分组,若存在多个排序项/分组项,则仅有含有 BINARY 前缀的项生效,其余项仍按照数据库参数是否大小写敏感进行排序/分组。
例 在数据库初始化为大小写不敏感的情况下,对排序项中不添加 BINARY 前缀与添加 BINARY 前缀进行对比。
排序项中不添加 BINARY 前缀。
SELECT C1,C2,C3 FROM BT ORDER BY C2;
查询结果如下:
行号 C1 C2 C3
---------- ------ -- --
1 AaBbCc a A
2 avcs A b
3 A b C
4 KkKkKk B b
对排序项中添加 BINARY 前缀。
SELECT C1,C2,C3 FROM BT ORDER BY BINARY C2;
查询结果如下:
行号 C1 C2 C3
---------- ------ -- --
1 avcs A b
2 KkKkKk B b
3 AaBbCc a A
4 A b C
使用说明
- 仅对字符类型生效,其他数据类型忽略 BINARY 前缀。
- 多列比较不支持 BINARY 前缀,例如多列逻辑比较,多列 IN LIST 等。
- 创建索引时忽略 BIANRY 前缀。
- 确定性函数参数忽略 BINARY 前缀。
- CONTAINS 表达式忽略 BINARY 前缀。
- ALL/SOME/ANY 子查询忽略 BINARY 前缀。
- 层次查询表达式忽略 BINARY 前缀。
- 集函数参数包括 WITHIN GROUP 中排序表达式忽略 BINARY 前缀。
- 分析函数参数包括 OVER 中的排序表达式、分组表达式忽略 BINARY 前缀。
4.17 数组查询
在 DM 中,可以通过查询语句查询数组信息。即<FROM 子句>中<普通表>使用数组。语法如下:
FROM ARRAY <数组>
目前 DM 只支持一维数组的查询。
数组类型可以是记录类型和普通数据库类型。如果为记录类型的数组,则记录的成员都必须为标量(基本)数据类型。记录类型数组查询出来的列名为记录类型每一个属性的名字。普通数据库类型查询出来的列名均为“COLUMN_VALUE”。
例 1 查看数组
SELECT * FROM ARRAY NEW INT[2]{1};
查询结果如下:
COLUMN_VALUE
---------------
1
NULL
例 2 数组与表的连接
DECLARE
TYPE rrr IS RECORD (x INT, y INT);
TYPE ccc IS ARRAY rrr[];
c ccc;
BEGIN
c = NEW rrr[2];
FOR i IN 1..2 LOOP
c[i].x = i;
c[i].y = i*2;
END LOOP;
SELECT arr.x, o.name FROM ARRAY c arr, SYSOBJECTS o WHERE arr.x = o.id;
END;
返回结果为:
X NAME
----------- ----------
1 SYSINDEXES
2 SYSCOLUMNS
4.18 TABLE 函数查询
在 DM 中,可以通过 TABLE 函数查询集合信息。即在 <FROM 子句 > 中的 < 普通表 > 选择使用 TABLE 函数。语法如下:
FROM TABLE(<collection_exp>)
<collection_exp> 参数为集合类型,支持 VARRAY 数组集合和嵌套表集合。TABLE 函数将返回一张表,表中包含 COLUMN_VALUE 列,集合元素值将作为 COLUMN_VALUE 列数据,COLUMN_VALUE 列的数据类型与集合元素数据类型一致。
<collection_exp> 参数为集合类型,支持 VARRAY 数组集合、嵌套表集合或返回值为数据集合的自定义函数。使用 TABLE 函数查询将返回一张表,表中包含 COLUMN_VALUE 列,集合元素值将作为 COLUMN_VALUE 列数据,COLUMN_VALUE 列的数据类型与集合元素数据类型一致。
如果 <collection_exp> 为子查询,则该子查询结果集中只能包含一条记录,包含多条记录时将报错。
如果 <collection_exp> 为用户自定义函数(用户自定义函数的相关语法具体请参考《DM8_SQL 程序设计》),需确保该函数的返回值为集合类型,否则将会报错。
例 1 通过 TABLE 函数查看 VARRAY 数组集合中的数据。
--创建VARRAY数组集合ARR1
CREATE OR REPLACE TYPE ARR1 AS VARRAY(3) OF NUMBER;
/
--建立表T_ARR,表中第二列的列类型为ARR1,并向表中插入数据。
CREATE TABLE T_ARR (C1 INT, C2 ARR1);
INSERT INTO T_ARR VALUES(1,ARR1(1,2));
INSERT INTO T_ARR VALUES(2,ARR1(3,4,5));
