本文档主要介绍 DM 数据守护的系统特性、基本概念、主要功能、各组成部件的详细介绍,以及如何搭建数据守护环境并使用等。
1 引言
DM 数据守护(Data Watch)是一种集成化的高可用、高性能数据库解决方案,是数据库异地容灾的首选方案。通过部署 DM 数据守护,可以在硬件故障(如磁盘损坏)、自然灾害(地震、火灾)等极端情况下,避免数据损坏、丢失,保障数据安全,并且可以快速恢复数据库服务,满足用户不间断提供数据库服务的要求。与常规的数据库备份(Backup)、还原(Restore)技术相比,数据守护可以更快地恢复数据库服务。随着数据规模不断增长,通过还原手段恢复数据,往往需要数个小时、甚至更长时间,而数据守护基本不受数据规模的影响,只需数秒时间就可以将备库切换为主库对外提供数据库服务。
DM 数据守护提供多种解决方案,可以配置成实时主备、MPP 主备、DMDSC 主备或读写分离集群,满足用户关于系统可用性、数据安全性、性能等方面的综合需求,有效降低总体投入,获得超值的投资回报。
实时主备由一个主库以及一个或者多个配置了实时(Realtime)归档的备库组成,其主要目的是保障数据库可用性,提高数据安全性。实时主备系统中,主库提供完整的数据库功能,备库提供只读服务。主库修改数据产生的 Redo 日志,通过实时归档机制,在写入联机 Redo 日志文件之前发送到备库,实时备库通过重演 Redo 日志与主库保持数据同步。当主库出现故障时,备库在将所有 Redo 日志重演结束后,就可以切换为主库对外提供数据库服务。
MPP 主备就是在 MPP 集群的基础上,为每一个 MPP 节点配置一套实时主备系统,这些实时主备系统一起构成了 MPP 主备系统。我们将一个 MPP 节点对应的主备系统称为一个数据守护组(Group),MPP 主备系统中各个数据守护组保持相对独立,当某个 MPP 主节点出现故障时,在其对应的数据守护组内挑选一个备库切换为主库后,就可以确保整个 MPP 集群的正常使用。
DMDSC 主备与单节点主备功能一致,DMDSC 主备支持 DMDSC 集群和单节点之间互为主备库,一般建议将 DMDSC 集群部署为主库,将单节点部署为备库。当 DMDSC 集群为主库时,DMDSC 集群控制节点收集所有节点的 Redo 日志发送到备库,备库严格按照各节点修改数据页的先后顺序重演 Redo 日志保持数据同步;当 DMDSC 集群为备库时,主库将 Redo 日志发送至 DMDSC 集群控制节点,DMDSC 集群控制节点重演 Redo 日志保持数据同步。
读写分离集群由一个主库以及一个或者多个配置了即时(Timely)归档或实时(Realtime)归档的备库组成,其主要目标是在保障数据库可用性基础上,实现读、写操作的自动分离,进一步提升数据库的业务支撑能力。读写分离集群通过配置事务一致模式保证主、备库数据一致性,并配合达梦数据库管理系统的各种接口(JDBC、DPI 等),将只读操作自动分流到备库,有效降低主库的负载,提升系统吞吐量。
2 概述
DM 数据守护(DM Data Watch)的实现原理非常简单:将主库(生产库)产生的 Redo 日志传输到备库,备库接收并重新应用 Redo 日志,从而实现备库与主库的数据同步。DM 数据守护的核心思想是监控数据库状态,获取主、备库数据同步情况,为 Redo 日志传输与重演过程中出现的各种异常情况提供一系列的解决方案。
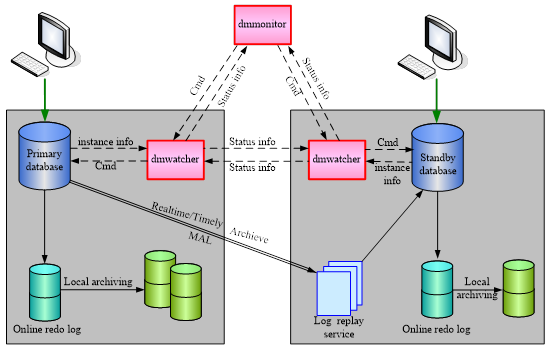
DM 数据守护系统结构参考图 2.1。主要由主库、备库、Redo 日志、Redo 日志传输、Redo 日志重演、守护进程(dmwatcher)、监视器(dmmonitor)组成。
数据库与数据库实例
数据库(Database)是一个文件集合(包括数据文件、临时文件、重做日志文件和控制文件),保存在物理磁盘或文件系统中。
数据库实例(Instance)就是一组操作系统进程(或者是一个多线程的进程)以及一些内存。通过数据库实例,可以操作数据库,一般情况下,我们访问、修改数据库都是通过数据库实例来完成的。
本文档将不再严格区分数据库和数据库实例的概念,很多地方会笼统的以库来代替。考虑到数据守护系统中,数据库实例名是唯一的,为了更准确地进行描述,很多情况下我们会以实例 xxx 来标记某一个主库或者备库。
主库
PRIMARY 模式,提供完整数据库服务的实例,一般来说主库是用来直接支撑应用系统的生产库。
备库
STANDBY 模式,提供只读数据库服务的实例。备库除了用于容灾,还可以提供备份、查询等只读功能,并且备库还支持临时表的 Insert/Delete/Update 操作。
备库支持临时表修改主要基于两个因素:1.临时表数据的修改不会产生 Redo 日志,主库对临时表的修改无法同步到备库;2.可以提供更大灵活性,适应更多应用场景。
根据数据同步情况,备库又可以分为可切换备库和不可切换备库。可切换备库是指,主备库之间数据完全同步,主库发生故障、备库切换为主库后,不会造成任何数据丢失的备库。
Redo 日志
Redo 日志记录物理数据页内容变动情况,是数据库十分重要的一个功能,在数据库系统故障(比如服务器掉电)重启时,利用 Redo 日志可以把数据恢复到故障前的状态。
Redo 日志也是数据守护的实现基础,数据库中 Insert、Delete、Update 等 DML 操作以及 Create TABLE 等 DDL 操作最终都会体现为对某一个或者多个物理数据页的修改,因此备库通过重做 Redo 日志可以与主库数据保持一致。
Redo 日志传输
主备库之间的 Redo 日志传输,以日志包 RLOG_PKG 为单位,主库通过 MAL 系统发送 Redo 日志到备库。各种不同数据守护类型的区别,就在于主库日志包 RLOG_PKG 的发送时机,以及备库收到 Redo 日志后的处理策略。
Redo 日志重演
Redo 日志重演的过程,就是备库收到主库发送的 Redo 日志后,在物理数据页上,重新修改数据的过程。Redo 日志重演由专门的 Redo 日志重演服务完成,重演服务严格按照 Redo 日志产生的先后顺序,解析 Redo 日志、修改相应的物理数据页,并且重演过程中备库会生成自身的 Redo 日志写入联机日志文件。
守护进程
守护进程(dmwatcher)是数据守护系统的核心工具,监控数据库实例的运行状态和主备库数据同步情况,在出现故障时启动各种处理预案。守护进程是各种消息的中转站,接收数据库实例、其他守护进程、以及监视器发送的各种消息;同时,守护进程也会将收到的数据库实例消息转发给其他守护进程和监视器。守护进程必须和被守护的数据库实例部署在同一台机器上。
监视器
监视器(dmmonitor)用来监控守护系统内守护进程、数据库实例信息,执行用户输入命令、监控实例故障、实现自动切换等。监视器一般配置在数据库实例和守护进程以外的机器上。
2.1 系统特性
2.1.1 主要特性
DM 数据守护的主要特性包括:
完整功能的主库
主库提供完整的数据库服务,与普通单节点数据库相比,主要的功能限制包括:不支持修改表空间文件名、不支持修改 arch_ini 参数。
活动的备库
基于独特的字典缓存技术和日志重演技术,备库在 Open 状态下执行数据同步,是真正意义上的热备库;在实现异地容灾的同时,用户可以只读访问备库,执行报表生成、数据备份等功能,减轻主库的系统负载,提高资源利用率。
多重数据保护
每个备库都是一个完整的数据库备份,可以同时配置多个备库,为数据安全提供全方位的保护。
高可用性
主库出现故障时,可以快速将备库切换为主库,继续提供数据库服务,确保数据库服务不中断。切换过程一般在数秒钟之内完成。
多种守护模式
提供自动切换和手动切换两种守护模式,满足用户不同需求。其中,配置自动切换的前提是已经部署确认监视器。在提供第三方机器部署确认监视器情况下,可以配置为故障自动切换模式,主库出现故障时,系统自动将备库切换为主库对外提供数据库服务。
多种守护类型
守护进程可以配置为全局守护(提供实时主备、MPP 主备、读写分离集群功能)或者本地守护,适应各种应用需求。
故障自动重连
配置、使用连接服务名访问数据库,在发生主备库切换后,接口会自动将连接迁移到新的主库上。
故障库自动重加入
主库故障,发生主备库切换。故障主库重启后,可以自动切换为 STANDBY 模式,作为备库重新加入数据守护系统。
历史数据自动同步
故障备库恢复后,可以自动同步历史数据,无需用户干预,并在同步完成以后,自动恢复为可切换备库。
自动负载均衡
配置读写分离集群,可以将只读操作分流到备库上执行,减轻主库访问压力,提高数据库系统的吞吐量。读写分离的过程由 JDBC 等接口配合服务器自动完成,无需用户干预,也不需要修改应用程序。
滚动升级
可以在不中断数据库服务的情况下,滚动地对数据守护系统中的主备库进行数据库软件版本升级。
灵活的搭建方式
可以在不中断数据库服务的情况下,将单节点数据库升级为主备系统。DM 提供多种工具来完成数据守护搭建,如 SHELL 脚本或 DEM 工具,均能方便地完成数据守护搭建。
完备的监控工具
通过命令行监控工具 dmmonitor、DEM 工具可以实时更新、监控主备库的状态和数据同步情况。
完善的监控接口
提供完善的数据守护监控接口,可以定制监控项,并方便地集成到应用系统中。
丰富的守护命令
提供主备库切换、强制接管等功能,通过简单的命令就可以实现主备库角色互换、故障接管等功能。
支持 DMDSC 守护
支持 DMDSC 和单节点、单节点和 DMDSC 之间互为主备的数据守护环境。
注意DM的单节点和主库提供读未提交(Read Uncommitted)、读提交(Read Committed)和串行化(Seriablizable)三种事务隔离级,可重复读(Repeatable Read)升级为更严格的串行化事务隔离级。备库在配置为串行重演时支持读提交事务隔离级,开启并行重演时,则仅支持读未提交事务隔离级。具体说明参考6.24备库查询限制说明。
2.1.2 主要改进(V2.0 版本)
与 DM 数据守护 V1.0 版本相比,DM 数据守护 V2.0 版本的主要改进包括:
1.检测并处理组分裂
检测并处理组分裂场景,是 DM 数据守护 V2.0 的一个重大改进。在 V1.0 版本中,主备库之间的数据一致性完全由用户保证,备库强制接管后,没有办法检查重新恢复的主库是否可以作为备库重新加入主备系统。V2.0 版本引入控制文件 dmwatcher.ctl,将备库接管时的相关信息记录在守护进程控制文件 dmwatcher.ctl 中,故障主库恢复后,根据 dmwatcher.ctl 控制文件中信息来判断是否满足故障重加入条件。
2.支持 TCP 协议,取消 UDP 协议
数据库实例与守护进程、守护进程与守护进程、以及守护进程与监视器之间的信息传递,都是基于 TCP 协议完成的。相比于采用 UDP 协议的 DM 数据守护系统 V1.0 版本,使用 TCP 协议的 V2.0 版本,具有以下优势:
- 支持跨网段部署数据守护系统,降低部署的硬件要求;
- 支持在一台物理机器上搭建数据守护系统,方便测试环境搭建;
- 更加简化、统一的配置文件和配置参数。
3.实时主备/MPP 主备/读写分离集群均支持故障自动切换
数据守护系统配置为自动切换模式,主库故障时,备库可以自动切换为主库,这个过程叫作故障自动切换。在 V1.0 版本中,只有实时主备支持故障自动切换,在 V2.0 版本中,MPP 主备和读写分离集群也支持故障自动切换。
4.可配置、可中断的备库恢复流程
缺省情况下,备库故障重启后,系统会自动进行检测、并启动恢复流程(同步历史数据)。某些情况下,用户可能需要对备库进行一些系统维护,并不希望备库启动后马上进行数据同步。V2.0 版本提供了备库维护功能,可以通过监视器命令将备库恢复功能暂时屏蔽。
当备库长时间中断后恢复,主备库之间数据差异很大情况下,同步历史数据可能需要很长一段时间。在这个过程中,如果出现新的故障场景需要处理,或者在监视器上执行其他命令,则允许中断当前的恢复流程,待故障处理(用户命令)执行完成后,再次启动恢复流程。
5.完善异步备库配置
异步备库一般用于历史数据统计、周期报表等对数据实时性要求不高的业务场合。异步归档时机一般选择在源库相对空闲的时候,以避免影响源库的性能。
V1.0 版本只支持在主库上配置异步备库,而 V2.0 版本则可以在主库或备库上配置各自的异步备库,提供了更大的灵活性,可以适应更广泛的应用场景。
6.任意场景支持强制接管,避免繁琐的手工 SQL 干预
实时主备/MPP 主备/读写分离三种类型全部实现了强制接管命令。
在 V1.0 版本中,实时守护没有监视器命令,需要手工执行一系列 SQL 语句完成强制接管,比较繁琐;读写分离集群和 MPP 主备提供了强制接管命令,但使用场景受限,比如待接管备库处于 MOUNT 状态的情况下,无法通过强制接管命令将备库切换为主库。并且强制接管后,用户无法判断主备库数据是否一致,存在较大的数据安全隐患。
在 V2.0 版本中,实时主备/MPP 主备/读写分离集群都支持强制接管命令,并且根据守护进程控制文件信息,可以判断强制接管后,是否产生组分裂,主备库数据是否可以恢复到一致状态。
7.配置参数调整,风格统一、步骤简化。提供多种搭建数据守护的自动化工具
在 V1.0 版本中,实时主备、MPP 主备和读写分离集群,各自有一套配置参数。在 V2.0 版本中,将三类守护系统统一为一套配置参数,并且简化掉一部分配置,大大提高了数据守护系统的搭建效率。
在 V2.0 版本中,除了支持手动搭建数据守护系统,DM 还提供多种自动化工具来完成数据守护搭建过程,如 SHELL 脚本、DEM 工具均能简便灵活地完成数据守护系统的搭建。
2.1.3 主要改进(V2.1 版本)
DM 数据守护 V2.1 版本在 V2.0 的基础上,主要改进包括:
1.统一 MARCH 和 REALTIME 归档实现逻辑
取消 MARCH 归档类型,保留 REALTIME 实时归档类型,MPP 主备和实时主备统一配置 REALTIME 归档。
2.实时主备功能扩展
扩展实时主备的备库数量,允许最多配置 8 个实时备库(V2.0 只支持配置一个实时备库);实时主备增加 HUGE 表数据同步支持。
3.优化 Redo 日志重演性能
采用全新的预解析、预加载技术,大幅优化备库 Redo 日志重演性能,解决了高并发、高压力情况下,备库 Redo 日志堆积问题。
提高了极端情况下集群的整体性能,缩短了极端情况下的故障切换时间。读写分离集群在事务一致性模式下,主库需要等待备库 Redo 日志重演完成再响应用户,优化以后有效降低了主库延迟,提升了读写分离集群系统的吞吐量。
4.对备库进行实时的异常监控和异常恢复
主库守护进程可以实时监控主备之间的数据同步和备库的日志重演情况,一旦出现网络异常或备库自身软硬件异常(比如备库磁盘读写速度异常降低)等原因造成备库无法及时响应主库的情况时,主库守护进程可通知主库将此备库归档失效,暂停到此备库的数据同步,避免拖慢主库性能。
主库会根据配置的恢复间隔定时向异常备库同步数据,如果检测到归档发送速度和备库的重演速度恢复正常,则将其归档重新恢复有效,恢复正常的数据同步。
5.简化、统一守护进程配置参数
取消 dmwatcher.ini 中的 MARCH/REALTIME/TIMELY 类型配置,数据守护类型由服务器的类型(比如:是否 MPP 集群)、以及其配置的归档类型来决定。
守护进程可以配置为 GLOBAL、LOCAL 两种类型,表示是否需要进行全局信息同步、以及是否参与集群管理。
2.1.4 兼容性说明(V2.1 版本)
升级到 V2.1 版本后,数据守护可以继续使用 V2.0 的配置文件,不需要任何修改。守护进程 dmwatcher 可以读写、并正确解析 V2.0 版本的 dmwatcher.ini 配置文件。但 V2.0 版本无法解析 V2.1 版本的配置文件。数据库服务器 DMServer 可以正确解析以前版本的归档配置,自动将 MARCH 归档转换成 REALTIME 归档进行处理。
但是,V2.1 版本与 V2.0 版本的 MPP 主备配置存在一定差异,从 V2.0 升级到 V2.1 版本后,需要修改备库的 dm.ini 配置文件,将 MPP_INI 配置项设置为 1,并从主库拷贝 MPP 控制文件 dmmpp.ctl 保存到 ctl_path 目录。否则,数据守护升级到 V2.1 版本后,MPP 主备系统将无法正常运行。
2.1.5 主要改进(V3.0 版本)
DM 数据守护 V3.0 版本在 V2.1 的基础上,主要改进包括:
1. 支持数据共享集群的守护系统
支持数据共享集群(DMDSC)的守护系统,DMDSC(主)和单节点(备)、单节点(主)和 DMDSC(备)之间都可以组成互为主备的数据守护系统。
2. DMDSC 集群守护增加 REMOTE 远程归档
用于 DMDSC 库的恢复以及主备库的异步恢复,发送日志时能够直接在本地访问到其他节点的归档日志。
3. 完善日志校验方式
