DM_SQL 语言的数据更新语句包括:数据插入、数据修改和数据删除三种语句,其中数据插入和修改两种语句使用的格式要求比较严格。在使用时要求对相应基表的定义,如列的个数、各列的排列顺序、数据类型及关键约束、唯一性约束、引用约束、检查约束的内容均要了解得很清楚,否则就很容易出错。下面将分别对这三种语句进行讨论。在讨论中,如不特别说明,各例均使用示例库 BOOKSHOP,用户均为建表者 SYSDBA。
5.1 数据插入语句
数据插入语句用于向已定义好的表中插入单个或成批的数据。
INSERT 语句有两种形式。一种形式是值插入,即构造一行或者多行,并将它们插入到表中;另一种形式为查询插入,它通过<查询表达式>返回一个查询结果集以构造要插入表的一行或多行。
数据插入语句的语法格式如下:
语法格式
<插入表达式>::=
[<WITH 子句>] INSERT {<single_insert_stmt> | <multi_insert_stmt>};
<WITH 子句> ::= [<WITH FUNCTION子句>] [WITH CTE子句] 参见4.4 WITH 子句
<single_insert_stmt>::=[INTO] <full_tv_name> [<t_alias>] <insert_tail> [<return_into_obj>]
<full_tv_name>::= <tv_name> | <子查询表达式>
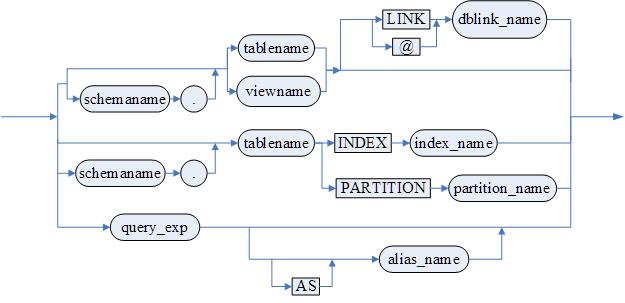
<tv_name>::= <单表引用> [@ <dblink_name>]
| [<模式名>.]<基表名> INDEX <索引名>
| [<模式名>.]<基表名> PARTITION (<分区名>)
<单表引用>::=[<模式名>.]<基表或视图名>
<基表或视图名>::=<基表名>|<视图名>
<子查询表达式>::=(<查询表达式>) [[AS] <表别名>]
<t_alias>::=[AS] <表别名>
<insert_tail>::= [(<列名>{,<列名>})]<insert_action>
<insert_action>::= VALUES <ins_value>
| <查询表达式>|(<查询表达式>)
| DEFAULT VALUES
| TABLE <tv_name>
<return_into_obj>::=
<RETURN | RETURNING> <列表达式>{,<列表达式>} INTO <结果对象>{,<结果对象>} |
<RETURN | RETURNING> <列表达式>{,<列表达式>} BULK COLLECT INTO <结果对象>{,<结果对象>}
<查询表达式>::=参见第四章
<结果对象>::= <数组>|<变量>
<multi_insert_stmt>::=ALL <multi_insert_into_list> <查询表达式>
|[ALL|FIRST]<multi_insert_into_condition_list> [<multi_insert_into_else>]<查询表达式>
<multi_insert_into_list>::= <insert_into_single>{<insert_into_single>}
<insert_into_single>::=
INTO <tv_name> [<t_alias>] [(<列名>{,<列名>})][VALUES <ins_value>]
<ins_value>::=
(<expr>|DEFAULT|<查询表达式> {,<expr>|DEFAULT|<查询表达式>}){,(<expr>|DEFAULT|<查询表达式> {,<expr>|DEFAULT|<查询表达式>})}
<multi_insert_into_condition_list> ::=
<insert_into_single_condition>{,< insert_into_single_condition>}
<insert_into_single_condition>::=
WHEN <bool_exp> THEN <multi_insert_into_list>
<multi_insert_into_else>::= ELSE <multi_insert_into_list>
参数
- <模式名> 指明该表或视图所属的模式,缺省为当前模式;
- <基表名> 指明被插入数据的基表的名称;
- <视图名> 指明被插入数据的视图的名称,实际上 DM 将数据插入到视图引用的基表中;
- <列名> 表或视图的列的名称。在插入的记录中,这个列表中的每一列都被 VALUES 子句或查询说明赋一个值。如果在此列表中省略了表的一个列名,则 DM 用先前定义好的缺省值插入到这一列中。如果此列表被省略,则在 VALUES 子句和查询中必须为表中的所有列指定值;