--查询VARRAY数组集合中的数据
SELECT * FROM TABLE(SELECT C2 FROM T_ARR WHERE C1=2);
查询结果如下:
行号 COLUMN_VALUE
---------- ------------
1 3
2 4
3 5
例 2 通过 TABLE 函数查看嵌套表中的数据。
--创建嵌套表类型CHA1
CREATE OR REPLACE TYPE CHA1 AS TABLE OF CHAR;
/
--建立表T_CHAR,表中第二列的列类型为CHA1,并向表中插入数据。
CREATE TABLE T_CHAR (C1 INT, C2 CHA1);
INSERT INTO T_CHAR VALUES(1,CHA1('A','B'));
INSERT INTO T_CHAR VALUES(2,CHA1('C','D','E'));
--查询嵌套表中的数据
SELECT * FROM TABLE(SELECT C2 FROM T_CHAR WHERE C1=2);
查询结果如下:
行号 COLUMN_VALUE
---------- ------------
1 C
2 D
3 E
例 3 通过 TABLE 函数查看自定义函数返回结果集中的数据。
--创建嵌套表类型NUM1
CREATE OR REPLACE TYPE NUM1 AS TABLE OF NUMBER;
/
--建立表T_NUM,表中第二列的列类型为NUM1,并向表中插入数据。
CREATE TABLE T_NUM (C1 INT, C2 NUM1);
INSERT INTO T_NUM VALUES(1,NUM1(1,2,3));
INSERT INTO T_NUM VALUES(2,NUM1(4,5,6,7));
--创建返回类型为NUM1的自定义函数GetNum(),用于获取数据
CREATE FUNCTION GetNum()
RETURN NUM1
AS
n NUM1;
BEGIN
SELECT C2 INTO n FROM T_NUM WHERE C1 = 2;
return n;
END;
/
--查询自定义函数的返回值集合
SELECT * FROM TABLE(GetNum());
查询结果如下:
行号 COLUMN_VALUE
---------- ------------
1 4
2 5
3 6
4 7
4.19 查看执行计划
4.19.1 EXPLAIN
EXPLAIN 语句可以查看 DML 语句的执行计划。
语法格式
EXPLAIN <SQL语句>;
<SQL语句> ::= <删除语句> | <插入语句> | <查询语句> | <更新语句> | <MERGE INTO语句>
参数
1.<删除语句> 指数据删除语句;
2.<插入语句> 指数据插入语句;
3.<查询语句> 指查询语句;
4.<更新语句> 指数据更新语句;
5.< MERGE INTO 语句 > 指依据设定条件,将源表数据合并至目标表中的语句。
图例
EXPLAIN 语句
语句功能
供用户查看执行计划。用户须拥有相应 DML 语句的权限。
举例说明
例 显示如下语句的查询计划:
EXPLAIN SELECT NAME,schid
FROM SYSOBJECTS
WHERE SUBTYPE$='STAB' AND NAME
NOT IN (
SELECT NAME FROM SYSOBJECTS WHERE NAME IN (SELECT NAME FROM SYSOBJECTS WHERE SUBTYPE$='STAB') AND TYPE$='DSYNOM')
查询结果如下:
1 #NSET2: [1, 28, 100]
2 #PRJT2: [1, 28, 100]; exp_num(2), is_atom(FALSE); INFO_BITS(0); spl_info(NULL)
3 #HASH LEFT SEMI JOIN2: [1, 28, 100]; (ANTI), KEY_NUM(1), KEY(SYSOBJECTS.NAME = DMTEMPVIEW_889193466.colname), KEY_NULL_EQU(0)
4 #SLCT2: [1, 28, 100]; SYSOBJECTS.SUBTYPE$ = 'STAB'; slct_pushdown(1); spl_info(NULL); flt_batch_exec(1)
5 #CSCN2: [1, 1124, 100]; SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS); btr_scan(1); need_slct(1); prejudge_iescn(0)
6 #PRJT2: [1, 1, 96]; exp_num(1), is_atom(FALSE); INFO_BITS(0); spl_info(NULL)