主备库日志连续性校验方式,单节点日志的 LSN 值是连续递增的,日志 LSN 值都是唯一的(PWR 日志除外),如果把 DMDSC 集群作为一个整体看待,日志的 LSN 值也是连续递增的,但各个节点日志的 LSN 可能存在重复,每个节点的日志 LSN 是递增的但不一定是连续的。因此,DMDSC 主备库之间的日志校验更加复杂,新版本结合物理日志进行校验。
4. 引入适用于 DMDSC 主库的重演 APPLY_LSN 机制
如果主库是 DMDSC 集群,则需要发送所有节点的日志到备库的重演节点进行重演(如果备库是 DMDSC 集群,则重演节点是指备库的控制节点),在主备库需要同步历史数据时(比如备库故障重启),主库需要知道自己的每个节点在备库上的重演情况,以决定每个节点分别从哪里开始同步数据。备库记录 DMDSC 主库各个节点日志重做情况的 LSN,称为 APPLY_LSN。主库是单节点时,备库的 APPLY_LSN 等同于 CUR_LSN。
5. 守护进程以库为单位管理 DMDSC 集群
守护进程以库为单位进行管理,对 DMDSC 集群是指包含有多个节点的库,对单节点则是只有一个节点的库,并新增若干状态进行 DMDSC 集群的管理。
6. 守护进程可以处理 DMDSC 主库或备库的重加入
控制文件 dmwatcher.ctl 改造,结合备库的重演 LSN 概念,将之前的 SLSN 字段变成重演 APPLY_LSN 数组,同时调整判断主备库是否可加入的逻辑。
7. 备库可执行创建、扩展日志文件
允许备库执行创建、扩展日志文件,备库不再重演主库创建、扩展日志文件产生的日志。
8. 监视器支持对 DMDSC 集群的监控和管理
监视器调整及扩展一批命令及接口,以适应 DMDSC 集群的监控及管理。
2.1.6 兼容性说明(V3.0 版本)
从 V2.0 或者 V2.1 升级到 V3.0 版本后,如果守护系统中不扩展新增 DMDSC 库,仍然是只包含单节点的数据守护环境,则可以继续使用原来的配置文件,不需要任何修改。守护进程可以正确读写 dmwatcher.ctl 文件及其配置文件,数据库服务器和监视器也都可以正确读取版本升级前的配置文件,但是 V2.0 或 V2.1 无法正确解析 V3.0 的配置文件。
升级成 V3.0 版本后,为保持格式兼容,守护进程仍然是按照老的版本格式读写 dmwatcher.ctl 文件的,如果在升级后的守护系统中要扩展新增 DMDSC 库,则要按照 V3.0 版本的配置要求重新修改相关的 ini 配置文件,并且要重新生成新版本的 dmwatcher.ctl 文件。
另外如果是从 V2.0 直接升级到 V3.0,在 MPP 主备的配置上存在一定差异,从 V2.0 升级到 V3.0 版本后,需要修改备库的 dm.ini 配置文件,将 MPP_INI 配置项设置为 1,并从主库拷贝 MPP 控制文件 dmmpp.ctl 保存到 ctl_path 目录。否则,数据守护升级到 V3.0 版本后,MPP 主备系统将无法正常运行。
2.1.7 主要改进(V4.0 版本)
DM 数据守护 V4.0 版本在 V3.0 的基础上,主要改进包括:
1. 主备库以 RLOG_PKG 为单位同步数据
数据守护 V4.0 在 RLOG_PKG 改造基础上重新实现,主库产生的 Redo 日志以 RLOG_PKG 包的形式发送给备库重演。RLOG_PKG 具有自描述、自校验特征,数据的组织形式更加灵活、高效,支持 HUGE 表操作产生 Redo 日志,并且支持以 RLOG_PKG 为单位进行日志加密和压缩。
2. 备库完整归档主库产生的日志
备库在收到主库发送过来的 RLOG_PKG 后,直接将 RLOG_PKG 写入本地的归档日志文件,完整保留主库上的原始日志,备库重演 RLOG_PKG 产生的联机日志不再进行归档。
采用这种备库归档策略后,不管主备库如何切换,集群中所有数据库的归档日志内容是完全一致的,简化了历史数据同步处理逻辑。
3. 更简便的日志连续性校验
由于 RLOG_PKG 包具有自校验特性,利用 RLOG_PKG 的 G_PKG_SEQNO 和 MIN_LSN、MAX_LSN、PREV_LSN 等信息,结合备库重演信息(APPLY STAT)记录的 P_DB_MAGIC、N_APPLY_EP、PKG_SEQNO_ARR 数组、APPLY_LSN_ARR 数组,可以准确地校验出日志是否连续。简化了主备库(特别是 DSC 主备库)日志连续性校验逻辑,主库只负责发送日志,备库根据接收到的日志和自己维护的重演信息校验日志是否连续。
4. 更可靠的主库变迁记录
增加 SYSOPENHISTORY 系统表,记录数据库的 Open 历史记录,在 PRIMARY 或 Normal 模式库 Open 时,向系统表写入记录(称之为 Open 记录)。主库切换、Open 等过程完整地记录在数据库中,并通过 Redo 日志传送到备库,完成主备库之间 Open 记录的同步。
简化 dmwatcher.ctl 功能,取消 Open 记录,仅保留 status 和 desc 两个字段,在本地数据库分裂时,设置分裂状态和对应的分裂描述信息。并且,dmwatcher.ctl 文件不再需要在主备库之间进行同步。
5. 更完备的库分裂检测机制
优化了主备库分裂场景判断逻辑,守护进程根据主备库 Open 记录的包含关系、主库各节点 LSN 信息和备库日志重演信息,判断是否出现主备库分裂。在未出现分裂情况下,综合考虑各数据库模式、状态要素,选择正确的主库并进行自动 Open 数据库。
6. 更完善的异步备库功能
异步备库支持多源配置,允许 Realtime、Timely 主备库配置相同的异步备库,系统自动识别,仅从主库向异步备库同步历史数据。不管主备库如何切换,始终保持异步备库与主库的数据同步。
2.1.8 兼容性说明(V4.0 版本)
系统自动识别 dmwatcher.ctl 控制文件的版本号,忽略老版本控制文件。在数据库分裂时,自动覆盖并生成新格式的 dmwatcher.ctl 文件。
1. 从 V2.1 或者 V3.0 升级到 V4.0
如果守护系统不再扩展配置其他库(单节点或者 DSC 集群),则可以继续使用原来的配置文件,不需要做任何修改。同时,建议删除主备库各自目录下的 dmwatcher.ctl 文件。
2. 从 V2.0 升级到 V4.0
如果守护系统不再扩展配置其他库(单节点或者 DSC 集群),对实时主备和读写分离集群,则可以继续使用原来的配置文件,不需要做任何修改。同时,建议删除主备库各自目录下的 dmwatcher.ctl 文件。
MPP 主备还需要修改备库的 dm.ini 配置文件,将 MPP_INI 配置项设置为 1,并从主库拷贝 MPP 控制文件 dmmpp.ctl 保存到 ctl_path 目录。否则,数据守护升级到 V4.0 版本后,MPP 主备系统将无法正常运行。
3. 数据库升级说明
由于 V4.0 的数据库 REDO 日志采用 RLOG_PKG 为单位在日志文件中进行保存,和 RLOG_BUF 机制的格式不兼容,V4.0 版本无法解析老库日志。为了避免库启动时进行重做 REDO 日志、归档文件修复等动作而导致无法升级的情况发生,因此要求升级前的库必须是使用之前版本的服务器执行码正常退出的库,否则无法自动升级。
数据库自动升级的动作包括:根据当前库信息,初始化联机日志文件头、创建一个初始的日志包格式化到文件中、创建 SYSOPENHISTORY 系统表等。
由于升级后老的归档文件无法再继续使用,因此需要确保备库在升级前和主库的数据处于一致状态,否则升级完成后,主库无法再从老的归档文件中收集数据同步到备库上。
注意以上描述仅为升级的简单说明,具体的降级操作请咨询达梦技术服务人员。
4. 数据库降级说明
对数据守护 V4.0 环境,支持将主库重新降级到 V3.0 版本(仅支持降级到 V8.1.0.182 版本),备库不支持直接降级。
由于 REDO 日志格式降级前后是不兼容的,为了避免降级后的数据库启动时进行重做 REDO 日志、归档文件修复等动作导致无法正常启动的情况发生,因此要求降级前的库必须是使用之前版本的服务器执行码正常退出的库,否则不允许执行降级。
数据库降级的动作包括:按照 V3.0 的格式降级联机日志文件头、降级数据字典版本号、删除 SYSOPENHISTORY 系统表、按照老的视图定义重建一批动态视图等。
注意以上描述仅为降级的简单说明,具体的降级操作请咨询达梦技术服务人员。
2.2 基本概念
在介绍数据守护主要功能之前,我们先熟悉几个基本概念,只有充分理解这些概念,才能更加深入地理解数据守护。
2.2.1 数据库
数据守护以库为单位进行管理,一个 DMDSC 集群的所有实例作为一个整体库来考虑。DMDSC 集群的库信息,例如库的状态、模式等需要综合考虑集群内所有实例,同时需要结合 DMDSC 本身的状态。
2.2.2 DMDSC 状态
DMDSC 状态标识 DMDSC 集群节点状态,和数据库的状态不同。包括以下几种:
- Startup 节点启动状态,需要通过 DMCSS 工具交互,确定控制节点,执行日志重做等相关步骤,进入到 OPEN 状态。
- Open 实例正常工作状态,当集群内发生节点故障或启动节点重加入步骤时,可以进入 crash_recv 或者 err_ep_add 状态,处理完成后会再回到 Open 状态。
- Crash_recv 节点故障处理状态。
- Err_ep_add 故障节点重加入状态。
2.2.3 数据库模式
DM 支持 3 种数据库模式:Normal 模式、PRIMARY 模式和 STANDBY 模式。
Normal 模式
提供正常的数据库服务,操作没有限制。
PRIMARY 模式
提供正常的数据库服务,操作有极少限制,例如:不支持修改表空间文件名、不支持修改 arch_ini 参数。Primary 模式下,对临时表空间以外的所有的数据库对象的修改操作都强制生成 Redo 日志。
STANDBY 模式
可以执行数据库联机备份、查询等只读数据库操作。该模式下时间触发器、事件触发器等都失效。主备库各自维护临时表空间,可以直接连接备库修改临时表空间文件大小。
可以通过 SQL 语句切换数据库模式,模式切换在 Mount 状态下可以直接执行,在 Open 状态下需要加 FORCE 关键字强制执行。切换模式 SQL 语句如下:
在 Mount 状态下,切换数据库模式。
ALTER DATABASE PRIMARY;
ALTER DATABASE STANDBY;
ALTER DATABASE NORMAL;
在 Open 状态下,切换数据库模式。
ALTER DATABASE PRIMARY FORCE;
ALTER DATABASE STANDBY FORCE;
ALTER DATABASE NORMAL FORCE;
注意1. OPEN状态下的模式切换仅在单机和DSC环境下有效。
2. 修改DMDSC库的模式必须在DMDSC库所有实例都处于Mount状态或者所有实例都处于Open状态下才能进行,只需要在一个节点上执行以上语句即可,如果在Open状态下执行则需要加FORCE关键字。
2.2.4 数据库状态
DM 的数据库状态包括:
Startup 状态
数据库刚启动时为 Startup 状态。
After Redo 状态
数据库启动过程中联机日志重做完成后,回滚活动事务前为 After Redo 状态。非 STANDBY 模式的数据库在将系统设置为 Open 状态前,也会先将系统设置为 After Redo 状态。
Open 状态
数据库在 Open 状态下,不能进行控制文件维护、归档配置(不包括增加/删除同步归档)等操作,可以访问数据库对象以及增加/删除同步归档,对外提供正常的数据库服务。
Mount 状态
数据库在 Mount 状态下,不能修改数据,不能访问表、视图等数据库对象,但可以执行修改归档配置、控制文件和修改数据库模式等操作,也可以执行一些不修改数据库内容的操作,比如查询动态视图或者一些只读的系统过程。由于 Mount 状态不生成 PWR 日志,因此数据页可以正常刷盘,也正常推进检查点。
系统从 Open 状态切换为 Mount 状态时,会强制回滚所有活动事务,但不会强制清理(Purge)已提交事务,不会强制断开用户连接,也不会强制 Buffer 中的脏页刷盘。
Suspend 状态
数据库在 Suspend 状态下,可以访问数据库对象,甚至可以修改数据,但限制 Redo 日志刷盘,一旦执行 COMMIT 等触发 Redo 日志刷盘的操作时,当前操作将被挂起。
相比 Open 到 Mount 的状态切换,Open 到 Suspend 的状态切换更加简单、高效,不会回滚任何活动事务,在状态切换完成后,所有事务可以继续执行。
一般在修改归档状态之前将系统切换为 Suspend 状态,比如备库故障恢复后,在历史数据(归档日志)同步完成后,需要重新启用实时归档功能时:
- 将系统切换为 Suspend 状态,限制 Redo 日志写入联机 Redo 日志文件;
- 修改归档状态为 Valid;
- 重新将数据库切换为 Open 状态,恢复 Redo 日志写入功能;
- 备库与主库重新进入实时同步状态。
另外,实时归档失败时(比如网络故障导致),PRIMARY 实例将试图切换成 Suspend 状态,防止后续的日志写入。因为一旦写入,主备切换时有可能备库没有收到最后那次的 RLOG_PKG,导致主库上多一段日志,很容易造成主备数据不一致。当实例成功切换为 SUSPEND 状态时,可直接退出,强制丢弃多余的日志,避免主备数据不一致。
注意修改DMDSC库的状态为SUSPEND时,库内所有实例都不能处于MOUNT状态,只需要在一个节点上执行ALTER DATABASE SUSPEND语句即可。
Shutdown 状态
数据库正常关闭时为 Shutdown 状态。
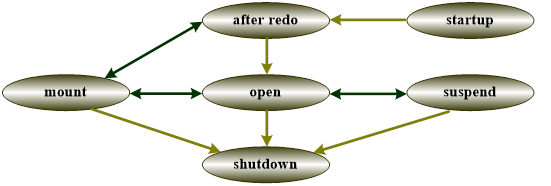
不同数据库状态之间的转换规则如图 2.2 所示。用户可以通过 SQL 语句进行数据库状态切换:1. Open 状态与 Mount 状态可以相互切换;2. Open 状态与 Suspend 状态可以相互切换;3. Mount 和 Suspend 状态不能直接转换;4. 其他状态为系统内部状态,用户不能主动干预。
注意对DMDSC集群,除了修改Suspend是同步操作,只需要在一个节点执行外,其他状态修改都需要在每个节点上各自单独执行。
切换数据库状态的 SQL 如下:
- 将数据库修改为 Open 状态。当系统处于 PRIMARY/STANDBY 模式时,必须强制加上 FORCE 子句。
ALTER DATABASE OPEN [FORCE];
- 将数据库修改为 Mount 状态。
ALTER DATABASE MOUNT;
- 将数据库修改为 Suspend 状态。
ALTER DATABASE SUSPEND;
注意由于dmwatcher根据数据库模式、状态等信息作为故障处理、故障恢复的依据,建议在配置数据守护过程中,修改dm.ini参数ALTER_MODE_STATUS为0,限制用户直接通过SQL语句修改数据库状态、模式以及OGUID,避免dmwatcher做出错误的决策。
2.2.5 LSN 介绍
LSN(Log Sequence Number)是由系统自动维护的 Bigint 类型数值,具有自动递增、全局唯一特性,每一个 LSN 值代表着 DM 系统内部产生的一个物理事务。物理事务(Physical Transaction,简称 ptx)是数据库内部一系列修改物理数据页操作的集合,与数据库管理系统中事务(Transaction)概念相对应,具有原子性、有序性、无法撤销等特性。
DM 数据库中与 LSN 相关的信息,可以通过查询 vrlog和VRAPPLY_PARALLEL_INFO 表来获取。DM 主要包括以下几种类型的 LSN:
● CUR_LSN 是系统已经分配的最大 LSN 值。物理事务提交时,系统会为其分配一个唯一的 LSN 值,大小等于 CUR_LSN + 1,然后再修改 CUR_LSN=CUR_LSN+1。
● FILE_LSN 是已经写入联机 Redo 日志文件的日志包的最大 LSN 值。每次将 Redo 日志包 RLOG_PKG 写入联机 Redo 日志文件后,都要修改 FILE_LSN 值。
● FLUSH_LSN 是已经发起日志刷盘请求,但还没有真正写入联机 Redo 日志文件的最大 LSN 值。
● CKPT_LSN 是检查点 LSN,所有 LSN <= CKPT_LSN 的物理事务修改的数据页,都已经从数据缓冲区写入磁盘,CKPT_LSN 由检查点线程负责调整。
● APPLY_LSN 是备库已写入联机 Redo 日志文件的日志包的原始最大 LSN 值,此 LSN 取自主库对应的原始日志包中的最大 LSN 值。如果主库是 DMDSC 集群,备库分别为主库每一个节点维护一个 APPLY_LSN。
● RPKG_LSN 是备库重演 LSN,表示备库已经重演完成的最大 LSN。如果主库是 DMDSC 集群,备库分别为主库每一个节点维护一个 RPKG_LSN。