- <ins_value> 指明在列表中对应的列的插入的列值,如果列表被省略了,插入的列值按照基表中列的定义顺序排列。所有的插入值和系统内部相关存储信息一起构成了一条记录,一条记录的长度不能大于页面大小的一半;
- <查询表达式> 将一个 SELECT 语句所返回的记录插入表或视图的基表中,子查询中选择的列表必须和 INSERT 语句中列名清单中的列具有相同的数量;带有<查询表达式>的插入方式,称查询插入。插入中使用的<查询表达式>也称为查询说明;
- <dblink_name> 表示创建的 dblink 名字,如果添加了该选项,则表示插入远程实例的表。
图例
<插入表达式>
<single_insert_stmt>

<full_tv_name>
<tv_name>
<insert_tail>
<return_into_obj>

<multi_insert_stmt>

<insert_into_single>

<ins_value>
<insert_into_single_condition>

使用说明
- <基表名>或<视图名>后所跟的<列名>必须是该表中的列,且同一列名不允许出现两次,但排列顺序可以与定义时的顺序不一致;
- <ins_value>中插入值的个数、类型和顺序要与<列名>一一对应;
- 插入在指定值的时候,可以同时指定多行值,这种叫做多行插入或者批量插入。多行插入不支持列存储表;
- 如果某一<列名>未在 INTO 子句后面出现,则新插入的行在这些列上将取空值或缺省值,如该列在基表定义时说明为 NOT NULL 时将会出错;
- 如果<基表名>或<视图名>后没指定任何<列名>,则隐含指定该表或视图的所有列,这时,新插入的行必须在每个列上均有<插入值>;
- 当使用<子查询表达式>作为 INSERT 的目标时,实际上是对查询表达式的基表进行操作,查询表达式的查询项必须都来源于同一个基表且不能是计算列,查询项所属的基表即是查询表达式的基表,如果查询表达式是带有连接的查询,那么对于连接中视图基表以外的表,连接列上必须是主键或者带有 UNIQUE 约束。不支持 PIVOT/UNPIVOT,不支持 UNION/UNION ALL 查询;
- 如果两表之间存在引用和被引用关系时,应先插入被引用表的数据,再插入引用表的数据;
- <查询表达式>是指用查询语句得到的一个结果集插入到插入语句中<表名>指定的表中,因此该格式的使用可供一次插入多个行,但插入时要求结果集的列与目标表要插入的列是一一对应的,不然会报错;
- 多行插入时,对于存在行触发器的表,每一行都会触发相关的触发器;同样如果目标表具有约束,那么每一行都会进行相应的约束检查,只要有一行不满足约束,所有的值都不能插入成功;
- 支持多行插入时插入查询表达式,但需要注意将子查询当做表达式使用时,需要保证子查询表达式的返回值为一行一列,否则会报错“单行子查询返回多行”或者“SELECT 语句列数超长”;
- 在嵌入方式下工作时,<ins_value>插入的值可以为主变量;
- 如果插入对象是视图,同时在这个视图上建立了 INSTEAD OF 触发器,则会将插入操作转换为触发器所定义的操作;如果没有触发器,则需要判断这个视图是否可更新,如果不可更新则报错(不可更新视图场景参见 6.6 视图数据的更新 ),否则是可以插入成功的;
- RETURN INTO 支持返回变量和方法参数;
- RETURN INTO 子句中的 < 列表达式 > 支持列名、ROWID 和函数(不包括集函数和分析函数),但是堆表不支持 ROWID 作为 < 列表达式 >;
- RETURN INTO 子句中的 < 结果对象 > 支持变量和数组。如果返回结果对象为变量,则变量类型与个数与返回列一致;如果为普通数组,则数组个数和数组元素类型与返回列一致;如果为记录数组,则只能有一个返回结果对象,且记录数组属性类型与个数须与返回列一致。返回结果不支持变量、普通数组和记录数组混和使用;
- 增删改语句当前修改表称为变异表(MUTATE TABLE),其调用函数中,不能对此变异表进行插入操作;
- BULK COLLECT 的作用是将检索结果批量地、一次性地赋给集合变量。与每次获取一条数据,并每次都要将结果赋值给变量相比,可以很大程度上的节省开销。使用 BULK COLLECT 时,INTO 后的变量必须是集合类型的;
- <multi_insert_stmt> 中可以使用 WHEN 子句指定插入条件,仅当满足指定条件时,才插入相应数据。支持同时指定多个 WHEN 子句,可以使用 ALL 或 FIRST 控制插入策略,ALL 表示插入所有满足条件的数据,FIRST 表示仅插入第一条满足条件的数据。其中若 WHEN 子句所指定的插入条件里存在列名,该列名应当在后续的 < 查询表达式 > 中进行查询,否则报错;