7 #INDEX JOIN SEMI JOIN2: [1, 1, 96]; join condition(SYSOBJECTS.SUBTYPE$ = 'STAB'), flt_batch_exec(0)
8 #CSEK2: [1, 28, 96]; scan_type(ASC), SYSINDEXSYSOBJECTS(SYSOBJECTS as SYSOBJECTS), scan_range[('DSYNOM',min,min),('DSYNOM',max,max))
9 #BLKUP2: [1, 3, 96]; SYSINDEXNAMESYSOBJECTS(SYSOBJECTS); use_clu_addr(0)
10 #SSEK2: [1, 3, 96]; scan_type(ASC), SYSINDEXNAMESYSOBJECTS(SYSOBJECTS as SYSOBJECTS), scan_range[SYSOBJECTS.NAME,SYSOBJECTS.NAME], is_global(0)
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access(SYSOBJECTS.NAME = DMTEMPVIEW_889193466.colname)
4 - filter(SYSOBJECTS.SUBTYPE$ = 'STAB')
7 - filter(SYSOBJECTS.SUBTYPE$ = 'STAB')
4.19.2 EXPLAIN FOR
EXPLAIN FOR 语句也用于查看 DML 语句的执行计划,不过执行计划以结果集的方式返回。
EXPLAIN FOR 显示的执行计划信息更加丰富,除了常规计划信息,还包括创建索引建议、分区表的起止分区信息等。重要的是,语句的计划保存在数据表中,方便用户随时查看,进行计划对比分析,可以作为性能分析的一种方法。
语法格式
EXPLAIN [AS <计划名称>] FOR <SQL语句>;
<SQL语句> ::= <删除语句> | <插入语句> | <查询语句> | <更新语句>
参数
1.<删除语句> 指数据删除语句;
2.<插入语句> 指数据插入语句;
3.<查询语句> 指查询语句;
4.<更新语句> 指数据更新语句。
图例
EXPLAIN FOR 语句
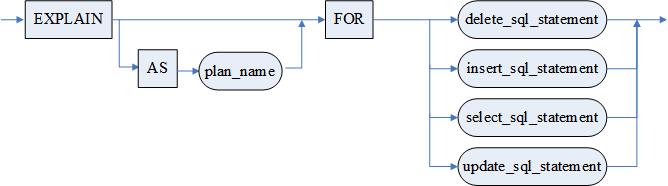
语句功能
供用户以结果集的方式查看执行计划。用户须拥有相应 DML 语句的权限。
举例说明
例 1 以结果集的方式显示如下语句的查询计划:
EXPLAIN FOR SELECT NAME, SCHID FROM SYS.SYSOBJECTS WHERE SUBTYPE $='STAB';
查询结果如下,可见未设置计划名称(即 PLAN_NAME),缺省为 NULL:
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
1 4 NULL 2022-12-14 13:52:46.000000 0 NSET2 NULL NULL
NULL NULL 65 100 1 0
0 NULL NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
2 4 NULL 2022-12-14 13:52:46.000000 1 PRJT2 NULL NULL
NULL NULL 65 100 1 0
0 NULL NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
3 4 NULL 2022-12-14 13:52:46.000000 2 SLCT2 NULL NULL
NULL NULL 65 100 1 0
0 SYSOBJECTS.SUBTYPE$ = 'STAB' NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
4 4 NULL 2022-12-14 13:52:46.000000 3 CSCN2 SYSOBJECTS SYSINDEXSYSOBJECTS
NULL NULL 1103 100 1 0
0 NULL NULL NULL 0 0
例 2 设置计划名称为 A1,并以结果集的方式显示如下语句的查询计划:
EXPLAIN AS A1 FOR SELECT NAME, SCHID FROM SYS.SYSOBJECTS WHERE SUBTYPE$='STAB';
查询结果如下:
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
1 6 A1 2022-12-14 13:55:55.000000 0 NSET2 NULL NULL
NULL NULL 65 100 1 0
0 NULL NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