与上述 LSN 对应,DM 数据守护也定义了一批 LSN:
✔CLSN 与 CUR_LSN 保持一致,节点实例的系统当前 LSN。
● 对主库而言,此字段显示当前数据库最新产生的 LSN 值。
● 对备库而言,此字段显示准备重演刷盘的最新日志包的最大 LSN 值。
✔FLSN 与 FILE_LSN 保持一致,已写入联机日志文件的 LSN 值。
✔ALSN 与 APPLY_LSN 保持一致,备库已写入联机日志文件的原始 LSN 值。
✔RLSN 与 RPKG_LSN 保持一致,备库已经重演完成的最大 LSN 值。
✔SLSN 是 STANDBY LSN 的缩写,表示备库明确可重演的最大 LSN 值。
✔KLSN 是 Keep LSN 的缩写,表示备库已经收到、但未明确是否可以重演的 RLOG_PKG 的最大 LSN 值。在读写分离集群中 KLSN == SLSN。
2.2.6 Redo 日志
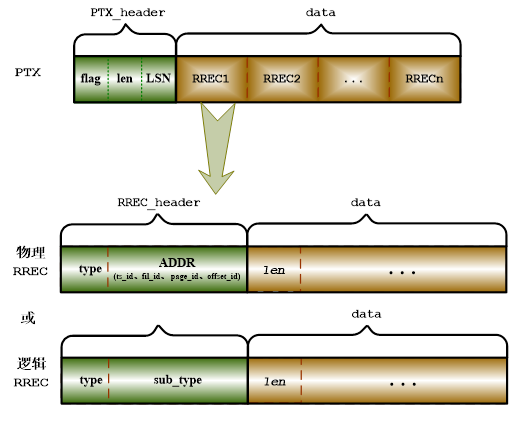
Redo 日志包含了所有物理数据页的修改内容,Insert/delete/update 等 DML 操作、Create Table 等 DDL 操作,最终都会转化为对物理数据页的修改,这些修改都会反映到 Redo 日志中。一般说来一条修改数据的 SQL 语句(比如 Insert),在系统内部会转化为多个相互独立的物理事务来完成,物理事务提交时会将产生的 Redo 日志写入日志包 RLOG_PKG 中。
一个物理事务包含一个或者多个 Redo 记录(Redo Record),每条 Redo 记录(RREC)都对应一个修改物理数据页的动作。根据记录内容的不同,RREC 可以分为两类:物理 RREC 和逻辑 RREC。
物理 RREC 记录的是数据页的变化情况,内容包括:操作类型、修改数据页地址、页内偏移、数据页上的修改内容,如果是变长类型的 Redo 记录,在 RREC 记录头之后还会有一个两字节的长度信息。
逻辑 RREC 记录的是一些数据库逻辑操作步骤,主要包括:事务启动、事务提交、事务回滚、字典封锁、事务封锁、B 树封锁、字典淘汰等。
逻辑 RREC 记录是专门为数据守护增加的记录类型,用来解决备库重演 Redo 日志与用户访问备库之间的并发冲突,以及主库执行 DDL 后导致的主备数据库字典缓存不一致问题。备库解析到逻辑 RREC 记录时,根据记录内容,生成相应的事务,封锁对应的数据库对象,并从字典缓存中淘汰过期的字典对象。
2.2.7 Redo 日志包(RLOG_PKG)
Redo 日志包(RLOG_PKG)是 DM 数据库批量保存物理事务产生的 Redo 日志的数据单元,以物理事务 PTX 为单位保存日志,一个日志包内可连续保存一个或多个 PTX。日志包具有自描述的特性,日志包大小不固定,采用固定包头和可变包头结合的方式,包头记录日志的控制信息,包括类型、长度、包序号、LSN 信息、产生日志的节点号、加密压缩信息、日志并行数等内容。
日志包生成时按照序号连续递增,相邻日志包的 LSN 顺序是总体递增的,但是在多节点集群的 DSC 环境下不一定连续。如果未开启并行日志,RLOG_PKG 包内日志的 LSN 是递增的。如果开启并行日志,一个 RLOG_PKG 包内包含多路并行产生的日志,每一路并行日志的 LSN 是递增的,但是各路之间并不能保证 LSN 有序,因此并行日志包内 LSN 具有局部有序,整体无序的特点。
物理事务提交时将 Redo 日志写入到日志包中,在数据库事务提交或日志包被写满时触发日志刷盘动作。日志刷盘线程负责将日志包中的 Redo 日志写入联机日志文件,如果配置了 Redo 日志归档,日志刷盘线程还将负责触发归档动作。DM 数据守护系统中,主库以 RLOG_PKG 为最小单位发送 Redo 日志到备库。
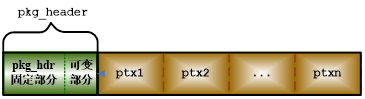
2.2.8 包序号介绍
每个 RLOG_PKG 都有对应的序号属性,称之为包序号(PKG SEQNO),日志包生成时按照序号连续递增。包序号包括本地包序号(LSEQ)和全局包序号(GSEQ),本地包序号是节点内唯一、连续递增的值,用于校验联机日志连续性;全局包序号由数据守护集群的主备库共同维护,具有全局唯一、连续、递增的特性,用于校验归档日志的连续性。
DM 数据库中与全局包序号相关的信息可以通过查询 v$rlog 表来获取,主要包括以下几种类型的全局包序号:
● CUR_SEQ 是系统已经分配的最大全局包序号。RLOG_PKG 写入联机日志文件前,系统会为其分配一个唯一的全局包序号。
● FILE_SEQ 是已经写入联机 Redo 日志文件的日志包的最大全局包序号。每次将 Redo 日志包 RLOG_PKG 写入联机 Redo 日志文件后,都要修改 FILE_SEQ 值。
● APPLY_SEQ 是备库已写入联机 Redo 日志文件的日志包的原始最大全局包序号,此序号取自主库对应的原始日志包的包序号。如果主库是 DSC 集群,备库分别为主库每一个节点维护一个 APPLY_SEQ。
● RPKG_SEQ 是备库重演全局包序号,表示备库已经重演完成的最大全局包序号。如果主库是 DSC 集群,备库分别为主库每一个节点维护一个 APPLY_SEQ。
DM 数据守护中也相应地定义了一批全局包序号:
✔ CSEQ 全局已分配包序号,标识系统已经分配的最大 GSEQ 值。
● 对主库而言,此字段显示当前数据库最新产生的 RLOG_PKG 包的序号。
● 对备库而言,CSEQ 与备库的 FSEQ 相同,与主库的 CSEQ 不一定相同。
✔ FSEQ 全局文件包序号,标识已写入联机日志文件的最大 GSEQ 值。
● 对主库而言,此字段显示节点实例已经写入联机日志的最新 RLOG_PKG 包序号。
● 对备库而言,非控制节点此字段保持不变;控制节点此字段显示为与备库控制节点号相同的主库节点产生的,已经写入联机日志的 RLOG_PKG 包序号。例如:备库控制节点号为 0,此字段值与主库 0 号节点的 FSEQ 同步变化;备库控制节点号为 1,此字段值与主库 1 号节点的 FSEQ 同步变化。
✔ ASEQ 原始全局文件包序号,标识备库已写入联机日志文件的原始 GSEQ 值。
✔ RSEQ 全局重演包序号,标识备库已经重演的最大 GSEQ 值。
✔ SSEQ 全局备库包序号,标识备库明确可重演的最大 GSEQ 值。
✔ KSEQ 全局保留包序号,表示备库已经收到、未明确是否可以重演的最大 GSEQ 值。在读写分离集群中 SSEQ == KSEQ。
GSEQ 和 LSN 存在匹配关系,在判断归档连续性、备库归档恢复等场合一般都是同时使用。
2.2.9 KEEP_RLOG_PKG 介绍
主库的 RLOG_PKG 日志通过实时归档机制发送到备库后,备库将最新收到的 RLOG_PKG 保存在内存中,不马上启动重演,这个 RLOG_PKG 我们称之为 KEEP_RLOG_PKG。引入 KEEP_RLOG_PKG 的主要目的是,避免下述场景中,主库故障重启后不必要的主备切换,减少用户干预。
场景说明(实时主备或 MPP 主备):
1.用户登录主库 A 执行
CREATE TABLE TX(C1 INT);
INSERT INTO TX VALUES(1);
COMMIT;
其中 COMMIT 操作将触发实时归档,发送 RLOG_PKG 到备库 B。
2.备库 B 收到 RLOG_PKG,响应主库 A,并启动日志重演。
3.主库 A 在 RLOG_PKG 写入联机日志文件之前故障。
4.主库 A 重新启动后,由于 RLOG_PKG 没有写入联机日志文件,之前插入 TX 表的数据丢失;但此时备库 B 已经重演日志成功,TX 表中已经插入一行数据。
上述场景中,主备库数据不再保持一致,必须将备库 B 切换为主库,并重新从 B 同步数据到 A。如果配置的是手动切换模式,则必须要有用户干预,进行备库接管后,才能恢复数据库服务。
引入 KEEP_RLOG_PKG 后,备库 B 收到主库 A 发送的 RLOG_PKG,并不会马上启动日志重演,主库 A 重启后,守护进程 A 检测到备库 B 存在 KEEP_RLOG_PKG,通知备库 B 丢弃 KEEP_RLOG_PKG 后,直接 Open 主库 A,就可以继续提供数据库服务。并且,这些操作是由守护进程自动完成,不需要用户干预。
如果备库自动接管、或者用户发起备库接管命令,那么备库的 KEEP_RLOG_PKG 将会启动重演,不管主库是否已经将 KEEP_RLOG_PKG 对应的 Redo 日志写入联机日志文件中,备库接管时的 APPLY_LSN 一定是大于等于主库的 FILE_LSN。当故障主库重启后,仍然可以作为备库,自动重新加入数据守护系统。
备库 KEEP_RLOG_PKG 日志重演的时机包括:
- 备库收到新的 RLOG_PKG
备库收到新的 RLOG_PKG 时,会将当前保存的 KEEP_RLOG_PKG 日志重演,并将新收到的 RLOG_PKG 再次放入 KEEP_RLOG_PKG 中。
- 收到主库的重演命令
主库会定时将 FILE_LSN 等信息发送到备库,当主库 FILE_LSN 等于备库 SLSN 时,表明主库已经将 KEEP_RLOG_PKG 对应的 Redo 日志写入联机日志文件中,此时备库会启动 KEEP_RLOG_PKG 的日志重演。
- 备库切换为新主库
在监视器执行 SWITCHOVER 或 TAKEOVER 命令,或者确认监视器通知备库自动接管时,备库会在切换为 PRIMARY 模式之前,启动 KEEP_RLOG_PKG 的日志重演。
注意即时归档在RLOG_PKG写入主库联机Redo日志文件后,再发送RLOG_PKG到备库,因此即时备库没有KEEP_RLOG_PKG。
2.2.10 联机 Redo 日志文件
DM 数据库默认包含两个联机 Redo 日志文件(如 DAMENG01.log、DAMENG02.log),系统内部分别称为 0 号文件、1 号文件。RLOG_PKG 顺序写入联机 Redo 日志文件中,当一个日志文件写满后,自动切换到另一个文件。其中 0 号文件是 Redo 日志主文件,在日志主文件头中保存了诸如 CKPT_LSN,CKPT_FILE,CKPT_OFFSET,FILE_LSN 等信息。系统故障重启时,从[CKPT_FILE, CKPT_OFFSET]位置开始读取 Redo 日志,解析 RREC 记录,并重新修改对应数据页内容,确保将数据恢复到系统故障前状态。
随着检查点(Checkpoint)的推进,对应产生 Redo 日志的数据页从数据缓冲区(Data Buffer)写入磁盘后,联机 Redo 日志文件可以覆盖重用、循环使用,确保 Redo 日志文件不会随着日志量的增加而增长。
注意任何数据页从数据缓冲区写入磁盘之前,必须确保修改数据页产生的Redo日志已经写入到联机Redo日志文件中。
下图说明了联机日志文件、日志包 RLOG_PKG 以及相关各 LSN 之间的关系。
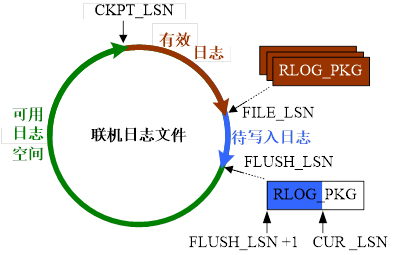
在联机日志文件中,可以覆盖写入 Redo 日志的文件长度为可用日志空间;不能被覆盖,系统故障重启需要重做部分,为有效 Redo 日志,有效 Redo 日志的 LSN 取值范围是(CKPT_LSN,FILE_LSN];已经被发起日志刷盘请求,但还没有真正写入联机 Redo 日志文件的区间为(FILE_LSN,FLUSH_LSN],称为待写入日志空间。
2.2.11 归档介绍
归档是实现数据守护系统的重要技术手段,根据功能与实现方式的不同,DM 数据库的归档可以分为 6 类:本地归档、远程归档、实时归档、即时归档、异步归档和同步归档。其中,本地归档日志的内容与写入时机与数据库模式相关;主库 Redo 日志写入联机日志文件后,再进行本地归档;备库收到主库产生的 Redo 日志后,直接进行本地归档,同时启动 Redo 日志重演。
2.2.11.1 本地归档
Redo 日志本地归档(Local),就是将 Redo 日志写入到本地归档日志文件的过程。配置本地归档情况下,Normal/PRIMARY 模式库在 Redo 日志写入联机 Redo 日志文件后,将对应的 RLOG_PKG 由专门的归档线程写入本地归档日志文件中。STANDBY 模式库收到主库产生的 Redo 日志后,直接进行本地归档,写入本地归档日志文件中,同时启动 Redo 日志重演。
Normal/PRIMARY 模式库归档日志文件保存的是当前节点产生的 Redo 日志,归档日志文件内容与联机日志内容保持一致。STANDBY 模式库重演日志重新产生的 Redo 日志只写入联机日志文件,归档日志文件保存主库产生的 Redo 日志,因此备库联机日志文件内容和归档日志文件内容是不完全一致的。采用这种归档实现方式后,可以确保数据守护系统中所有节点的归档日志文件内容是完全一致的。
与联机 Redo 日志文件可以被覆盖重用不同,本地归档日志文件不能被覆盖,写入其中的 Redo 日志信息会一直保留,直到用户主动删除;如果配置了归档日志空间上限,系统会自动删除最早生成的归档 Redo 日志文件,腾出空间。本地归档文件在配置的归档目录下生成并保存,如果磁盘空间不足,且没有配置归档日志空间上限(或者配置的上限超过实际空间),系统将自动挂起,直到用户主动释放出足够的空间后继续运行。
DM 提供了按指定的时间或指定的 LSN 删除归档日志的系统函数,分别为 SF_ARCHIVELOG_DELETE_BEFORE_TIME 和 SF_ARCHIVELOG_DELETE_BEFORE_LSN,但用户需要谨慎使用。例如,在守护系统中,如果备库故障了,主库继续服务,主库的日志在继续增长。此时如果删除尚未同步到备库的主库归档日志,那么备库重启之后,会由于备库收到的日志缺失导致主备库无法正常同步数据。
注意为了最大限度地保护数据,当磁盘空间不足导致归档写入失败时,系统会挂起等待,直到用户释放出足够的磁盘空间。当磁盘损坏导致归档日志写入失败时,系统会强制HALT。
2.2.11.2 远程归档
远程归档专门用于 DMDSC 环境中。
远程归档(REMOTE ARCHIVE)是将当前节点的远程归档目录配置为另一节点的本地归档目录,以此来共享它的本地归档日志文件。其中,另一节点的本地归档目录必须位于 ASM 共享存储或其他共享磁盘上,以使当前节点可以成功访问。
远程归档采用双向配置的方式,即两个节点将自己的远程归档相互配置在对方机器上。DMDSC 集群配置远程归档后,集群中任意实例都可以像访问本地归档一样,访问所有实例产生的归档日志。
远程归档的使用场景:
1.执行数据库恢复时,恢复工具(如 DMRMAN)所在节点需要访问其他各节点归档日志。
2.DMDSC 守护系统中进行主、备库异步归档日志的同步或备库恢复时,DMDSC 控制节点作为发送端,需要访问其他从节点的归档日志。
2.2.11.3 归档文件
备库归档机制调整后,备库归档日志文件写入的并不是自己重演生成的 Redo 日志,而是直接将主库产生的 Redo 日志写入到本地归档日志文件中。为了区分生成 Redo 日志和写入 Redo 日志的库,归档日志文件头增加了几个 MAGIC 字段:
- PMNT_MAGIC 永久魔数,用来唯一标识数据库,初始化数据库时生成并保持不变(DDL_CLONE 还原库除外),数据守护集群中所有主备库的 PMNT_MAGIC 是相同的。只有 DDL_CLONE 还原库的 PMNT_MAGIC 会发生改变,当一个库使用 DDL_CLONE 备份集还原并恢复之后,在执行 RECOVER DATABASE …… UPDATE DB_MAGIC 时,PMNT_MAGIC 会发生改变。
- DB_MAGIC 数据库魔数,数据库初始化时生成,数据库还原后重新生成新的 DB_MAGIC,数据守护集群中所有主备库的 DB_MAGIC 是不同的。归档日志文件使用 DB_MAGIC 标识写入 Redo 日志的库。
- SRC_DB_MAGIC 源库魔数,产生 Redo 日志数据库的 DB_MAGIC 值;主库归档日志文件中 SRC_DB_MAGIC 与 DB_MAGIC 相同;备库归档日志文件中 SRC_DB_MAGIC 与主库的 DB_MAGIC 值相同。
PRIMARY/Normal 模式库本地归档日志文件的命名方式为:
"ARCH_NAME_DB_MAGIC_EP节点号_日期时间.log"
其中 ARCH_NAME 是在 dmarch.ini 中配置的归档名称,DB_MAGIC 是生成日志的数据库魔数,EP 节点号代表当前实例的 DSC 节点号,日期时间是归档日志文件的创建时间。
例如:
"ARCHIVE_LOCAL1_0x567891_EP0_2022-03-20_10-35-34.log"
STANDBY 模式库(备库)生成的归档日志文件的命名方式为:
"STANDBY_ARCHIVE_P_DB_MAGIC_EP节点号_SELF_DB_MAGIC_日期时间.log"