- 如果将 < 查询表达式 > 的结果插入到分区表中,可在 < 查询表达式 > 之前使用 HINT 提示/+ PARALLEL_INS(< 表名 >)/执行并行插入。例如 INSERT INTO t1 /+ PARALLEL_INS(< 表名 >)/ SELECT LEVEL,LEVEL FROM DUAL CONNECT BY LEVEL<=1000;。多个线程同时执行插入,可提升插入性能。具体请参考《DM8 系统管理员手册》。
举例说明
例 1 在 VENDOR 表中插入一条供应商信息:账户号为 00,名称为华中科技大学出版社,活动标志为 1,URL 为空,信誉为 2。
INSERT INTO PURCHASING.VENDOR(ACCOUNTNO, NAME, ACTIVEFLAG, WEBURL, CREDIT) VALUES ('00', '华中科技大学出版社', 1, '', 2);
如果需要同时多行插入,则可以用如下的 SQL 语句实现:
INSERT INTO PURCHASING.VENDOR(ACCOUNTNO, NAME, ACTIVEFLAG, WEBURL, CREDIT)
VALUES ('00', '华中科技大学出版社', 1, '', 2), ('00', '清华大学出版社', 1, '',3);
在定义 VENDOR 表时,设定了检查约束:CHECK(CREDIT IN(1,2,3,4,5)),说明 CREDIT 只能是 1,2,3,4,5。在插入新数据或修改供应商的 CREDIT 时,系统按检查约束进行检查,如果不满足条件,系统将会报错,多行插入中,每一行都会做检查。
由于 DM 支持标量子查询,标量子查询允许用在标量值合法的地方,因此在数据插入语句的<插入值>位置允许出现标量子查询。
例 2 将书名为长征的图书的出版社插入到 VENDOR 表中。
INSERT INTO PURCHASING.VENDOR(ACCOUNTNO, NAME, ACTIVEFLAG, WEBURL, CREDIT)
VALUES('00', (SELECT PUBLISHER FROM PRODUCTION.PRODUCT WHERE NAME ='长征'),1, '', 1);
若是需要插入一批数据时,可使用带<查询说明>的插入语句,如下例所示。
例 3 构造一个新的基表,表名为 PRODUCT_SELL,用来显示出售的商品名称和购买用户名称,并将查询的数据插入此表中。
CREATE TABLE PRODUCTION.PRODUCT_SELL
( PRODUCTNAME VARCHAR(50) NOT NULL,
CUSTOMERNAME VARCHAR(50) NOT NULL);
INSERT INTO PRODUCTION.PRODUCT_SELL
SELECT DISTINCT T1.NAME , T5.NAME
FROM PRODUCTION.PRODUCT T1, SALES.SALESORDER_DETAIL T2,
SALES.SALESORDER_HEADER T3, SALES.CUSTOMER T4,
PERSON.PERSON T5
WHERE T1.PRODUCTID = T2.PRODUCTID AND T2.SALESORDERID = T3.SALESORDERID
AND T3.CUSTOMERID = T4.CUSTOMERID AND T4.PERSONID = T5.PERSONID;
该插入语句将已销售的商品名称和购买该商品的用户名称插入到新建的 PRODUCT_SELL 表中。查询结果如下:
PRODUCTNAME CUSTOMERNAME
----------- ------------
红楼梦 刘青
老人与海 刘青
值得一提的是,BIT 数据类型值的插入与其他数据类型值的插入略有不同:其他数据类型皆为插入的是什么就是什么,而 BIT 类型取值只能为 1/0,又同时能与整数、精确数值类型、不精确数值类型和字符串类型相容(可以使用这些数据类型对 BIT 类型进行赋值和比较),取值时有一定的规则。
数值类型常量向 BIT 类型插入的规则是:非 0 数值转换为 1,数值 0 转换为 0。例如:
CREATE TABLE T10 (C BIT);
INSERT INTO T10 VALUES(1); //插入1
INSERT INTO T10 VALUES(0); //插入0
INSERT INTO T10 VALUES(1.2); //插入1
字符串类型常量向 BIT 类型插入的规则是:
全部由 0 组成的字符串或表示 0 的科学计数字符串(如 0e0)转换为 0,其他全数字字符串(例如:123) 或表示非 0 的科学计数字符串转换为 1。