2 6 A1 2022-12-14 13:55:55.000000 1 PRJT2 NULL NULL
NULL NULL 65 100 1 0
0 NULL NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
3 6 A1 2022-12-14 13:55:55.000000 2 SLCT2 NULL NULL
NULL NULL 65 100 1 0
0 SYSOBJECTS.SUBTYPE$ = 'STAB' NULL NULL 0 0
行号 PLAN_ID PLAN_NAME CREATE_TIME LEVEL_ID OPERATION TAB_NAME IDX_NAME
---------- ----------- --------- -------------------------- ----------- --------- ---------- ------------------
SCAN_TYPE SCAN_RANGE ROW_NUMS BYTES COST CPU_COST
--------- ---------- -------------------- ----------- -------------------- --------------------
IO_COST FILTER JOIN_COND ADVICE_INFO PSTART PSTOP
-------------------- ---------------------------- --------- ----------- ----------- -----------
4 6 A1 2022-12-14 13:55:55.000000 3 CSCN2 SYSOBJECTS SYSINDEXSYSOBJECTS
NULL NULL 1103 100 1 0
0 NULL NULL NULL 0 0
4.20 SAMPLE 子句
DM 通过 SAMPLE 子句实现数据采样功能。
语法格式
<SAMPLE子句>::=SAMPLE (<表达式>) |
SAMPLE (<表达式>) SEED (<表达式>) |
SAMPLE BLOCK (<表达式>) |
SAMPLE BLOCK (<表达式>) SEED (<表达式>)
参数
- <表达式> 输入整数与小数均可;
- SAMPLE (<表达式>) 按行采样。<表达式>表示采样百分比,取值范围[0.000001,100)。重复执行相同语句,返回的结果不要求一致;
- SAMPLE (<表达式>) SEED (<表达式>) 按行采样,并指定种子。其中 SEED(<表达式>)表示种子,取值范围 0~4294967295。重复执行相同的语句,每次返回相同的结果集;但在并行环境下,结果并不可控,即使重复执行相同的语句,也不一定返回相同的结果集;
- SAMPLE BLOCK (<表达式>) 按块(页)采样。<表达式>表示采样百分比,取值范围[0.000001,100)。重复执行相同语句,返回的结果不要求一致,允许返回空集;
- SAMPLE BLOCK (<表达式>) SEED (<表达式>) 按块(页)采样,并指定种子。其中,BLOCK (<表达式>)表示采样百分比,取值范围[0.000001,100)。SEED (<表达式>)表示种子,取值范围 0~4294967295。重复执行相同语句,每次返回相同的结果集。
使用说明
- SAMPLE 只能出现在单表、仅包含单表的视图或仅包含单表的非递归公用表表达式后面;
- 包含过滤条件的 SAMPLE 查询,是对采样后的数据再进行过滤;
- 不能对连接查询、子查询使用 SAMPLE 子句。
举例说明
例 对 PERSON.ADDRESS 表按行进行种子为 5 的 10% 采样。
SELECT * FROM PERSON.ADDRESS SAMPLE(10) SEED(5);
查询结果如下:
ADDRESSID ADDRESS1 ADDRESS2 CITY POSTALCODE
----------- ----------------------------- -------- ------------------ ----------
14 洪山区关山春晓10-1-202 武汉市洪山区 430073
4.21 水平分区表查询
SELECT 语句从水平分区子表中检索数据,称水平分区子表查询,即<对象名>中使用的是<分区表>。水平分区父表的查询方式和普通表完全一样。
<分区表>::=
[<模式名>.]<基表名> PARTITION (<一级分区名>) |
[<模式名>.]<基表名> PARTITION FOR (<表达式>,{<表达式>})|
[<模式名>.]<基表名> SUBPARTITION (<子分区名>)|
[<模式名>.]<基表名> SUBPARTITION FOR (<表达式>,{<表达式>})