其中 STANDBY_ARCHIVE 表示备库生成的归档日志文件,P_DB_MAGIC 是生成日志的数据库(主库)魔数,EP 节点号代表主库对应的 DSC 节点号,SELF_DB_MAGIC 是自身(备库)魔数,日期时间是归档日志文件的创建时间。
例如:
"STANDBY_ARCHIVE_0x123456_EP0_0x234567_2022-03-20_10-35-34.log"
注意由于STANDBY_ARCHIVE用于表示备库生成的归档日志,不允许将归档名称配置为STANDBY_ARCHIVE。
2.2.11.4 实时归档
与本地归档写入保存在磁盘中的日志文件不同,实时归档(Realtime)将主库产生的 Redo 日志通过 MAL 系统传递到备库,实时归档是实时主备和 MPP 主备的实现基础。实时归档只在主库生效,一个主库可以配置 1~8 个实时备库。
实时归档的执行流程是,主库在 Redo 日志(RLOG_PKG)写入联机日志文件前,将 Redo 日志发送到备库,备库收到 Redo 日志(RLOG_PKG)后标记为 KEEP_RLOG_PKG,将原 KEEP_RLOG_PKG 加入日志重演任务系统,并马上响应主库,不需要等待 Redo 日志重演结束后再响应主库。主库收到备库的响应消息,确认备库已经收到 Redo 日志后,再将 Redo 日志写入联机日志文件中。
另外,实时归档也可以支持读写分离集群,实时归档也分为两种模式:事务一致模式和高性能模式,可以通过 dmarch.ini 中的 ARCH_WAIT_APPLY 或 WAIT_APPLY 配置项来设置实时归档的模式。这两种模式的具体含义和下一小节 2.2.11.5 中的说明完全相同,区别仅在于配置为实时归档时,dmarch.ini 中的 ARCH_WAIT_APPLY 配置项默认值为 0,即采用高性能模式,具体内容请参考 2.2.11.5 和 2.6.5 小节。
实时归档流程图如下所示:
2.2.11.5 即时归档
即时归档(Timely)在主库将 Redo 日志写入联机日志文件后,通过 MAL 系统将 Redo 日志发送到备库。即时归档与实时归档的主要区别是 Redo 日志的发送时机不同。一个主库可以配置 1~8 个即时备库。
根据备库重演 Redo 日志和响应主库时机的不同,即时归档分为两种模式:事务一致模式和高性能模式。即时归档模式可以通过 dmarch.ini 中的 ARCH_WAIT_APPLY 或 WAIT_APPLY 配置项来设置。其中,ARCH_WAIT_APPLY 配置项默认值为 1,表示事务一致模式。
- 事务一致模式 主库事务提交触发 Redo 日志刷盘和即时归档,备库收到主库发送的 Redo 日志,并重演完成后再响应主库。主库收到备库响应消息后,再响应用户的提交请求。事务一致模式下,同一个事务的 SELECT 语句无论是在主库执行,还是在备库执行,查询结果都满足 READ COMMIT 隔离级要求。
- 高性能模式 与实时归档一样,备库收到主库发送的 Redo 日志后,马上响应主库,再启动日志重演。高性能模式下,备库与主库的数据同步存在一定延时(一般情况下延迟时间非常短暂,用户几乎感觉不到),不能严格保证事务一致性。
事务一致模式下,主备库之间严格维护事务一致性,但主库要等备库 Redo 日志重演完成后,再响应用户的提交请求,事务提交时间会变长,存在一定的性能损失。高性能模式则通过牺牲事务一致性获得更高的性能和提升系统的吞吐量。用户应该根据实际情况,选择合适的即时归档模式。
即时归档流程图如下所示:
2.2.11.6 异步归档
异步归档(Async)由主、备库上配置的定时器触发,根据异步备库的 KEEP LSN 信息,扫描本地归档目录获取 Redo 日志,并通过 MAL 系统将 Redo 日志发送到异步备库。异步备库的 Redo 日志重演过程与实时归档等其他类型的归档完全一致。
每个 PRIMARY 或 STANDBY 模式的数据库最多可以配置 8 个异步备库,Normal 模式下配置的异步备库会自动失效。异步备库可以级联配置,异步备库本身也可以作为源库配置异步备库。
异步归档流程图如下所示:
2.2.11.7 同步归档
同步归档(Sync)在主库归档日志刷盘后,通过 MAL 系统将 Redo 日志发送到备库。同步备库的 Redo 日志重演过程与实时归档等其他类型的归档完全一致。一个主库可以配置 1~8 个同步备库。
同步归档的执行流程是,主库在归档日志刷盘后,将 Redo 日志发送到备库,备库收到 Redo 日志(RLOG_PKG)后将其加入日志重演任务系统,并马上响应主库,不需要等待 Redo 日志重演结束后再响应主库。
同步归档流程图如下所示:
2.2.11.8 归档区别
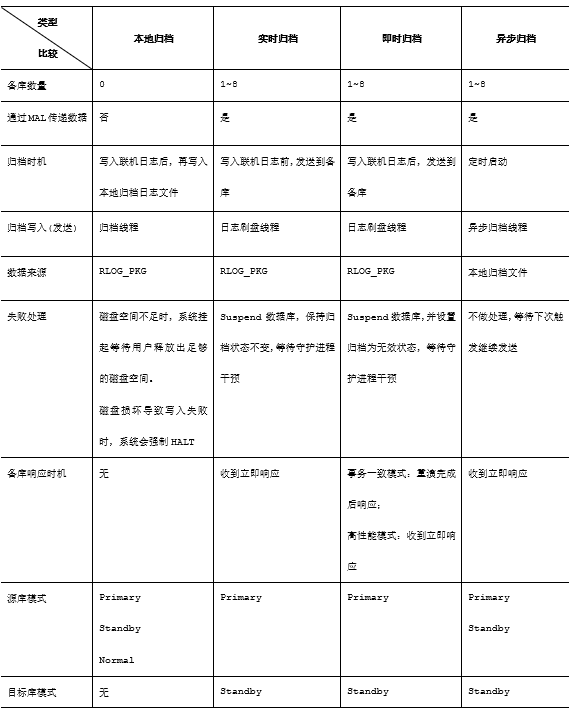
注意任意一个备库的实时归档/即时归档失败(即使其他备库归档成功了),主库都会切换为Suspend状态。
2.2.11.9 归档状态
本地归档、实时归档和即时归档均包含两种状态:Valid 和 Invalid。同步备库有三种归档状态:Valid,Invalid 和 Async_send。
- Valid 归档有效,正常执行各种数据库归档操作。
- Invalid 归档无效,主数据库不发送联机 Redo 日志到备数据库。
- Async_send 归档无效,但主库正在同步历史数据到同步备库。
在不同的归档类型中,归档状态转换时机不同。具体转换时机描述如下:
- 主备库启动后,主库到所有备库的归档默认为 Valid 状态,守护进程 Open 主库前,根据主备库日志同步情况,将数据不一致备库的归档修改为 Invalid 状态。
- 实时备库和即时备库故障恢复,从主库同步历史数据后,守护进程将主库修改为 Suspend 状态,并将主库到备库的归档状态从 Invalid 修改为 Valid。当守护进程再次 Open 主库后,主备库数据重新恢复为一致状态。
- 同步备库故障恢复,主库开始同步历史数据时,将备库归档状态从 Invalid 修改为 Async_send,中间会将日志刷盘线程挂起确保备库能够追到和主库数据完全一致,并将主库到备库的归档状态从 Async_send 修改为 Valid,然后唤醒日志刷盘线程,主备库数据重新恢复为一致状态。
- 主库发送日志到实时备库失败挂起,守护进程处理 Failover 过程中,将主库到备库的归档状态修改为 Invalid。
- 主库发送即时归档失败后,直接将主库到备库的归档改为 Invalid 状态。
- 主库发送同步归档失败后,直接将主库到备库的归档改为 Invalid 状态,并且不会有主库切换到 Suspend 状态的过程。
- 主库发现同步备库归档状态为 Invalid,且满足同步备库故障恢复的条件时,将主库到备库的归档状态从 Invalid 改为 Async_send,并开始同步历史数据到备库,同步完成后会将备库归档状态从 Async_send 修改为 Valid 有效状态。
注意实时归档、即时归档只对PRIMARY模式的主库有效,备库上配置的实时归档、即时归档状态没有实际意义,始终保持Valid状态。
异步归档也包含三种归档状态:Valid,Invalid 和 Async_send。Async_send 状态表示源库正在向异步备库发送归档日志。若发送成功,则将归档状态置为 Valid;否则将归档状态置为 Invalid,直到定时器触发下一次归档同步。异步归档初始状态为 Valid。
2.2.12 MAL 系统
MAL 系统是基于 TCP 协议实现的一种内部通信机制,具有可靠、灵活、高效的特性。DM 通过 MAL 系统实现 Redo 日志传输,以及其他一些实例间的消息通讯。
2.2.13 OGUID
数据守护唯一标识码,配置数据守护时,需要由用户指定 OGUID 值。其中数据库的 OGUID 由系统过程 SP_SET_OGUID 设置,守护进程和监视器的 OGUID 值在配置文件中设定。
同一守护进程组中的所有数据库、守护进程和监视器,都必须配置相同的 OGUID 值,取值范围为 0~2147483647。
OGUID 的查询方式:
SELECT OGUID FROM V$INSTANCE;
2.2.14 守护进程组
配置了相同 OGUID 的两个或多个守护进程,构成一个守护进程组。为方便管理,对每个守护进程组进行命名,守护进程组中的所有守护进程和监视器,必须配置相同的组名。
2.2.15 组分裂
同一守护进程组中,不同数据库实例的数据出现不一致,并且无法通过重演 Redo 日志重新同步数据的情况,我们称为组分裂。引发组分裂的主要原因包括:
- 即时归档中,主库在将 Redo 日志写入本地联机 Redo 日志文件之后,发送 Redo 日志到备库之前出现故障,导致主备库数据不一致,为了继续提供服务,执行备库强制接管、或者备库自动接管成功。此时,当故障主库重启后,就会引发组分裂。
- 故障备库重新完成数据同步之前,主库硬件故障,并且长时间无法恢复;在用户接受丢失部分数据情况下,为了尽快恢复数据库服务,执行备库强制接管,将备库切换为主库。此时,如果故障主库重启,也会造成组分裂。
检测到组分裂后,守护进程会修改控制文件为分裂状态,强制退出被分裂的库,被分裂出去的数据库需要通过备份还原等技术手段重新恢复。
2.2.16 脑裂
脑裂是同一个守护进程组中同时出现两个或者多个活动主库,并且这些主库都接收用户请求,提供完整数据库服务。一旦发生脑裂,将无法保证数据一致性,对数据安全造成严重后果。
DM 数据守护系统为预防脑裂做了大量工作,例如故障自动切换模式的数据守护必须配置确认监视器。确认监视器启动故障切换之前,会进行严格的条件检查,避免脑裂发生。守护进程一旦检测到脑裂发生,会马上强制退出所有活动主库,等待用户干预,避免数据差异进一步扩大。
造成脑裂的主要原因有两个:网络不稳定或错误的人工干预。为了避免出现脑裂,我们建议:
- 设置 dm.ini 参数 ALTER_MODE_STATUS=0,限制用户进行直接通过 SQL 修改数据库模式、状态以及 OGUID。
- 提供稳定、可靠的网络环境。
- 配置自动切换数据守护时,将确认监视器部署在独立的第三方机器上,不要与某一个数据库实例部署在一起,避免由于网络问题触发自动故障切换,导致脑裂发生。
- 通过人工干预,将备库切换为主库之前,一定要确认主库已经发生故障,避免主库活动情况下,备库强制接管,人为造成脑裂。
2.2.17 DB_NAME 和 INSTANCE_NAME
使用 DM 数据库配置助手或 dminit 工具初始化数据库实例时通常需要指定数据库名 DB_NAME 和实例名 INSTANCE_NAME。
针对 DMDSC 集群或主备系统中的所有节点实例,其 DB_NAME 可以相同,但 INSTANCE_NAME 必须不同。因此使用 INSTANCE_NAME 可以唯一标识集群中的每个节点实例。
在数据守护系统的监视器命令中,通常需要指定 DB_NAME 来查看指定库的监视信息。由于 DB_NAME 不要求全局唯一,因此在部分场景下指定数据库名 DB_NAME 可能无法准确定位到具体的库,所以对于单节点库,可以指定其实例名来查看其监视信息,对于 DMDSC 集群,则可以指定集群中控制节点的实例名来查看该集群的监视信息。
2.3 术语定义
数据守护系统包含主库、备库、守护进程、监视器等诸多部件,在主备库切换、故障处理等场景下,仅以主库或者备库这些称谓,已经无法准确描述对应部件。为了更加清晰的描述数据守护系统,特别定义以下术语。
| 序号 | 术语 | 含义 |
|---|---|---|
| 1 | 实时主备 | 配置实时归档的主备系统 |
| 2 | MPP 主备 | 配置实时归档的 MPP 集群主备系统 |
| 3 | 读写分离集群 | 配置即时归档或实时归档的主备系统 |
| 4 | 实时主库[实例名] | 实时主备系统中 PRIMARY 模式的库 |
| 5 | 实时备库[实例名] | 实时主备系统中 STANDBY 模式的库 |
| 6 | MPP 主库[实例名] | MPP 主备系统中 PRIMARY 模式的库 |
| 7 | MPP 备库[实例名] | MPP 主备系统中 STANDBY 模式的库 |
| 8 | 即时主库[实例名] | 采用即时归档的读写分离主备系统中 PRIMARY 模式的库 |
| 9 | 即时备库[实例名] | 采用即时归档的读写分离主备系统中 STANDBY 模式的库 |
| 10 | 异步备库[实例名] | 异步归档目标库,STANDBY 模式 |
| 11 | 异步源库[实例名] | 异步归档源库,PRIMARY/STANDBY 模式都可,实时、即时归档的主备库作为异步源库时,各库都需要设置异步备库作为归档目标,支持多源的配置,但是只有当前主库才会同步数据 |
| 12 | 同步备库[实例名] | 同步归档目标库,STANDBY 模式 |
| 13 | 同步源库[实例名] | 同步归档源库,PRIMARY/STANDBY 模式都可,实时、即时归档的主备库作为同步源库时,各库都需要设置同步备库作为归档目标,支持多源的配置,但是只有当前主库才会同步数据 |
| 14 | 故障主库[实例名] | 发生故障的 PRIMARY 模式实例 |
| 15 | 故障备库[实例名] | 发生故障的 STANDBY 模式实例 |
| 16 | 数据一致备库[实例名] | 主库到当前备库归档处于有效状态,备库与主库数据保持一致 |
| 17 | 可恢复备库[实例名] | 主库到当前备库归档处于失效状态,备库与主库数据存在差异,但主库归档日志涵盖备库缺失的数据 |
| 18 | 分裂库[实例名] | 与主库数据不一致,且无法通过重做归档日志将数据恢复到一致状态的库 |
| 19 | 守护进程组[组名] | 配置了相同 OGUID 的两个或多个守护进程,构成一个守护进程组 |
| 20 | DMDSC 数据守护 | 主备库中包含数据共享集群(DSC)的守护系统 |
| 21 | 控制守护进程 | 守护 DMDSC 集群数据库控制节点的守护进程 |
| 22 | 普通守护进程 | 守护 DMDSC 集群数据库普通节点的守护进程 |
| 23 | 重演节点个数 | 备库上记录的 n_apply 个数,和当前正在重演的日志所对应的主库节点个数(n_ep)一致 |
| 24 | 监视器 | 基于监视器接口实现的命令行工具,用于监控、管理数据守护系统 |
| 25 | 确认监视器 | 运行在确认模式下的监视器 |
| 26 | 网络故障 | 指主备库之间网络断开,消息无法传递 |
| 27 | 网络异常 | 指主备库之间网络未断开,消息可以传递,但出现速度变慢等情形 |
| 28 | 备库故障 | 指备库出现软、硬件故障,导致数据库实例关闭 |
| 29 | 备库异常 | 指备库的数据库实例正常,但响应速度出现异常 |
注意配置数据守护时,数据库实例名不建议配置为PRIMARY/STANDBY,守护进程组名不建议配置成和实例名相同,避免在描述对象时产生歧义。
2.4 实时主备
实时主备系统由主库、实时备库、守护进程和监视器组成。通过部署实时主备系统,可以及时检测并处理各种硬件故障、数据库实例异常,确保持续提供数据库服务。
2.4.1 主要功能
实时主备系统主要功能包括:
1. 实时数据同步
主备库通过实时归档完成数据同步,实时归档要求主库将 RLOG_PKG 发送到备库后,再将 RLOG_PKG 写入本地联机 Redo 日志文件。但要注意的是,备库确认收到主库发送的 Redo 日志,并不保证备库已经完成重演这些 Redo 日志,因此主备库之间的数据同步存在一定的时间差。
2. 主备库切换
主备库正常运行过程中,可以通过监视器的 Switchover 命令,一键完成主备库角色转换。主备库切换功能可以确保在软、硬件升级,或系统维护时,提供不间断的数据库服务。
3. 自动故障处理
备库故障,不影响主库正常提供数据库服务,守护进程自动通知主库修改实时归档为 Invalid 状态,将实时备库失效。
4. 自动数据同步
备库故障恢复后,守护进程自动通知主库发送归档 Redo 日志,重新进行主备库数据同步。并在历史数据同步后,修改主库的实时归档状态为 Valid,恢复实时备库功能。
备库接管后,原主库故障恢复,守护进程自动修改原主库的模式为 STANDBY,并重新作为备库加入主备系统。
5. 备库接管
主库发生故障后,可以通过监视器的 Takeover 命令,将备库切换为主库,继续对外提供服务。如果配置为自动切换模式,确认监视器可以自动检测主库故障,并通知备库接管,这个过程不需要人工干预。
6. 备库强制接管
如果执行 Takeover 命令不成功,但主库可能由于硬件损坏等原因无法马上恢复,为了及时恢复数据库服务,DM 提供了 Takeover Force 命令,强制将备库切换为主库。但需要由用户确认主库故障前,主库与接管备库的数据是一致的(主库到备库的归档是 Valid 状态),避免引发守护进程组分裂。
7. 读写分离访问
在备库查询的实时性要求不高的条件下,实时主备也可以配置接口的读写分离属性访问,实现读写分离功能特性。详见 2.6 读写分离集群章节。