INSERT INTO T10 VALUES(000); //插入0
INSERT INTO T10 VALUES(0); //插入0
INSERT INTO T10 VALUES(10); //插入1
INSERT INTO T10 VALUES(1.0); //插入1
例 4 多行插入时插入查询表达式。
CREATE TABLE T (ID INT, NAME CHAR(50));
CREATE TABLE T1 (ID INT, NAME CHAR(50));
INSERT INTO T1 VALUES(2,'ALICE'),(1,'TOM');
INSERT INTO T VALUES((SELECT ID FROM T1 WHERE NAME='ALICE'),(SELECT NAME FROM T1 WHERE ID=1)),((SELECT ID FROM T1 WHERE NAME='ALICE'),(SELECT NAME FROM T1 WHERE ID=1)),((SELECT ID FROM T1 WHERE NAME='ALICE'),(SELECT NAME FROM T1 WHERE ID=1));
SELECT * FROM T;
查询结果如下:
行号 ID NAME
---------- ----------- --------------------------------------------------
1 2 TOM
2 2 TOM
3 2 TOM
例 5 创建一个表 BOOK_20 用于记录当前价格小于 20 的书本的名称、原价、当前价格和折扣,同时创建一个表 BOOK_30 用于记录当前价格大于 30 的书本的名称、原价、当前价格和折扣。通过使用 WHEN 子句指定条件进行数据插入。
CREATE TABLE BOOK_20(NAME VARCHAR(50), ORIGINALPRICE DEC(19,4),NOWPRICE DEC(19,4),DISCOUNT DECIMAL(2,1));
CREATE TABLE BOOK_30(NAME VARCHAR(50), ORIGINALPRICE DEC(19,4),NOWPRICE DEC(19,4),DISCOUNT DECIMAL(2,1));
INSERT ALL WHEN NOWPRICE < 20 THEN INTO BOOK_20 WHEN NOWPRICE > 30 THEN INTO BOOK_30 SELECT NAME, ORIGINALPRICE, NOWPRICE, DISCOUNT FROM PRODUCTION.PRODUCT;
SELECT * FROM BOOK_20;
SELECT * FROM BOOK_30;
BOOK_20 表查询结果如下:
行号 NAME ORIGINALPRICE NOWPRICE DISCOUNT
---------- ---------------- ------------- -------- --------
1 红楼梦 19 15.2 8
2 水浒传 19 14.3 7.5
3 老人与海 10 6.1 6.1
4 工作中无小事 16.8 11.4 6.8
5 突破英文基础词汇 15.9 11.1 7
BOOK_30 表查询结果如下:
行号 NAME ORIGINALPRICE NOWPRICE DISCOUNT
---------- ------------------- ------------- -------- --------
1 长征 53 37.7 6.4
2 噼里啪啦丛书(全7册) 58 42 6.1
5.2 数据修改语句
数据修改语句用于修改表中已存在的数据。
语法格式
[<WITH子句>] UPDATE <更新列表> {<单列修改子句>|<多列修改子句>}[FROM <表引用>{,<表引用>}]
[WHERE <条件表达式>][<return_into_obj>][<LIMIT限定条件>];
<WITH 子句>::=请参考第4.4节 WITH 子句
<更新列表>::=<表引用>{,<表引用>}
<单列修改子句>::= SET<列名>=<<值表达式>|DEFAULT>{,<列名>=<<值表达式>|DEFAULT>}
<多列修改子句>::= SET (<列名>{,<列名>}) = <子查询表达式>
<子查询表达式>::=(<查询表达式>) [[AS] <表别名>]
<表引用>::=请参考第4章 数据查询语句
<return_into_obj>::=
<RETURN | RETURNING><列表达式>{,<列表达式>}INTO <结果对象>{,<结果对象>} |
<RETURN | RETURNING><列表达式>{,<列表达式>}BULK COLLECT INTO <结果对象>{,<结果对象>}