参数
- <基表名> 水平分区表父表名称;
- <一级分区名> 水平分区表一级分区的名字;
- < 子分区名> 由水平分区表中多级分区名字逐级通过下划线“_”连接在一起的组合名称,例如 P1_P2_P3,其中 P1 是一级分区名、P2 是二级分区名、P3 是三级分区名。需要注意的是,直接使用二级分区名也能进行查询,并且如果多个一级分区中包括相同的二级分区名,该方式默认查询按定义排序在最前的一级分区下的二级分区;
- < 表达式 > 分区中的数据值,系统将根据数据值自动定位分区。
使用说明
如果 HASH 分区不指定分区表名,而是通过指定哈希分区个数来建立哈希分区表,PARTITIONS 后的数字表示哈希分区的分区数,使用这种方式建立的哈希分区表分区名是匿名的,DM 统一使用 DMHASHPART+ 分区号(从 0 开始)作为分区名。
举例说明
例 1 查询一个 LIST-RANGE 三级水平分区表。
建表并插入数据:
DROP TABLE STUDENT;
CREATE TABLE STUDENT(
NAME VARCHAR(20),
AGE INT,
SEX VARCHAR(10) CHECK (SEX IN ('MALE','FEMALE')),
GRADE INT CHECK (GRADE IN (7,8,9))
)
PARTITION BY LIST(GRADE)
SUBPARTITION BY LIST(SEX) SUBPARTITION TEMPLATE
(
SUBPARTITION Q1 VALUES('MALE'),
SUBPARTITION Q2 VALUES('FEMALE')
),
SUBPARTITION BY RANGE(AGE) SUBPARTITION TEMPLATE
(
SUBPARTITION R1 VALUES LESS THAN (12),
SUBPARTITION R2 VALUES LESS THAN (15),
SUBPARTITION R3 VALUES LESS THAN (MAXVALUE)
)
(
PARTITION P1 VALUES (7),
PARTITION P2 VALUES (8),
PARTITION P3 VALUES (9)
);
INSERT INTO STUDENT(NAME, AGE, SEX, GRADE) VALUES ('李丽', 12, 'FEMALE', 7), ('郭艳', 15, 'FEMALE', 8), ('王刚', 11, 'MALE', 9), ('李勇', 16, 'MALE', 7), ('王菲', 13, 'FEMALE', 8), ('刘波', 11, 'MALE', 7);
执行以下查询语句:
SELECT * FROM STUDENT; //查询水平分区父表
执行结果如下:
行号 NAME AGE SEX GRADE
---------- ------ ----------- ------ -----------
1 李丽 12 FEMALE 7
2 刘波 11 MALE 7
3 李勇 16 MALE 7
4 王菲 13 FEMALE 8
5 郭艳 15 FEMALE 8
6 王刚 11 MALE 9
执行以下查询语句:
//以下两个查询语句执行结果相同
SELECT * FROM STUDENT PARTITION(P1); //通过指定分区名查询一级分区子表
SELECT * FROM STUDENT PARTITION FOR(7); //通过指定分区数据查询一级分区子表
执行结果如下:
行号 NAME AGE SEX GRADE
---------- ------ ----------- ------ -----------
1 李丽 12 FEMALE 7
2 刘波 11 MALE 7
3 李勇 16 MALE 7
执行以下查询语句:
//以下两个查询语句执行结果相同
SELECT * FROM STUDENT SUBPARTITION(P1_Q1); //通过指定分区名查询二级分区子表
SELECT * FROM STUDENT SUBPARTITION FOR(7, 'MALE'); //通过指定分区数据查询二级分区子表
执行结果如下:
行号 NAME AGE SEX GRADE
---------- ------ ----------- ---- -----------
1 刘波 11 MALE 7
2 李勇 16 MALE 7
执行以下查询语句:
//以下两个查询语句执行结果相同
SELECT * FROM STUDENT SUBPARTITION(P1_Q1_R1); //通过指定分区名查询三级分区子表
SELECT * FROM STUDENT SUBPARTITION FOR(7, 'MALE', 10); //通过指定分区数据查询三级分区子表
执行结果如下:
行号 NAME AGE SEX GRADE