注意执行Takeover Force有可能引发组分裂,而Takeover命令是在确保不会产生组分裂情况下才允许执行
2.4.2 归档流程
实时归档是实时主备数据同步的基础,主库生成联机 Redo 日志,当触发日志写文件操作后,日志线程先将 RLOG_PKG 发送到备库,备库接收后进行合法性校验(包括日志是否连续、备库状态是否 Open 等),不合法则返回错误信息,合法则作为 KEEP_RLOG_PKG 保留在内存中,原有 KEEP_RLOG_PKG 的 Redo 日志加入 Apply 任务队列进行 Redo 日志重演,并响应主库日志接收成功。当有多个备库时,主库需要收到所有备库的响应消息才继续后续操作。
2.5 MPP 主备
MPP 主备就是在 MPP 集群的基础上,为每一个 MPP 节点配置一套实时主备系统,这些实时主备系统一起构成了 MPP 主备系统。MPP 主备系统包含多个守护进程组,每个守护进程组都是一个相对独立的实时主备系统,具备实时主备的基本功能,可以进行主备切换、备库接管等操作。
MPP 主备的主要目的是为 DM MPP 集群提供数据可靠性保障,备库只做数据容灾、备份,MPP 备库并不是 MPP 集群的一部分,只是某个 MPP 节点(主库)的镜像。MPP 备库不参与 MPP 操作,与其他 MPP 备库之间也没有任何关系,MPP 备库只能以单节点方式提供只读服务,但不提供全局的 MPP 只读服务。
MPP 主备系统中,一个守护进程 dmwatcher 可以监控、管理多个守护进程组的数据库实例。一般来说,一台物理机器上,可以部署 1 个 MPP 节点的主库和多个其他 MPP 节点的备库,充分利用硬件资源,节省投资。
Global 守护类型的 MPP 主备库需要在 dm.ini 中配置 MPP_INI 为 1,并且 MPP 主备库的本地数据文件目录下都需要有 dmmpp.ctl 文件,如果 Global 守护类型的备库没有上述配置,守护进程和监视器无法正常使用,守护进程会切换到 Shutdown 状态,监视器上无法正常执行命令,会打印配置不一致的提示信息。
下图以三个 MPP 节点,每个节点配备两个备库为例,说明 MPP 主备系统的结构。
2.5.1 功能扩展
与实时主备系统相比,MPP 主备扩充了维护 MPP 控制文件功能,dmmpp.ctl 控制文件记录了 MPP 集群的节点信息,在主备库切换或者备库接管后,必须将新的主库信息更新到 dmmpp.ctl 文件中。
2.5.2 dmmpp.ctl 维护
dmmpp.ctl 控制文件的信息主要包括:系统状态、MPP 节点数、文件校验码、故障节点数、故障节点序号、配置项名、实例名、实例节点序号,以及根据节点数和实例序号生成的哈希映射数组等。MPP 集群中节点间的关联信息记录在 dmmpp.ctl 控制文件中,因此,所有 MPP 主节点存放的 dmmpp.ctl 文件内容要求完全一致。
MPP 主备系统中,要求所有节点(包括主库和备库)的 ctl_path 目录保存一份 dmmpp.ctl 控制文件,并要求将所有节点的 dm.ini 参数 MPP_INI 配置为 1,以确保 MPP 主备系统正常运行。
当 MPP 主备系统中某个守护进程组的主节点发生变化(切换或接管),监视器会通知所有主节点更新本地 dmmpp.ctl 文件,确保所有主节点 dmmpp.ctl 控制文件始终保持一致。
当 MPP 主备系统中所有主节点都故障,需要进行强制接管时,守护进程会根据备库上的 dmmpp.ctl 文件,重新构造完整、有效的 dmmpp.ctl 内容,并最终更新新主库的 dmmpp.ctl 文件。
执行 MPP 主备库切换操作,需要修改所有节点的 dmmpp.ctl 文件,将新主库实例名替换原主库实例名。比如 0 号节点发生切换,只要将 0 号节点对应的 mpp_inst_name 修改为新主库的实例名。
下面根据图 2.10 MPP 主备系统图,举例说明一个节点主备切换时相应的控制文件是如何变化的。由于 dmmpp.ctl 是二进制文件,为了便于识别,下面列出的是对应转换的文本格式内容。原始配置如下:
[service_name1] ##配置项名
mpp_seq_no = 0 ##节点序号
mpp_inst_name = EP0 ##节点实例名
[service_name2]
mpp_seq_no = 1
mpp_inst_name = EP1
[service_name3]
mpp_seq_no = 2
mpp_inst_name = EP2
将 EP0 和 EP0'切换后,dmmpp.ctl 中对应的实例信息如下,可以看出配置项中只有节点实例名 EP0 变化为 EP0'了,节点序号以及其他配置项的内容都保持不变:
[service_name1] ##配置项名
mpp_seq_no = 0 ##节点序号
mpp_inst_name = EP0' ##节点实例名
[service_name2]
mpp_seq_no = 1
mpp_inst_name = EP1
[service_name3]
mpp_seq_no = 2
mpp_inst_name = EP2
MPP 集群中用户登录某个节点创建一个会话(session)时,系统自动在其他 MPP 节点上建立对应的镜像会话(msession),会话断开时,系统自动通知其他 MPP 节点释放对应会话(镜像会话)。MPP 主备切换时,整个 MPP 集群的所有连接被强制断开、所有会话被强制释放、并且切换过程中新的连接请求会被阻塞。主备切换完成后,连接请求会被分配到新的主节点上。
2.6 读写分离集群
读写分离集群是基于即时归档或实时归档实现的高性能数据库集群,不但提供数据保护、容灾等数据守护基本功能,还具有读写操作自动分离、负载均衡等特性。读写分离集群最多可以配置 8 个即时备库或 8 个实时备库,提供数据同步、备库故障自动处理、故障恢复自动数据同步等功能,也支持自动故障切换和手动故障切换两种守护模式。
一般情况下,应用系统中查询等只读操作的比例远大于 Insert/Delete/Update 等 DML 操作,修改对象定义等 DDL 操作的比例则更低。但是,这些操作往往混杂在一起,在高并发、高压力情况下,会导致数据库性能下降,响应时间变长。借助读写分离集群,将只读操作自动分发到备库执行,可以充分利用备库的硬件资源,降低主库的并发访问压力,进而提升数据库的吞吐量。
读写分离集群不依赖额外的中间件,而是通过数据库接口与数据库之间的密切配合,实现读、写操作自动分离特性。DM 的 JDBC、DPI、DCI、ODBC、Provider、dmPython 等接口都可以用来部署读写分离集群。
根据是否满足读提交事务隔离级特性,读写分离集群可以配置为事务一致模式和高性能两种模式。简单的说,事务一致模式下,不论一个 Select 语句是在备库执行、还是在主库执行,其查询结果集都是一样的。高性能模式则不能保证查询是一致的,备库的数据与主库的数据同步存在一定的延迟,当 Select 语句发送到备库执行时,返回的有可能是主库上一个时间点的数据。
2.6.1 归档流程
读写分离集群可以配置为即时归档,也可以配置为实时归档,这两种配置方式仅仅是归档流程上有差别,读写分离集群的特性仍然是一致的。即时归档流程与实时归档流程存在一定差异:
-
主库先将日志写入本地联机 Redo 日志文件中,再发送 RLOG_PKG 到备库。
-
备库日志重演时机有两种选择:
- 事务一致模式 要求备库在重演 Redo 日志完成后再响应主库。
- 高性能模式 与实时归档一样,收到 Redo 日志后,马上响应主库。
-
即时归档的同步机制可以保证备库的 Redo 日志不会比主库的 Redo 日志多,因此即时备库不需要 KEEP_RLOG_PKG,收到 RLOG_PKG 直接加入到 Apply 任务系统,启动 Redo 日志重演。
-
备库故障或主备库之间网络故障,导致发送 RLOG_PKG 失败后,主库马上修改即时归档为 Invalid 状态,并切换数据库为 Suspend 状态。
-
即时归档修改为 Invalid 状态后,会强制断开对应此备库上存在影子会话的用户会话,避免只读操作继续分发到该备库,导致查询数据不一致。
2.6.2 实现原理
实现读写分离集群的基本思路是:利用备库提供只读服务、无法修改数据的特性,优先将所有操作发送到备库执行,一旦备库执行报错,则发送到主库重新执行。通过备库“试错”这么一个步骤,自然地将只读操作分流到备库执行。并且,备库“试错”由接口层自动完成,对应用透明。
读写分离集群数据库连接创建流程:
- 用户发起数据库连接请求。
- 接口(JDBC、DPI 等)根据服务名配置(在连接串或 dm_svc.conf 中进行配置)登录主库。
- 主库挑选一个有效即时备库或实时备库的 IP/Port 返回给接口。
- 接口根据返回的备库 IP 和 Port 信息,向备库发起一个连接请求。
- 备库返回连接成功信息。
- 接口响应用户数据库连接创建成功。
接口在备库上创建的连接是读写分离集群自动创建的;对用户而言,就是在主库上创建了一个数据库连接。下图以配置了两个备库的读写集群为例,说明了读写分离集群的连接创建流程。
读写分离集群语句分发流程:
- 接口收到用户的请求。
- 接口优先将 SQL 发送到备库执行。
- 备库执行并返回执行结果。如果接口收到的是备库执行成功消息,则转到第 6 步,如果接口收到的是备库执行失败消息,则转到第 4 步。
- 重新将执行失败的 SQL 发送到主库执行。只要第 3 步中的 SQL 在备库执行失败,则同一个事务后续的所有操作(包括只读操作)都会直接发送到主库执行。
- 主库执行并返回执行结果给接口。一旦主库上执行的写事务提交,则下次继续从第 1 步开始执行。
- 接口响应用户并将执行结果返回给用户。
执行举例说明:
//数据准备
CREATE TABLE T(C1 INT);
//事务开始
SELECT * FROM T; //首先在备库上执行
INSERT INTO T VALUES(1); //写操作转移到主库上执行
SELECT * FROM T; //事务未提交,还在主库上执行
COMMIT; //事务提交
SELECT * FROM T; //事务已提交,重新转移到备库上执行
2.6.3 事务一致性
读写分离集群通过 JDBC、DPI 等接口自动分发语句,一个事务包含的多个语句可能分别在备库和主库上执行,但执行结果与单独在一个数据库实例上完全一致,满足读提交事务隔离级特性。
下面以两段伪代码 trx1 和 trx2 为例,说明读写分离的特性和如何实现事务隔离级。
| trx1: UPDATE T SET C1 = 2; COMMIT; |
trx2: RS = SELECT C1 FROM T; FETCH C1 FROM RS INTO VAR_X; INSERT INTO TX VALUES(VAR_X); COMMIT; |
根据读写分离特性,trx1 的 UPDATE 在主库执行;trx2 的 SELECT 语句在备库执行,INSERT 语句转到主库执行,并且 trx2 的 INSERT 语句的插入值,是从之前执行的 SELECT 结果集中获取。
下面根据即时归档流程,结合 trx2 执行 SELECT 语句时机和以及 trx1 的不同状态进行讨论,详细地说明读写分离集群是如何实现提交事务隔离级别的。
- 第一种情况,trx2 执行 SELECT 时,trx1 的 COMMIT 还未执行。
trx2 的 SELECT 语句,无论是在主库还是备库执行,查询结果都是 trx1 更新 T 表之前的值,var_x = 1。
- 第二种情况,trx2 执行 SELECT 时,trx1 的 COMMIT 已经执行完成。
trx2 的 SELECT 语句,无论是在主库还是备库执行,查询结果都是 trx1 更新 T 表后的值,var_x = 2。
- 第三种情况,trx2 执行 SELECT 时,trx1 正在执行 COMMIT。
trx2 的 SELECT 查询结果,与两个语句在系统内部的执行顺序有关,var_x 的值可能是 1 或者 2。但由于 trx1 的 COMMIT 并没有明确响应用户,var_x 的最终值取决于数据库管理系统的实现策略,无论返回 1 还是 2,都符合读提交事务隔离级。
为了保证主备库上的一致性,目前读写分离集群有下列一些类型的语句不会在备库上执行,都在主库上执行:
- 设置会话、事务为串行化隔离级语句。
- 表对象上锁语句(LOCK TABLE XX IN EXCLUSIVE MODE)。
- 查询上锁语句(SELECT FOR UPDATE)。
- 设置自增列操作语句(SET IDENTITY_INSERT TABLE ON)。
- 访问 @@IDENTITY、@@ERROR 等全局变量。
注意读写分离集群中,当一个SQL从备库切换到主库执行时,主库会启动一个新的事务,主库事务与备库事务没有任何联系,事务ID也完全不同。备库事务ID与主库事务ID分配机制并不相同,主库的事务ID取值范围是[1 \~ 0x7FFFFFFFFFFF],备库事务ID取值范围是[0x800000000000 \~ 0xFFFFFFFFFFFF];备库事务ID是一个内存值,每次重启后都从0x800000000000开始重新分配;主库事务ID是一个物理值,一旦分配后,就不会再重复分配。
2.6.4 性能调整
根据读写分离语句分发流程可以发现,当一个应用系统中只读事务占绝大多数情况下,可能出现备库高负载、高压力,主库反而比较空闲的情况。为了实现负载均衡,更好地利用主备库的硬件资源,JDBC 等数据库接口提供了配置项,允许将一定比例的只读事务分发到主库执行。因此,用户应该根据主备库的负载情况,灵活调整接口的分发比例 rwPercent 配置项,以获得最佳的数据库性能。
备库数量是影响读写分离集群性能的一个重要因素,备库越多则每个备库需要承担的任务越少,有助于提升系统整体并发效率。另外,事务一致模式下,主库要等所有备库重演 Redo 日志完成后,才能响应用户,随着备库的增加,即时归档时间会变长,最终降低非只读事务的响应速度。因此,部署多少备库,也需要综合考虑硬件资源、系统性能等各种因素。
配置为高性能模式,则是提升读写分离集群的另一个有效手段。如果应用系统对查询结果实时性要求并不太高,并且事务中修改数据的操作也不依赖同一个事务中的查询结果。那么,通过修改 dmarch.ini 中的 ARCH_WAIT_APPLY 配置项为 0,将读写分离集群配置为高性能模式,可以大幅提高系统整体性能。如果应用包含以下代码逻辑,则不适合使用高性能模式:
//tx1事务开始
INSERT INTO T VALUES(1); //写操作在主库上执行
COMMIT; //事务提交
//tx2事务开始
SELECT TOP 1 C1 INTO VAR1 FROM T; //tx1事务已提交,SELECT操作重新转移到备库上执行。高性能模式下备库可能还没有重做日志,查不出tx1中插入的结果
UPDATE T SET C1 = VAR1 + 1 WHERE C1 = VAR1; //更新不到数据
此外,根据读写分离特性合理地规划应用的事务逻辑,也可以获得更佳的性能:
- 尽可能将事务规划为只读事务和纯修改事务,避免无效的备库试错。
- 读操作尽量放在写操作之前,用备库可读的特点来分摊系统压力。
2.6.5 实时归档的读写分离
实时主备也可以配置接口的读写分离属性进行访问,实现读写分离功能特性。
实时读写分离同样也支持事务一致模式和高性能模式,由配置文件 dmarch.ini 中的 ARCH_WAIT_APPLY 或 WAIT_APPLY 配置项来确定,1 表示事务一致模式,0 表示高性能模式。实时读写分离下,默认采用高性能模式。上述参数在实时归档中的用法和在即时归档中是相同的,只是 ARCH_WAIT_APPLY 的默认值不同,事务一致模式和高性能模式的具体含义可参考“2.2.11.5 即时归档”小节。
和即时归档不同的是,实时归档先发送日志到备库,然后再写入本地联机日志,和即时归档相比,实时归档的读写分离可以有效避免备库自动接管后老主库的分裂,在对读写分离集群的可用性要求比较高的情况下,可以采用这种配置方式。
注意实时读写分离的事务一致模式仅在数据守护配置为自动切换模式下才会生效。
对于配置实时归档的DMDSC数据守护集群,不支持事务一致模式,即不支持将ARCH_WAIT_APPLY或WAIT_APPLY配置为1。
2.6.6 示例与验证
下面通过一个简单示例对读写分离集群的使用进行演示,并介绍 4 种验证读写分离是否生效的方法。
2.6.6.1 读写分离示例
首先搭建一个由 1 主库 2 即时备库(单实例节点)组成的读写分离集群,具体搭建步骤可参考 7.3 配置读写分离集群的手动搭建方法,或使用 DEM 工具进行快速搭建。为了后续能更方便地查看信息,建议搭建时设置 INI 参数 SVR_LOG=1,打开 SQL 日志功能。
示例中使用的读写分离集群的配置如下:
| 机器名 | IP 地址 | 初始状态 | 操作系统 | 备注 |