<结果对象>::= <数组>|<变量>
<LIMIT限定条件>::= <LIMIT子句> | <ROW_LIMIT子句>
<LIMIT子句>::= LIMIT <记录数> |
LIMIT <偏移量> , <记录数> |
LIMIT <记录数> OFFSET <偏移量> |
OFFSET <偏移量> LIMIT <记录数>
<记录数>::=<整数>
<偏移量>::=<整数>
<ROW_LIMIT子句>::= [OFFSET <offset> ROW[S]] [<FETCH说明>]
<FETCH说明>::= FETCH <FIRST | NEXT> [<大小> | <大小> PERCENT] ROW[S] <ONLY | WITH TIES>
参数
1.<列名> 表或视图中被更新列的名称,如果 SET 子句中省略列的名称,列的值保持不变;
2.<值表达式 > 指明赋予相应列的新值,可以为一个 < 集函数 >、< 函数 >、< 标量子查询 > 或 < 计算表达式 > 等;
3.<条件表达式> 指明限制被更新的行必须符合指定的条件,如果省略此子句,则修改表或视图中所有的行;
4.<LIMIT 限定条件 > 指明更新数据时的限定条件,与查询语句中的 <LIMIT 限定条件 > 功能类似,具体说明可以查看[4.10 LIMIT 限定条件](#4.10 LIMIT 限定条件)。
-
1)LIMIT 子句:按顺序更新表中某条记录开始的 N 条记录。
LIMIT N:更新前 N 条记录;
LIMIT M , N:更新第 M 条记录之后的 N 条记录;
LIMIT M OFFSET N:更新第 N 条记录之后的 M 条记录;
OFFSET N LIMIT M:更新第 N 条记录之后的 M 条记录。
2)ROW_LIMIT 子句:指定更新数据时的偏移的行数。
<offset>:指定待更新数据的起始偏移。
[< 大小 > | < 大小 > PERCENT] 指定要更新的行数或者所占的百分比
图例
表引用:请参考第 4 章 数据查询语句
set_singlecol
set_manycol
return_into_obj

LIMIT 限定条件:请参考第 4 章 数据查询语句
使用说明
-
SET 后的<列名>不能重复出现;
-
WHERE 子句也可以包含子查询。如果省略了 WHERE 子句,则表示要修改所有的元组;
-
如果<列名>为被引用列,只有被引用列中未被引用列引用的数据才能被修改;如果<列名>为引用列,引用列的数据被修改后也必须满足引用完整性。在 DM 系统中,以上引用完整性由系统自动检查;
-
执行基表的 UPDATE 语句触发任何与之相联系的 UPDATE 触发器;
-
对于未指定 ENABLE ROW MOVEMENT 属性水平分区表的更新,如果更新后的值将导致记录所属分区发生修改,则不能进行更新;
-
如果更新对象是视图,同时在这个视图上建立了 INSTEAD OF 触发器,则会将更新操作转换为触发器所定义的操作;如果没有触发器,则需要判断这个视图是否可更新,如果不可更新则报错(不可更新视图场景参见 6.6 视图数据的更新 ),否则可以继续更新,如果上面的条件都满足,则可以更新成功;
-
RETURN INTO 支持返回变量和方法参数;
-
RETURN INTO 子句中的 < 列表达式 > 支持列名、ROWID 和函数(不包括集函数和分析函数),但是堆表不支持 ROWID 作为 < 列表达式 >。如果 < 列表达式 > 是更新列,则返回值为列的新值;
-
RETURN INTO 子句中的 < 结果对象 > 支持变量和数组。如果返回结果对象为变量,则变量类型与个数与返回列一致;如果为普通数组,则数组个数和数组元素类型与返回列一致;如果为记录数组,则只能有一个返回结果对象,且记录数组属性类型与个数须与返回列一致。返回结果不支持变量、普通数组和记录数组混和使用;
-
UPDATE 语句支持一次进行多列修改,多列修改存在限制:针对每行待更新数据,子查询中不能存在多行匹配的结果;若 INI 参数 MULTI_UPD_OPT_FLAG 为 0 并且更新普通表(非派生表),则相关子查询中允许存在多行匹配结果,此时根据第一行匹配结果进行更新,对于非相关子查询,不能存在多行匹配的结果;
-
如果更新为子查询,则存在以下限制:
- 更新子查询对应的最终更新对象目前仅仅必须为基表;
- 更新的子查询的查询结果必须保证所更新基表的唯一性特性,类似于更新视图是否可更新概念;
- 更新子查询中不支持包含集合操作、DISTINCT 操作、集函数操作、GROUP BY、CONNECT BY、LIMIT、TOP、ROWNUM;
- 当 MULTI_UPD_OPT_FLAG 参数取值包含 1 并且不包含 2 时,更新的子查询中不能包含多表连接。
-