---------- ------ ----------- ---- -----------
1 刘波 11 MALE 7
例 2 查询一个指定 HASH 分区名的水平分区表。
CREATE TABLESPACE TS1 DATAFILE 'TS1.DBF' SIZE 128;
CREATE TABLESPACE TS2 DATAFILE 'TS2.DBF' SIZE 128;
CREATE TABLESPACE TS3 DATAFILE 'TS3.DBF' SIZE 128;
CREATE TABLESPACE TS4 DATAFILE 'TS4.DBF' SIZE 128;
DROP TABLE CP_TABLE_HASH CASCADE;
CREATE TABLE CP_TABLE_HASH(
C1 INT,
C2 VARCHAR(256),
C3 DATETIME,
C4 BLOB
)
PARTITION BY HASH (C1)
SUBPARTITION BY HASH(C2)
SUBPARTITION TEMPLATE
(SUBPARTITION PAR1 STORAGE (ON MAIN),
SUBPARTITION PAR2 STORAGE (ON TS1),
SUBPARTITION PAR3 STORAGE (ON TS2),
SUBPARTITION PAR4)
(PARTITION PAR1 STORAGE (ON MAIN),
PARTITION PAR2 STORAGE (ON TS1),
PARTITION PAR3 STORAGE (ON TS2),
PARTITION PAR4)
STORAGE (ON TS4) ;
INSERT INTO CP_TABLE_HASH (C1, C2, C3, C4) VALUES (1 ,'NAME1', '2023-12-26', ''), (2 ,'NAME2', '2022-12-26', ''), (3 ,'NAME3', '2023-1-15', ''), (4 ,'NAME4', '2022-5-1', ''), (5 ,'NAME5', '2023-3-15', ''), (6 ,'NAME6', '2023-11-11', ''), (7 ,'NAME7', '2021-9-23', ''), (8 ,'NAME8', '2023-7-8', ''), (9 ,'NAME9', '2023-12-26', ''), (10 ,'NAME10', '2022-12-26', ''), (11 ,'NAME11', '2023-1-15', ''), (12 ,'NAME12', '2022-5-1', ''), (13 ,'NAME13', '2023-3-15', ''), (14 ,'NAME14', '2023-11-11', ''), (15 ,'NAME15', '2021-9-23', ''), (16 ,'NAME16', '2023-7-8', '');
执行以下查询语句:
SELECT * FROM CP_TABLE_HASH PARTITION(PAR1); //查询一级分区子表
执行结果如下:
行号 C1 C2 C3 C4
---------- ----------- ------ -------------------------- --
1 12 NAME12 2022-05-01 00:00:00.000000
2 16 NAME16 2023-07-08 00:00:00.000000
3 4 NAME4 2022-05-01 00:00:00.000000
4 8 NAME8 2023-07-08 00:00:00.000000
执行以下查询:
SELECT * FROM CP_TABLE_HASH SUBPARTITION(PAR1_PAR1); //查询二级分区子表
执行结果如下:
行号 C1 C2 C3 C4
---------- ----------- ------ -------------------------- --
1 12 NAME12 2022-05-01 00:00:00.000000
2 16 NAME16 2023-07-08 00:00:00.000000
例 3 查询一个指定 HASH 分区数的水平分区,查询 CP_TABLE_HASH01 第一个分区的数据。
DROP TABLE CP_TABLE_HASH01 CASCADE;
CREATE TABLE CP_TABLE_HASH(
C1 INT,
C2 VARCHAR(256),
C3 DATETIME,
C4 BLOB
)
PARTITION BY HASH (C1)
PARTITIONS 4 STORE IN (TS1, TS2, TS3, TS4);