|---|---|---|---|---|
| DW_P | 192.168.1.61 192.168.0.61 | 主库 GRP1_RWW_01 | Windows 10 | 192.168.1.61 外部服务 IP; 192.168.0.61 内部通信 IP |
| DW_S1 | 192.168.1.62 192.168.0.62 | 备库 GRP1_RWW_02 | Windows 10 | 192.168.1.62 外部服务 IP; 192.168.0.62 内部通信 IP |
| DW_S2 | 192.168.1.63 192.168.0.63 | 备库 GRP1_RWW_03 | Windows 10 | 192.168.1.63 外部服务 IP; 192.168.0.63 内部通信 IP |
| 实例名 | PORT_NUM | MAL_INST_DW_PORT | MAL_HOST | MAL_PORT | MAL_DW_PORT |
|---|---|---|---|---|---|
| DW_P | 7236 | 7436 | 192.168.1.61 | 7336 | 7536 |
| DW_S1 | 7237 | 7437 | 192.168.1.62 | 7337 | 7537 |
| DW_S2 | 7238 | 7438 | 192.168.1.63 | 7338 | 7538 |
为了正常使用读写分离功能,需要在 dm_svc.conf 文件中配置 rw_separate=(1)和 rw_percent=(25)。本例所配置的 dm_svc.conf 文件内容如下:
ZN=(192.168.1.61:7236,192.168.1.62:7237,192.168.1.63:7238)
TIME_ZONE=(480)
LANGUAGE=(cn)
[ZN]
RW_SEPARATE=(1)
RW_PERCENT=(25)
搭建完成后,分别使用 disql 连接主库和备库。在主库执行建表、插入等操作,可以正常执行。
//连接主库
./disql SYSDBA/DMdba_123@ZN
服务器[192.168.1.61:7236]:处于主库打开状态
登录使用时间 : 33.922(ms)
disql V8
SQL>create table t(a int);
SQL>insert into t values(1);
SQL>insert into t values(1);
分别查看主库和备库的 sql 日志(为了方便展示,省略部分不重要的内容)。此处体现的是利用备库提供只读服务、无法修改数据的特性,优先将所有操作发送到备库执行,一旦备库执行报错,则发送到主库重新执行。
| 主库 | 备库 |
|---|---|
| 2023-03-10 16:53:02.745 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:0 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [ORA]: create table t(a int); ······ 2023-03-10 16:53:02.745 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6063 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [DDL] create table t(a int); ····· 2023-03-10 16:53:02.808 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:0 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [DDL] create table t(a int); EXECTIME: 54(ms). 2023-03-10 16:53:07.245 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:0 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [ORA]: insert into t values(1); ······ 2023-03-10 16:53:07.245 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [INS] insert into t values(1); ······ 2023-03-10 16:53:07.245 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [INS] insert into t values(1); EXECTIME: 0(ms) ROWCOUNT: 1(rows). 2023-03-10 16:53:33.636 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [ORA]: insert into t values(1); 2023-03-10 16:53:33.636 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [INS] insert into t values(1); EXECTIME: 0(ms) ROWCOUNT: 1(rows). |
2023-03-10 16:53:02.745 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:0 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [ORA]: create table t(a int); ······ 2023-03-10 16:53:02.745 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:140737488355357 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [ERR(-710)]: create table t(a int); ······ 2023-03-10 16:53:07.245 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:0 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [ORA]: insert into t values(1); ······ 2023-03-10 16:53:07.245 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:140737488355358 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [INS] insert into t values(1); 2023-03-10 16:53:07.245 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:140737488355358 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [ERR(-710)]: insert into t values(1); EXECTIME: 0(ms) ROWCOUNT: 0(rows). |
分别在主库和备库上执行查询操作,并查看 sql 日志中的内容。此时由于事务未提交,仍在主库上执行,故在备库上无法查询到主库插入的内容。
| 主库 | 备库 |
|---|---|
| SQL> select * from t; 行号 A ---------- ----------- 1 1 2 1 |
SQL> select * from t1; 未选定行 |
| 2023-03-10 16:55:26.479 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61)[ORA]: select * from t; 2023-03-10 16:55:26.479 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [SEL] select * from t; 2023-03-10 16:55:26.479 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [SEL] select * from t; EXECTIME: 0(ms) ROWCOUNT: 2(rows). |
2023-03-10 16:55:35.380 (EP[0] sess:00000000008EF138 thrd:35184 user:SYSDBA trxid:140737488355347 stmt:0000000000913138 appname:DIsql.exe ip:192.168.1.61)[ORA]: select * from t; 2023-03-10 16:55:35.380 (EP[0] sess:00000000008EF138 thrd:35184 user:SYSDBA trxid:140737488355347 stmt:0000000000913138 appname:DIsql.exe ip:192.168.1.61) [SEL] select * from t; 2023-03-10 16:55:35.380 (EP[0] sess:00000000008EF138 thrd:35184 user:SYSDBA trxid:140737488355347 stmt:0000000000913138 appname:DIsql.exe ip:192.168.1.61) [SEL] select * from t; EXECTIME: 0(ms) ROWCOUNT: 0(rows). |
在主库中执行提交操作,并再次进行查询。
//连接主库
SQL> COMMIT;
SQL> select * from t;
行号 A
---------- -----------
1 1
2 1
//连接备库
SQL> select * from t;
行号 A
---------- -----------
1 1
2 1
分别查看主库和备库的 sql 日志,可以看到主库中只执行了提交操作,查询操作已经被发送至备库执行。分析备库的 sql 日志可以看出,可以按不同的 sess、trxid、stmt、ip 将这几条查询操作的记录分为两类,第一类为主库发送至备库执行的操作记录,第二类为在备库上执行查询操作的记录。
| 主库 | 备库 |
|---|---|
| 2023-03-10 17:37:57.549 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61)[ORA]: commit; 2023-03-10 17:37:57.549 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:6065 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [DML] commit; ······ 2023-03-10 17:37:57.549 (EP[0] sess:00000000012CF138 thrd:42560 user:SYSDBA trxid:0 stmt:00000000012F3138 appname:DIsql.exe ip:192.168.1.61) [DML] commit; EXECTIME: 1(ms). |
2023-03-10 17:39:26.372 (EP[0]sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:0 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [ORA]: select * from t; ······ 2023-03-10 17:39:26.372 (EP[0] sess:000000007E6A5138 thrd:39972 user:SYSDBA trxid:140737488355359 stmt:000000007E6C9138 appname:DIsql.exe ip:192.168.1.61) [SEL] select * from t; EXECTIME: 0(ms) ROWCOUNT: 2(rows). 2023-03-10 17:39:39.837 (EP[0] sess:00000000008EF138 thrd:35184 user:SYSDBA trxid:140737488355347 stmt:0000000000913138 appname:DIsql.exe ip:192.168.1.62) [ORA]: select * from t; 2023-03-10 17:39:39.837 (EP[0] sess:00000000008EF138 thrd:35184 user:SYSDBA trxid:140737488355347 stmt:0000000000913138 appname:DIsql.exe ip:192.168.1.62) [SEL] select * from t; EXECTIME: 0(ms) ROWCOUNT: 2(rows). |
2.6.6.2 读写分离验证
下面介绍验证读写分离的 4 种方法。
1) 查看 sql 日志。通过查看备库的 sql 日志内容,看是否有操作从主库发送至备库执行。发送的操作比例与设置的参数 rw_percent 相关。sql 日志中的内容可以参考上小节中的 sql 日志示例。
2) 计算备库上处理的事务数。可以通过连接备库,查询视图 V$SYSSTAT 中的 transaction commit count 字段和 transaction rollback count 字段,将这两行的统计值 STAT_VAL 相加,来计算备库上处理的事务数。举例如下:
./disql SYSDBA/DMdba_123@192.168.1.62:7327
服务器[192.168.1.62:7237]:处于备库打开状态
登录使用时间 : 6.143(ms)
disql V8
SQL> select * from v$sysstat where name like 'transaction commit count' or name like 'transaction rollback count';
查询结果如下:
行号 ID CLASSID NAME STAT_VAL
---------- ----------- ----------- -------------------------- --------------------
1 44 3 transaction commit count 47
2 45 3 transaction rollback count 10
将两个 STAT_VAL 值相加,得到该备库当前已经处理的事务数为 57。因有事务分发至备库处理,证明进行了读写分离。
3) 查看连接会话数。由于读写分离集群的特性,开启读写分离的情况下,连接上主库就会同时连接上一个可用备库,故通过 session 数也可以反映出是否确实为读写分离集群。通过查看服务器控制台的 session 数或者连接服务器查询 v$sessions,均可以用于分析当前集群是否为读写分离。举例说明如下:
查看服务控制台:
session
sessions number: 2
msessions number: 0
esessions number: 0
n_freeing: 0
max_concurrent_trx: 0
concurrent_trx_mode: 0
curr_concurrent_trx: 0
n wait trx: 0
连接服务器查询 v$sessions:
./disql SYSDBA/DMdba_123@192.168.1.62:7237
服务器[192.168.1.61:7237]:处于备库打开状态
登录使用时间 : 5.478(ms)
disql V8
SQL> select count(*) from v$sessions;
行号 COUNT(*)
---------- --------------------
1 2
已用时间: 3.181(毫秒). 执行号:165.