增删改语句当前修改表称为变异表(MUTATE TABLE),其调用函数中,不能对此变异表进行删除操作;
-
半透明加密列支持通过 UPDATE 语句进行修改,具体介绍请参考手册《DM8 安全管理》;
-
多表联合更新说明:
- 更新列表中有多个表时,不支持使用多列修改子句;
- 更新列表中有多个表时,不允许指定 FROM 项;
- 若有多个 SET 项,则各个 SET 项的左表达式必须为同一个表对象(同一个表的不同别名认为是不同对象)的列;
- 要求用户对于更新列表的所有对象具有查询权限,对最终修改的目标对象具有修改权限;
- 多表联合更新最多支持 100 个表。
举例说明
例 1 将出版社为中华书局的图书的现在销售价格增加 1 元。
UPDATE PRODUCTION.PRODUCT SET NOWPRICE = NOWPRICE + 1.0000 WHERE PUBLISHER = '中华书局';
例 2 由于标量子查询允许用在标量值合法的地方,因此在数据修改语句的<值表达式>位置也允许出现标量子查询。下例将折扣高于 7.0 且出版社不是中华书局的图书的折扣设成出版社为中华书局的图书的平均折扣。
UPDATE PRODUCTION.PRODUCT SET DISCOUNT =
( SELECT AVG(DISCOUNT)
FROM PRODUCTION.PRODUCT
WHERE PUBLISHER = '中华书局')
WHERE DISCOUNT > 7.0 AND PUBLISHER != '中华书局';
注:自增列的修改例外,它一经插入,只要该列存储于数据库中,其值为该列的标识,不允许修改。关于自增列修改的具体情况,请参见 5.6 DM 自增列的使用。
例 3 带 RETURN INTO 的更新语句。
CREATE TABLE T1(C1 INT,C2 INT,C3 INT);
DECLARE
TYPE RRR IS RECORD(X INT, Y INT);
TYPE CCC IS ARRAY RRR[];
A INT;
C CCC;
BEGIN
C = NEW RRR[2];
UPDATE T1 SET C2=4 WHERE C3 = 2 RETURN C1 INTO A;
PRINT A;
UPDATE T1 SET C2=5 WHERE C3 = 2 RETURN C1,C2 INTO C;
SELECT * FROM ARRAY C;
END;
例 4 使用一次进行多列修改的更新语句。
UPDATE PURCHASING.PURCHASEORDER_HEADER SET(TAX,FREIGHT)=(select ORIGINALPRICE,
NOWPRICE from PRODUCTION.PRODUCT where NAME='长征');
5.3 数据删除语句
数据删除语句用于删除表中已存在的数据,支持单表删除和多表联合删除。
语法格式
[<WITH子句>] DELETE {<TOP删除子句> | <LIMIT删除子句>};
<TOP删除子句>::= <TOP单表删除子句> | <TOP多表联合删除子句>
<LIMIT删除子句>::=<LIMIT单表删除子句> | <LIMIT多表联合删除子句>
<TOP单表删除子句>::= <TOP子句> [FROM] <表引用> [WHERE <条件表达式>][<return_into_obj>]
<TOP多表联合删除子句>::= <TOP子句> [FROM] <单表引用> <多表联合删除条件> [WHERE <条件表达式>][<return_into_obj>]
<LIMIT单表删除子句>::= [FROM] <表引用> [WHERE <条件表达式>][<return_into_obj>] [<LIMIT限定条件>]
<LIMIT多表联合删除子句>::= [FROM] <单表引用> <多表联合删除条件> [WHERE <条件表达式>][<return_into_obj>][<LIMIT限定条件>]
<WITH 子句>::=请参考4.4 WITH 子句
<TOP子句>::=请参考4.9 TOP子句
<表引用>::=
[<模式名>.] {<基表或视图名>|<子查询表达式>} |
<分区表>
<基表或视图名>::= <基表名> | <视图名>
<子查询表达式>::=(<查询表达式>) [[AS] <表别名> [<新生列>]]
<分区表>::= 请参考4.21 水平分区表查询
<return_into_obj>::= <RETURN | RETURNING> <列表达式>{,<列表达式>} INTO <结果对象>{,<结果对象>}
<结果对象>::=<数组>|<变量>
<单表引用>::=
[<模式名>.] {<表别名>|<基表或视图名>} |
<分区表>
<多表联合删除条件>::= FROM <删除列表> |