INSERT INTO CP_TABLE_HASH (C1, C2, C3, C4) VALUES (1 ,'NAME1', '2023-12-26', ''), (2 ,'NAME2', '2022-12-26', ''), (3 ,'NAME3', '2023-1-15', ''), (4 ,'NAME4', '2022-5-1', ''), (5 ,'NAME5', '2023-3-15', ''), (6 ,'NAME6', '2023-11-11', ''), (7 ,'NAME7', '2021-9-23', ''), (8 ,'NAME8', '2023-7-8', ''), (9 ,'NAME9', '2023-12-26', ''), (10 ,'NAME10', '2022-12-26', ''), (11 ,'NAME11', '2023-1-15', ''), (12 ,'NAME12', '2022-5-1', ''), (13 ,'NAME13', '2023-3-15', ''), (14 ,'NAME14', '2023-11-11', ''), (15 ,'NAME15', '2021-9-23', ''), (16 ,'NAME16', '2023-7-8', '');
执行以下查询:
SELECT * FROM CP_TABLE_HASH PARTITION (DMHASHPART0); //查询一级分区子表
执行结果如下:
行号 C1 C2 C3 C4
---------- ----------- ------ -------------------------- --
1 4 NAME4 2022-05-01 00:00:00.000000
2 8 NAME8 2023-07-08 00:00:00.000000
3 12 NAME12 2022-05-01 00:00:00.000000
4 16 NAME16 2023-07-08 00:00:00.000000
4.22 指定索引查询
可在 SELECT 语句中使用指定的索引进行查询。
<索引>::=[<模式名>.]<基表名> INDEX <索引名>
参数
- < 模式名 > 被选择的表和视图所属的模式,缺省为当前模式;
- < 基表名 > 被选择数据的基表的名称;
- < 索引名 > 为查询指定的索引名称。
使用说明
如果不指定索引,系统会选择一个最优的索引进行查询;指定索引后,系统则会按照指定的索引进行查询。为了避免指定了不合适的索引,导致查询性能变差。建议用户在熟知索引的用法之后,再为查询指定索引。
举例说明
例 1 使用指定的索引 INDEX1 进行查询。此处如果没有指定索引,系统将会为本次查询自动选择最优的索引 INDEX2。
CREATE INDEX INDEX1 ON PERSON.ADDRESS(ADDRESS1);
CREATE INDEX INDEX2 ON PERSON.ADDRESS(ADDRESS2);
--使用指定的INDEX1
SQL> EXPLAIN SELECT CITY FROM PERSON.ADDRESS INDEX INDEX1 WHERE ADDRESS2='洪山区保利花园50号';
1 #NSET2: [1, 1, 108]
2 #PRJT2: [1, 1, 108]; exp_num(2), is_atom(FALSE); INFO_BITS(0); spl_info(NULL)
3 #SLCT2: [1, 1, 108]; ADDRESS.ADDRESS2 = '洪山区保利花园50号'; slct_pushdown(0); spl_info(NULL); flt_batch_exec(1)
4 #BLKUP2: [1, 16, 108]; INDEX1(ADDRESS); use_clu_addr(0)
5 #SSCN: [1, 16, 108]; INDEX1(ADDRESS); btr_scan(1); is_global(0)
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(ADDRESS.ADDRESS2 = '洪山区保利花园50号')
--未指定的情况下,系统自动选择最优的INDEX2
SQL> EXPLAIN SELECT CITY FROM PERSON.ADDRESS WHERE ADDRESS2='洪山区保利花园50号';
1 #NSET2: [1, 1, 108]
2 #PRJT2: [1, 1, 108]; EXP_NUM(2), IS_ATOM(FALSE); INFO_BITS(0); SPL_INFO(NULL)
3 #BLKUP2: [1, 1, 108]; INDEX2(ADDRESS); USE_CLU_ADDR(0)
4 #SSEK2: [1, 1, 108]; SCAN_TYPE(ASC), INDEX2(ADDRESS), SCAN_RANGE['洪山区保利花园50号','洪山区保利花园50号'], IS_GLOBAL(0)