4) 通过测试程序调试的方式来验证读写分离。对于各个支持读写分离的接口,通过服务名连接后,查看返回的连接属性的值,可以看到里面有自动选择的可用备库的 ip port,证明成功搭建读写分离集群。
2.7 DMDSC 数据守护
DMDSC(数据共享集群)支持多个数据库实例同时访问、修改保存在共享存储中的数据,能够提供更高的数据库可用性和事务吞吐量。但由于数据是保存在共享存储上,当出现存储失效等故障时,数据库服务将会中断。
DM 数据守护包含多个数据库,主库和备库部署在不同的机器上,数据分别保存在各自的存储上,主库传递 Redo 日志到备库,备库重演 Redo 日志实现数据同步。因此,DM 数据守护在容灾(特别是异地容灾)方面具有明显的优势。为了进一步提高 DMDSC 集群的数据安全性,以及系统的可用性,DM 提供了 DMDSC 集群数据守护功能。
DMDSC 集群数据守护功能与单节点数据守护保持一致,支持故障自动切换,支持实时归档与读写分离集群。支持 DMDSC 集群的守护,DMDSC(主)和 DMDSC(备)、DMDSC(主)和单节点(备)、单节点(主)和 DMDSC(备)相互之间都可以作为主备库的数据守护。
2.7.1 总体结构
以下示例为 DMDSC 和单节点互为主备的守护系统结构简图:
总体原则说明:
- DMDSC 集群各个节点分别部署守护进程(dmwatcher)。
- DMDSC 集群数据库控制节点的守护进程,称为控制守护进程,普通节点的守护进程称为普通守护进程,如果控制节点发生变化,则控制守护进程也相应变化。
- 守护进程会连接 DMDSC 集群所有实例,但只有控制守护进程会发起 OPEN、故障处理、故障恢复等各种命令。普通守护进程不处理用户命令,但接收其他库的控制守护进程消息。
- 主备实时同步数据时,DMDSC 集群主库各个节点将各自产生的联机日志发送到备库控制节点(重演节点)进行重演,备库普通节点不接收日志。
2.7.2 系统连接
DMDSC 数据守护集群的守护进程和守护进程之间、监视器和守护进程之间、守护进程和 dmcss 之间都需要建立 TCP 连接,用于信息传递和命令执行。使用 TCP 连接的工具见下表:
| 工具 | TCP 连接说明 |
|---|---|
| 监视器(dmmonitor) | 连接所有的守护进程 |
| 守护进程(dmwatcher) | 1. 连接 DMDSC 集群内所有实例 2. 连接其他库的所有守护进程,但不连接 DMDSC 集群内其他实例的守护进程 3. 连接 DMDSC 集群内所有实例的 dmcss |
TCP 连接的详细使用说明:
- 控制守护进程连接所有 DMDSC 实例,发起 OPEN、故障处理、故障恢复等各种命令。普通守护进程不处理用户命令,但接收其他库的守护进程消息。
- 控制守护进程定时发送消息给实例,普通守护进程不会发消息给实例。
- 控制守护进程定时发送消息给其他库的守护进程以及监视器,普通守护进程只发送给监视器,不会发送给其他库的守护进程。
- DMDSC 集群内部不同实例的守护进程之间不通信。
- 普通守护进程连接 DMDSC 中所有实例,但只记录每个实例的信息,不做任何操作。同一个 DMDSC 集群内的所有守护进程之间不进行连接。
- DMDSC 中每个实例存在多个守护进程的连接,向每个 dmwatcher 发送广播消息,但只可能接收控制守护进程的命令。
- 不同库之间的守护进程都建立连接。
- 守护进程和 dmcss 建立连接,部分监视器执行命令通过守护进程转发,由 dmcss 执行。
2.7.3 归档配置
1.DMDSC 集群必须配置远程归档,用于 DMDSC 节点故障后的数据同步。
2.如果归档目标是 DMDSC 集群,则归档的目标节点需要同时配置 DMDSC 集群所有实例,一个 DMDSC 集群作为一个整体进行配置,realtime/timely/async 归档配置要求 ARCH_DEST 配置目标 DMDSC 集群所有节点信息,以‘/’分割。
注意对必须保证DMDSC集群中所有节点的归档配置是相同的。
2.7.4 日志发送
1.异步归档日志发送
主库是单节点时,单节点实例直接收集本地的归档日志发送到备库。
主库是 DMDSC 集群时,控制节点扫描本地归档和远程归档目录,收集所有节点的归档日志文件,并发送到备库,普通节点不发送归档日志。
2.实时/即时归档日志发送
单节点和 DMDSC 集群采用相同的处理逻辑,各节点将本实例产生的 Redo 日志直接发送到备库重演实例。
2.7.5 日志重演
Redo 日志重演是指备库收到主库发送的 Redo 日志后,在备库的物理数据页上,重新修改数据的过程。
2.7.5.1 备库日志重演规则
DMDSC 实现机制保证多个实例不能同时修改一个数据页,不同节点对同一个数据页修改产生的 LSN 一定是唯一、递增的。单个节点 Redo 日志的 LSN 可能不连续,但所有节点 Redo 日志归并在一起后,LSN 一定是连续的。但是,全局 Redo 日志归并后,可能存在 LSN 重复的非 PWR 日志。
为了降低备库重演不同节点日志时的 LSN 同步等待代价,备库收到不同节点的日志时,会按照日志包之间的依赖关系依次将不同节点的日志包按照顺序加入同一个重演任务系统,在开启并行重演的情况下,每个日志包会再交给多路并行重演线程进行并行重演,以此确保备库重演的性能。
2.7.5.2 备库日志重演相关实例
DSC 集群作为主库产生日志时严格按照先后顺序进行。DSC 作为备库重演日志时也严格按照日志的先后顺序进行。下面详细进行介绍。
2.7.5.2.1 DMDSC 集群作为主库
DMDSC 集群作为主库时,不同节点可能修改同一个数据页并各自产生日志,因此 DMDSC 集群的备库在重演同一个数据页的日志时,必须严格按照各节点修改的先后顺序进行重演,为了确保正确的重演顺序,DMDSC 集群的节点在修改数据页时,会记录下修改此数据页的前序节点和对应的 LSN 值,并将此信息写入日志包,组成日志包的依赖信息。
备库重演主库的日志包时,根据日志包上记录的对其他节点的依赖信息(包括节点号和 LSN),会等待依赖的节点(即修改相同数据页的前序节点)先重演到依赖信息中记录的 LSN 位置,然后再启动当前日志包的重演,确保重演顺序和主库上数据页的修改顺序完全一致。
主库通过异步方式发送日志时,也会通过日志包的依赖信息判断是否存在日志缺失(所依赖的其他节点的日志包是否存在),如果存在日志缺失则会终止本次日志发送,备库不会因为无法等到其他节点的日志出现重演卡住的情况。
2.7.5.2.2 DMDSC 集群作为备库
当 DMDSC 集群作为备库时,只由集群内的一个节点进行日志重演,主库的归档配置中包含了备库 DMDSC 集群内所有节点,主库发送归档之前需要确定其中一个节点作为归档目标,称为重演实例。非重演实例收到重做日志直接报错处理。
DM 规定将 DMDSC 备库的控制实例作为重演实例。非控制节点生成的 PWR 日志会正常写入归档文件,以保障后续切换为主库时能够构建出有效的日志包依赖关系。
2.7.6 守护控制文件
控制守护进程检测到本地 DMDSC 集群分裂时,会自动在 dm.ini 的 SYSTEM_PATH 路径下创建 dmwatcher.ctl 文件,记录 Split 分裂状态和分裂描述信息。如果数据库控制节点发生切换,控制守护进程也随之切换,新的控制守护进程从 SYSTEM_PATH 目录加载 dmwatcher.ctl 文件。因此,为了保证所有守护进程能访问 dmwatcher.ctl 文件,要求 SYSTEM_PATH 必须配置在共享存储上。
2.7.7 DMDSC 集群的管理规则
2.7.7.1 控制守护进程的认定
控制节点本地的守护进程就是控制守护进程。
一旦控制节点故障,并且选出新的控制节点后,原控制守护进程降级为普通守护进程。
普通守护进程一直保持在 Startup 状态下,控制守护进程可以进行各种状态切换。
监视器部分命令比如 Show 命令、Startup database 命令等执行时,可能 DMDSC 所有节点都不是活动状态,此时需要选出一个 dmwatcher 作为控制守护进程,对此制定如下规则:
-
控制节点状态正常,并且本地的 dmwatcher 是活动的,则直接选择此节点的 dmwatcher 为控制守护进程。
-
控制守护进程降级或者故障,系统中还存在其他活动的 dmwatcher,系统将按照下面的原则自动选择控制守护进程。
- 控制节点本地的 dmwatcher 正常(控制节点发生故障导致降级),并且和其他活动 dmwatcher 上记录的控制节点信息一致(DMDSC 集群还未选出新的控制节点),则仍然选择降级后的控制守护进程作为新的控制守护进程。一旦选出新的控制节点,那么新的控制节点的守护进程为控制节点守护进程,原控制守护进程将降级。
- 控制节点本地的 dmwatcher 故障(控制节点可能故障也可能正常),其余活动 dmwatcher 上记录的控制节点信息一致,则在所有活动 dmwatcher 中,找出记录的 FSEQ/FLSN 最大的 dmwatcher 作为控制守护进程,如果所有 dmwatcher 上记录的 FSEQ/FLSN 信息相同,则返回本地 ep seqno 最小的 dmwatcher 作为控制守护进程。
-
所有 dmwatcher 都发生故障(控制节点可能故障也可能正常),系统将按照下面的原则自动选择控制守护进程。
- 这些故障 dmwatcher 上的控制节点信息一致,则从曾经收到的历史消息中取控制节点本地的故障 dmwatcher 作为控制守护进程(退出整个 DMDSC 集群及 dmwatcher 的情况)。
- 这些故障 dmwatcher 上的控制节点信息不一致,则取最后一次收到过消息的 dmwatcher 作为控制守护进程,monitor 可以从这个 dmwatcher 上取出最新的 ep 信息。
2.7.7.2 守护进程名与实例名的对应关系
守护进程守护的本地实例名,称为守护进程名。
单节点的守护进程名,就是单节点的实例名。
对于 DMDSC 库的守护进程,由于收到的远程守护进程实例消息都是控制守护进程发送过来的,控制守护进程守护的是 DMDSC 控制节点,因此远程守护进程名也就是远程 DMDSC 库的控制节点实例名。
2.7.7.3 DMDSC 库模式和状态的认定
同一个 DMDSC 集群内,理论上所有节点实例的模式是相同的,因为修改模式的动作是同步执行的,登录任意一个节点就可以完成所有节点的模式修改,但修改状态的动作是异步的,DMDSC 集群允许不同的节点工作在不同的状态下,为了方便管理整个 DMDSC 集群,守护进程将 DMDSC 集群看作一个库,按照以下规则来认定 DMDSC 集群当前的模式和状态。
DMDSC 库获取模式和状态规则:
- 主实例还未选出,或者不存在正常的实例,则无法判断模式状态。
- 只根据 OK 数组中的节点来判断模式状态,在获取节点状态时要求 DMDSC 集群处于 Open 状态。
- 如果存在模式不同的实例,则无法判断。
- 如果存在非 Suspend/Mount/open 状态的节点实例,则直接返回此节点状态作为 DMDSC 集群状态。
- 如果实例状态不一致,则按照优先级方式确定 DMDSC 集群当前的状态,Suspend 状态优先级最高,Mount 次之,Open 最低。
根据以上规则,如果无法认定 DMDSC 集群模式,则认为 DMDSC 集群为 Unknown 模式,如果无法认定 DMDSC 集群状态,则认为 DMDSC 集群当前为 Shutdown 状态。
如果节点状态不一致,守护进程按照优先级规则判定当前 DMDSC 集群应该处于什么状态(见下表),并将所有节点统一到这个状态。在各节点状态统一一致后,守护进程再根据本地和远程状态进一步处理,如执行命令、自动恢复、故障处理等。
此表格第一行、第一列为节点状态,中间内容为不同行、列组合下守护进程经判定之后的状态,具体的场景介绍请参考 2.7.8 故障场景说明小节。
需要注意的是,如果一个节点为 Open,一个节点为 Mount,并且 Mount 状态的节点是故障重加入的节点,则守护进程会直接通知此节点 Open,而不是先统一到 Mount 状态,再进行 Open。
2.7.7.4 DMDSC 故障检测时间与守护进程故障认定时间
DMDSC 集群出现节点故障,活动节点一旦检测到 MAL 链路出现异常,立即启动故障处理,进入 HPC_CRASH_RECV 状态。判断 MAL 链路异常,涉及到 MAL 配置中链路检测 MAL_CHECK_INTERVAL 参数。
守护进程根据 INST_ERROR_TIME 配置的时间超时检测实例是否故障,守护进程的故障处理优先级低于 DMDSC 的故障处理,也就是 INST_ERROR_TIME 值至少要大于 DMDSC 故障检测时间和 MAL 链路检测时间中的最小值,否则守护进程启动时会强制调整 INST_ERROR_TIME 值 > min(DMDSC 故障检测时间, MAL_CHECK_INTERVAL) + 5,避免守护进程早于 DMDSC 集群内部故障检测时间,过早认定实例故障。
2.7.7.5 DMDSC 库 OK/ERROR 的认定
认定原则如下:
- 如果找不到控制节点,则认为 ERROR;
- 如果在 DMDSC 的 OK_EP 数组中,存在非 OK 状态的实例,则认为 ERROR;
- 其余情况认为 DMDSC 库是 OK 的。
2.7.7.6 接收 DMDSC 库消息超时
守护进程根据 inst_error_time 值判断接收本地库消息是否出现超时:若控制节点还未选出,认为 DMDSC 集群还未启动正常,则认定为消息超时;只要 DMDSC 库内有一个实例的消息未超时,就认为消息未超时。
2.7.7.7 接收远程守护进程消息超时
下面几种情况认为接收远程守护进程消息超时:
- 如果守护进程的链路已经断开,认为超时;
- 如果接收远程守护进程消息超过配置的 DW_ERROR_TIME 时间,则认为超时。
如果判断为消息超时,则设置远程守护为 ERROR 状态。
2.7.7.8 SSEQ/SLSN 和 KSEQ/KLSN 的获取
- SSEQ/SLSN 的获取
对于主库,这个值取的是主库实例的 FSEQ 和 FLSN。如果主库是 DMDSC 集群,则取出的 SSEQ/SLSN 是一个数组,对应存放的是每一个节点实例的 FSEQ 和 FLSN,数组长度和主库节点个数一致。
对于备库,这个值取的是备库明确可重演到的最大 GSEQ 值和最大 LSN 值。如果主库是 DMDSC 集群,则对应取出的也是一个数组,数组个数和主库节点个数一致。
- KSEQ/KLSN 的获取
对于主库,这个值取的是主库实例的 CSEQ 和 CLSN。如果主库是 DMDSC 集群,则取出的 CSEQ/CLSN 是一个数组,对应存放的是每一个节点实例的 CSEQ 和 CLSN,数组长度和主库节点个数一致。
对于备库,这个值取的是备库已经收到、未明确是否可以重演的最大 GSEQ 值和最大 LSN 值。如果主库是 DMDSC 集群,则对应取出的也是一个数组,数组个数和主库节点个数一致。
2.7.7.9 DMDSC 主库发送归档异常
守护进程可以通过配置参数 RLOG_SEND_THRESHOLD 监控主库到备库的归档发送情况。如果主库是 DMDSC 集群,则需要统计主库每个节点到备库控制节点的归档发送情况。DMDSC 集群中,主库任意一个节点归档发送异常,就认为出现异常,需要切换到 STANDBY check 状态下对归档发送异常的备库进行处理。
异常判断前提:
1.RLOG_SEND_THRESHOLD 参数配置值大于 0。
2.存在有归档处于有效状态的备库,对 DMDSC 集群,只需要主库任意一个节点实例到备库的归档有效即可。
异常判断规则:
主库最近 N 次(N 不超过主库 dm.ini 设置的 RLOG_SEND_APPLY_MON 值)到某个归档状态有效的备库发送归档的平均耗时超过设置的 RLOG_SEND_THRESHOLD 值。对 DMDSC 集群,如果当前守护进程处于 Recovery 状态,则只看控制节点到备库的归档发送情况。
2.7.7.10 DMDSC 备库重演异常
守护进程可以通过配置参数 RLOG_APPLY_THRESHOLD 监控备库的日志重演情况。当备库达到异常判断前提时,系统会对备库启动异常判断。如果备库达到异常判断规则中的情况,则认为备库异常。
异常判断前提:
1.RLOG_APPLY_THRESHOLD 参数配置值大于 0。
2.备库上已经选出控制节点(重演实例),且存在重演的信息。
异常判断规则:
备库最近 N 次(N 不超过备库 dm.ini 设置的 RLOG_SEND_APPLY_MON 值)的平均等待时间加上真正的平均重演时间超过设置的 RLOG_APPLY_THRESHOLD 值,则认为备库异常。
2.7.7.11 DMDSC 备库重演相关判断
备库的重演实例(控制节点)上维护了和主库各节点(单机主库只则只有一个节点)相对应的重演信息,如果重演信息的 KSEQ 大于 SSEQ,就认为存在 KEEP_RLOG_PKG。DSC 备库非控制节点不维护重演信息,因此备库非控制节点的 LSN、SEQ 等信息不会及时更新。备库的重演情况以 show 命令中展示的重演相关字段为准,各节点自己的 FSEQ/FLSN 不完全准确。