USING <删除列表>
<删除列表>::= <多表联合删除表引用>{,<多表联合删除表引用>}
<多表联合删除表引用>::= <普通表>|<连接表>
<普通表>、<连接表>::=请参考第4章 数据查询语句
<LIMIT限定条件>::= <LIMIT子句> | <ROW_LIMIT子句>
<LIMIT子句>::= LIMIT <记录数> |
LIMIT <偏移量> , <记录数> |
LIMIT <记录数> OFFSET <偏移量> |
OFFSET <偏移量> LIMIT <记录数>
<记录数>::=<整数>
<偏移量>::=<整数>
<ROW_LIMIT子句>::= [OFFSET <offset> ROW[S]] [<FETCH说明>]
<FETCH说明>::= FETCH <FIRST | NEXT> [<大小> | <大小> PERCENT] ROW[S] <ONLY | WITH TIES>
参数
1.<模式名> 指明该表或视图所属的模式,缺省为当前模式;
2.<基表名> 指明被删除数据的基表的名称;
3.<视图名> 指明被删除数据的视图的名称,实际上 DM 将从视图的基表中删除数据;
4.<条件表达式> 指明基表或视图的基表中被删除的记录须满足的条件;
5.<LIMIT 限定条件 > 指明删除数据时的限定条件,与查询语句中的 <LIMIT 限定条件 > 功能类似,具体说明可以查看[4.10 LIMIT 限定条件](#4.10 LIMIT 限定条件)。
-
1)LIMIT 子句:按顺序删除表中某条记录开始的 N 条记录。
LIMIT N:删除前 N 条记录;
LIMIT M , N:删除第 M 条记录之后的 N 条记录;
LIMIT M OFFSET N:删除第 N 条记录之后的 M 条记录;
OFFSET N LIMIT M:删除第 N 条记录之后的 M 条记录。
2)ROW_LIMIT 子句:指定删除数据时的偏移的行数。
<offset>:指定待删除数据的起始偏移。
[< 大小 > | < 大小 > PERCENT] 指定要删除的行数或者所占的百分比。
图例
数据删除语句
TOP 删除子句(top_delete_clause)
TOP 单表删除子句(top_single_table_delete_clause)
TOP 多表联合删除子句(top_multi_table_delete_clause)
LIMIT 删除子句(limit_delete_clause)
LIMIT 单表删除子句(limit_single_table_delete_clause)
LIMIT 多表联合删除子句(limit_multi_table_delete_clause)
表引用(table_ref)
return_into_obj
单表引用(single_table_ref)
多表联合删除条件(multi_condition)
删除列表(delete_table_list)
LIMIT 限定条件:请参考第 4 章 数据查询语句
使用说明
-
如果不带 WHERE 子句,表示删除表中全部元组,但表的定义仍在字典中。因此,DELETE 语句删除的是表中的数据,并未删除表结构;
-
由于 DELETE 语句一次只能对一个表进行删除,因此当两个表存在引用与被引用关系时,要先删除引用表里的记录,只有引用表中无记录时,才能删被引用表中的记录,否则系统会报错;
-
执行与表相关的 DELETE 语句将触发所有定义在表上的 DELETE 触发器;
-
如果视图为不可更新视图(不可更新视图场景参见 6.6 视图数据的更新 ),则不能从视图中删除记录;
-
当 < 子查询表达式 > 作为 DELETE 的目标时,实际上是对查询表达式的基表进行操作,对于表子查询,查询表达式的查询项既可以来源于多个基表也可以是计算列,当查询项来自多个基表时,第一个满足条件的键值保存表即是最终删除数据的表;对于派生表子查询,查询表达式的查询项必须都来源于同一个基表且不能是计算列,查询项所属的基表即是查询表达式的基表。如果查询表达式是带有连接的查询,那么对于连接中视图基表以外的表,连接列上必须是主键或者带有 UNIQUE 约束。不支持 PIVOT/UNPIVOT,不支持 UNION/UNION ALL 查询;
-
RETURN INTO 支持返回变量和方法参数;
-
RETURN INTO 子句中的 < 列表达式 > 支持列名、ROWID 和函数(不包括集函数和分析函数),但是堆表不支持 ROWID 作为 < 列表达式 >;
-
RETURN INTO 子句中的 < 结果对象 > 支持变量和数组。如果返回结果对象为变量,则变量类型与个数与返回列一致;如果为普通数组,则数组个数和数组元素类型与返回列一致;如果为记录数组,则只能有一个返回结果对象,且记录数组属性类型与个数须与返回列一致。返回结果不支持变量、普通数组和记录数组混和使用;