在故障备库恢复,守护进程判断其是否可加入主备系统时,守护进程会判断备库的重演实例是否重演完成,根据备库重演到的 RSEQ/RLSN 和 SSEQ/SLSN 进行比较、备库联机日志已写入的 ASEQ/ALSN 和 SSEQ/SLSN 进行比较;如果都相等,说明重演完成,这里不考虑是否存在 KEEP_RLOG_PKG,备库的 KEEP_RLOG_PKG 会在重加入前丢弃。
可以在备库重演实例上查询相关动态视图查看重演进度,包括 V$KEEP_RLOG_PKG、V$RAPPLY_SYS、V$RAPPLY_LOG_TASK、V$RAPPLY_PARALLEL_INFO 等。
2.7.7.12 DMDSC 备库退出节点
当 DMDSC 集群作为备库时,不支持仅退出集群中的单个节点。当用户针对 DMDSC 备库执行退出单节点命令时,DMDSC 备库所有节点将一起退出。
2.7.8 故障场景说明
DMDSC 数据守护环境比单节点数据库更加复杂,增加了一些额外的处理逻辑,本小节针对 DMDSC 数据守护使用场景进行说明。
2.7.8.1 DMDSC 实例状态不一致
- Mount/Open 状态
按照“2.7.7.3 DMDSC 库模式和状态的认定”的表格,这种情况的目标状态应该是 Mount,但是在 DMDSC 控制节点为 Open 状态,其他 Mount 状态的故障节点恢复,执行故障重加入时,直接将重加入的节点从 Mount 切换到 Open 状态,减少不必要的状态切换。
- Suspend/Open 状态
DMDSC 主库的某个实例发送实时或即时归档失败切换为 Suspend 状态,通知其他节点切换为 Suspend 状态前,系统各个实例状态在短时间内不一致,最终会自动统一为 Suspend 状态。这种归档失败引起的 Suspend 状态切换,由 DMDSC 实例自主完成。
- Open/Suspend 状态
DMDSC 主库同步历史数据到备库,转入 Suspend 状态同步所有归档日志后,修改备库归档状态为有效,并重新 Open 主库。控制节点先 Open 成功,普通节点 Open 失败(出现实时备库故障、网络异常、备库日志校验失败等原因),导致 DMDSC 主库各实例处于不一致状态。
守护进程会启动相应的处理流程,将所有实例切换为 Suspend 状态,失效归档以后,再重新 Open。
- Mount/Suspend 状态
主备库 switchover 流程中,切换 DMDSC 主库为 Mount 状态过程中,当节点 DSC01 切换成 Mount,DSC02 还处于 Open 状态时,出现备库故障。DSC02 归档失败,切换为 Suspend 状态,导致出现 Mount/Suspend 状态组合。
由于服务器不支持 Suspend 和 Mount 状态间的切换,既无法将所有实例直接切换为 Mount 状态,也不能将所有实例直接切换为 Suspend 状态。守护进程的处理流程是,将所有 DMDSC 实例的归档失效后,先将 Suspend 状态实例重新 Open,再将 Mount 实例重新 Open,最终将所有实例状态统一为 Open 状态。
2.7.8.2 DMDSC 备库日志重演相关实例故障
DMDSC 集群作为备库,在日志重演过程中出现故障的处理方法。
2.7.8.2.1 重演实例故障
如果 DMDSC 备库控制节点(重演实例)故障,则主库会因为发送归档失败而挂起,DMDSC 备库需要重新选举控制节点,待新的控制节点选举出来后,当前 DMDSC 备库相当于存在非重演实例故障,针对该场景的相关说明请参考 2.7.8.2.2 非重演实例故障。
2.7.8.2.2 非重演实例故障
如果 DMDSC 备库普通节点故障,重演实例可以正常接收主库日志,但 DMDSC 故障处理过程中,挂起工作线程等操作可能会导致日志重演挂起;备库重做 Redo 日志,可能需要访问故障节点的 GBS 等全局资源,也可能导致日志重演卡住。也就是说,虽然备库重演实例处于正常状态,但备库的日志重演仍然可能挂起。如果主库归档保持有效状态,继续发送 Redo 日志到备库,就有可能引发备库日志堆积,在 Redo 日志堆积过多情况下,还会导致主库日志延迟刷盘,进而影响主库的系统服务。
因此,在备库非重演实例故障时,守护进程也会进入 Failover 状态,启动故障处理,通知主库将实时、即时归档失效。在下述场景,守护进程会启动故障处理:
- DMDSC 备库实例间 MAL 链路异常。
- DMDSC 普通实例收到 Redo 日志,直接报错返回。
- DMDSC 集群系统不是 DSC_OPEN 状态,直接报错返回。
2.7.8.3 主备库网络异常
主备库之间网络出现异常时,主库发送归档失败,导致主库节点挂起,如果主库是 DMDSC 集群,任何一个节点挂起,都会通知其他节点同步挂起(参考 2.7.8.1 DMDSC 实例状态不一致),守护进程会自动将主库转入 Failover 状态处理。
2.7.8.4 DMDSC、守护进程、监视器的并发处理
DMDSC 数据守护中,DMDSC 集群内部故障处理、故障节点重加入、守护进程 Failover 处理、Recovery 处理、监视器命令等可能会并发操作。为了确保在并发场景下各种命令能正确地执行,DM 增加了命令执行的中断机制,并为每个命令分配了不同的执行优先级。
各种操作标记说明如下表:
| 序号 | 标记名称 | 操作说明 |
|---|---|---|
| 1 | DSC_CRASH_RECV | DSC 故障处理 |
| 2 | DSC_ERR_EP_ADD | DSC 故障重加入 |
| 3 | DW_FAILOVER | 守护进程故障处理 |
| 4 | DW_STDBY_CHECK | 守护进程异常检测 |
| 5 | DW_RECOVERY | 守护进程备库恢复 |
| 6 | MON_SWITCHOVER | 监视器主备切换命令 |
| 7 | MON_TAKEOVER | 监视器接管命令 |
| 8 | MON_OPEN_FORCE | 监视器 OPEN 命令 |
| 9 | MON_CLEAR_SEND_INFO | 监视器清理主库归档发送信息命令 |
| 10 | MON_CLEAR_RAPPLY_INFO | 监视器清理备库重演信息命令 |
| 11 | MON_LOGIN_CHECK | 监视器登录命令 |
| 12 | MON_MPPCTL_UPDATE | 监视器更新 MPPCTL 命令 |
| 13 | MON_CHANGE_ARCH | 监视器设置归档命令 |
| 14 | NONE | 没有任何命令执行标记 |
这些操作的优先级由高到低排序为:
- DMDSC 故障处理(CRASH_RECV)优先级最高。
- ERR_EP_ADD/FAILOVER/STANDBY check/监视器上需要和服务器交互的命令(可以被 CRASH_RECV 中断)。
- RECOVERY(可以被以上操作中断)。
其他守护进程状态以及不需要和服务器交互的监视器命令,不需要进行并发控制。
2.7.8.5 DMDSC 主动宕机场景
以下一些场景会导致 DMDSC 实例主动宕机:
- dmasmsvr 故障,对应节点实例会主动宕机。
- 处于 Suspend 或 Mount 状态下,出现节点故障。
- 启动过程中,检测到 INI 参数 TS_MAX_ID 配置不一致,可能引发强制宕机。
- 故障重启后,没有将所有重做 Redo 日志修改的数据页刷盘前(控制节点的 CKPT_LSN 小于最大重做 LSN),控制节点故障,所有普通节点主动宕机。
2.7.8.6 DMDSC 集群节点故障
2.7.8.6.1 DMDSC 主库故障
如果 DMDSC 集群作为主库,当主库 DMDSC 集群内出现节点故障(不论是控制节点故障,还是非控制节点故障)时,DMDSC 集群会等待监视器确认后进行故障处理或者直接进行故障处理。
当满足以下条件时,DMDSC 集群会等待监视器确认后进行故障处理:
-
当前 DMDSC 集群处于 PRIMARY 模式,配置了 REALTIME 或 TIMELY 归档,并且守护进程处于自动切换模式;
-
上述 REALTIME 或 TIMELY 归档中至少存在一个同时满足以下条件的归档:
- 归档状态为 VALID;
- 当前主库到该备库的网络连接全部断开。
如果同时满足上述两个条件,则 DMDSC 主库在开始故障处理之前,会先等待监视器进行确认。若监视器确认通过,则 DMDSC 主库开始进行故障处理,具体故障处理流程请参考《DM8 数据共享集群》中 DMDSC 故障处理章节;若确认未通过或者超过一定时间没有收到监视器的确认消息,则 DMDSC 主库所有节点会主动退出,超时时间为 DSC_SLOT_WAIT_TIMEOUT/3,且最多不超过 10S,最少不低于 5S。
如果不能同时满足上述两个条件,则 DMDSC 主库会直接进行故障处理,不等待监视器确认。
上述确认机制可以有效避免在已经有备库接管成了新主库的情况下,老主库再去进行故障处理产生新的日志,从而导致集群分裂的情况。
主库 DMDSC 故障处理期间:由于实时归档先发送 Redo 日志到备库,再写入本地的联机日志文件,DMDSC 主库出现节点故障时,控制守护进程需要根据故障节点的 LSN 情况,通知备库丢弃或者应用 KEEP_RLOG_PKG。而即时归档先将 Redo 日志写入本地的联机日志文件,再发送到备库,因此主库故障节点可能存在已写入日志文件,但未发送到备库的 Redo 日志。因此 DSC 主库故障处理时会根据不同备库归档类型对备库的归档状态进行处理,对于实时备库,DSC 主库进行故障处理时,不会失效备库的归档状态,以避免 DSC 主库故障处理过程中又发生故障后,备库由于归档状态失效无法再进行自动接管。对于即时归档,DSC 主库会在故障处理时收集故障 ep 的刷盘信息和备库的重演信息进行对比,若 ep 的刷盘信息大于备库的重演信息,会将备库的归档状态设置为失效,否则保持有效。备库清理 KEEP_RLOG_PKG 时,会增加清理 dps 依赖信息,同时唤醒对应 dps_slot,清理掉对应的日志包,并截断归档日志。
主库 DMDSC 故障节点重启后,正常进行 DMDSC 节点重加入流程,参考《DM8 数据共享集群》中 DMDSC 节点重加入章节。
主库 DMDSC 节点重加入期间,主库的备库归档一直处于归档失效状态。主库节点重加入流程处理完成后,由主库守护进程重新启动恢复流程,同步主备库数据。
2.7.8.6.2 DMDSC 备库故障
如果 DMDSC 集群作为主库,当备库 DMDSC 集群内出现节点故障,则不需要等待监视器确认,正常进行 DMDSC 故障处理流程,参考《DM8 数据共享集群》中 DMDSC 故障处理章节。其中,备库 DMDSC 故障处理流程和非备库 DMDSC 故障处理有以下差异:
- 如果是备库 DMDSC 非控制节点故障,备库 DMDSC 控制节点故障处理流程不需要重做节点联机日志。
- 如果是备库 DMDSC 控制节点故障,新的控制节点故障处理流程需要重做节点联机日志。
- 备库 DMDSC 故障处理流程(不论是控制节点故障,还是非控制节点故障)一律不需要收集回滚段,不需要处理活动事务回滚和已提交事务清理动作。
备库 DMDSC 故障处理期间,主库会将备库归档失效,备库 DMDSC 故障处理完成后,由主库守护进程重新启动恢复流程,同步主备库数据。
备库 DMDSC 故障节点重启后,正常进行 DMDSC 节点重加入流程,参考《DM8 数据共享集群》中 DMDSC 节点重加入章节。
备库 DMDSC 节点重加入期间,主库会将备库归档失效,备库节点重加入流程处理完成后,由主库守护进程重新启动恢复流程,同步主备库数据。
备库 DMDSC 节点重加入,不会改变 DMDSC 控制节点。
2.8 异步备库
异步备库一般用于历史数据统计、周期报表等对数据实时性要求不高的业务场合。异步归档时机可以选择在源库空闲的时候,可避免源库的业务高峰期同步数据对性能的影响。
每个 PRIMARY 或者 STANDBY 模式的库(订阅备库除外)都可以配置最多 8 个异步备库。配置了异步备库的 PRIMARY 或者 STANDBY 模式的库(订阅备库除外),统称为源库。可以在实时主备、MPP 主备、DMDSC 主备和读写分离集群的主库和备库(订阅备库除外)上配置异步备库,异步备库可级联配置,异步备库本身也可以作为源库配置异步备库。一个监视器最多可以同时监视 16 个异步备库。
配置了 Realtime 和 Timely 归档的主备库,允许配置同一个异步备库,也就是说一个异步备库允许有多个源库。系统自动识别,PRIMARY 模式的源库负责向异步备库同步数据,主备库切换后,由新主库负责向异步备库同步数据。这种多源配置的异步备库,可以保证异步备库始终与当前的有效主库保持数据同步。但是,未配置 Realtime 和 Timely 归档的库,不能配置同一个异步备库。对于级联方式配置的异步备库,也就是异步备库自己作为源库的情况下,仍然需要由用户保证配置的正确性,避免数据同步异常。错误配置多个源库的情况下,多个源库可能同时、或交错向异步备库发送归档日志,导致备库日志连续性校验失败。
异步备库支持延时和定点重演功能,相关使用场景及使用说明请参考 6.25 异步备库延时和定点重演。
配置异步备库十分简单,在源库的 dm.ini 中打开定时器 TIMER_INI 开关,同时配置文件 dmtimer.ini,在 dmarch.ini 中增加异步归档配置,在 dmmal.ini 中增加异步备库的 mal 配置,由定时器定时触发源库发送归档日志到异步备库即可。详细的配置示例请参考 7.6 配置异步备库。异步备库可以不配置本地归档。
下图中,“源库 P”表示 PRIMARY 模式的库,“源库 S”表示 STANDBY 模式的库,“源库 S”上允许配置到同一个异步备库的异步归档,但只有“源库 P”会向异步备库同步数据,对于级联方式配置的异步备库,不允许有多个源库。
2.9 同步备库
同步备库一般用于对主库性能要求较高,想要避免因备库故障或异步恢复引发的 Suspend 状态切换,但又希望备库的数据延迟不要太大的场合。与实时归档相比,同步归档时机为主库本地归档刷盘之后,主库发送归档到同步备库失败时,不会切换为 Suspend 状态,而是直接将备库的归档状态设置为无效。
同步备库不支持级联配置。PRIMARY 模式的库可以配置最多 8 个同步归档,而 STANDBY 模式的库只有在配置了实时/即时归档的情况下才允许配置同步归档,这种情况下同样最多可以配置 8 个同步归档。可以在满足上述条件的单机、实时主备、MPP 主备、读写分离集群的实例上配置同步备库。只有 PRIMARY 模式的库会向同步备库发送数据,STANDBY 模式的库即使配置了同步归档也不会生效。
与异步备库相似,同步备库的守护进程也需要配置为 LOCAL 类型,因此同步备库不支持主备库切换、备库接管等操作。若有将同步备库切换为主库的需要,可以手动执行 sql 语句将其切换为 PRIMARY 模式,但此时数据守护系统并不能保证该操作的正确性,需要由用户自身确认。
配置了 Realtime 和 Timely 归档的主备库,允许配置同一个同步备库。系统自动识别,PRIMARY 模式的库负责向同步备库同步数据,主备库切换后,由新主库负责向同步备库同步数据。这种多源配置的同步备库,可以保证同步备库始终与当前的有效主库保持数据同步。Raft 和 Remote 归档不能与同步归档共存,并且当整个归档配置文件中存在归档目标为 DSC 库的配置项时,也不能再配置同步归档,反之亦然。
配置同步备库十分简单,在 dmarch.ini 中增加同步归档配置,在 dmmal.ini 中增加同步备库的 mal 配置项即可。详细的配置示例请参考 7.7 配置同步备库小节。同步备库可以不配置本地归档。
2.10 Huge 表
DM 的 Huge 表存储使用独立的存储机制,分别存储在数据文件和辅助表中。数据文件以数据区为单位进行管理,一个数据区可以存储单列数据的若干行,辅助表则是普通的行表,用于存放控制信息或者部分 Huge 表数据。
Huge 表又分为非事务型 Huge 表和事务型 Huge 表,其中非事务型 Huge 表不具备事务特性,因此数据守护 V4.0 不再对这种类型的 Huge 表进行支持,仅支持事务型 Huge 表的主备数据同步。
数据守护 V4.0 支持对事务型 Huge 表生成普通的 Redo 日志,和普通行表采用相同的数据同步机制,备库可以直接通过重演 Redo 日志来完成 Huge 表数据的同步,并且不区分实时主备、读写分离集群或者 MPP 主备,这三类数据守护系统都可以支持此功能,由于 Huge 表特殊的存储及管理方式,DMDSC 集群目前无法支持 Huge 表,也就是仅限于在单节点的数据守护系统中使用 Huge 表。
需要注意的是,在搭建数据守护系统时,需要将建库参数 HUGE_WITH_DELTA 和 RLOG_GEN_FOR_HUGE 都配置为 1,才能够正常生成 Huge 表 Redo 日志并发送给备库重演。对升级上来的老的数据守护系统,这两个建库参数则按照 0 值处理,Huge 表不会生成 Redo 日志并且不支持主备数据同步。