-
增删改语句当前修改表称为变异表(MUTATE TABLE),其调用函数中,不能对此变异表进行删除操作;
-
对于多表联合删除有以下限制:
- 多表联合删除指定的删除对象,仅支持基表名、视图表、表别名,不支持子查询、连接表等,也不支持远程表;
- 删除列表中应包含指定的删除对象,如果在删除列表中声明了别名,指定删除对象时也应该使用别名;
- 多表联合删除时要求对删除列表中的所有对象具有查询权限,对最终删除的目标对象具有删除权限;
- 删除列表中的表的数量存在上限,不能超过语义分析时 SELECT 语句中所支持的最大表个数 100;
- 暂不支持使用游标进行多表联合删除。
例 将没有分配部门的员工的住址信息删除。
DELETE FROM RESOURCES.EMPLOYEE_ADDRESS
WHERE EMPLOYEEID IN
( SELECT EMPLOYEEID
FROM RESOURCES.EMPLOYEE
WHERE EMPLOYEEID NOT IN
( SELECT EMPLOYEEID FROM RESOURCES.EMPLOYEE_DEPARTMENT));
5.4 MERGE INTO 语句
使用 MERGE INTO 语法可合并 UPDATE 和 INSERT 语句。通过 MERGE 语句,根据一张表(或视图)的连接条件对另外一张表(或视图)进行查询,连接条件匹配上的进行 UPDATE(可能含有 DELETE),无法匹配的执行 INSERT。其中,数据表包括:普通表、分区表、加密表、压缩表和堆表。
语法格式
MERGE INTO <merge_into_obj> [<表别名>] USING <表引用> ON [(] <条件判断表达式> [)]
<[<merge_update_clause>] [<merge_insert_clause>]>
<merge_into_obj> ::= <单表引用> | <子查询>
<单表引用> ::= [<模式名>.]<基表或视图名>
<子查询> ::= (<查询表达式>)
<merge_update_clause>::=WHEN MATCHED THEN UPDATE SET <set_value_list> <where_clause_null> [DELETE <where_clause_null>]
<merge_insert_clause>::=WHEN NOT MATCHED THEN INSERT [<full_column_list>] VALUES <ins_value_list> <where_clause_null>;
<表引用>::=<普通表> | <连接表> 详见《DM8_SQL语言使用手册》第四章 数据查询语句
<set_value_list> ::= <列名>=<值表达式| DEFAULT> {,<列名>=<值表达式| DEFAULT>}
<where_clause_null> ::= [WHERE <条件表达式>]
<full_column_list>::= (<列名>{,<列名>})
<ins_value_list>::= (<插入值>{,<插入值>})
参数
1.<模式名> 指明该表或视图所属的模式,缺省为当前用户的缺省模式;
2.<基表名> 指明被修改数据的基表的名称;
3.<视图名> 指明被修改数据的视图的名称,实际上 DM 对视图的基表更新数据;
4.< 查询表达式 > 指明被修改数据的子查询表达式,DM 实际是对子查询的基表进行数据更新。不支持集合运算、分组、集函数、HAVING 子句、层次查询、PIVOT/UNPIVOT 子句;不支持不可更新视图、外部表、物化视图辅助表、自定义的统计信息表、位图连接索引辅助表、系统表;不支持对计算列、集函数进行修改或插入;
5.<条件表达式> 指明限制被操作执行的行必须符合指定的条件,如果省略此子句,则对表或视图中所有的行进行操作。
图例
MERGE INTO 语句
merge_update_clause

merge_insert_clause

使用说明
-
INTO 后为目标表,表示待更新、插入的表、可更新视图及可更新查询表达式;
-
USING 后为源表(普通表或可更新视图),表示用于和目标表匹配、更新或插入的数据源;
-
ON(<条件判断表达式>)表示目标表和源表的连接条件,如果目标表有匹配连接条件的记录则执行更新该记录,如果没有匹配到则执行插入源表数据;
-
MERGE_UPDATE_CLAUSE:当目标表和源表的 JOIN 条件为 TRUE 时,执行该语句;
- 如果更新执行,更新语句会触发所有目标表上的 UPDATE 触发器,也会进行约束检查;
- 可以指定更新条件,如果不符合条件就不会执行更新操作。更新条件既可以和源表相关,也可以和目标表相关,或者都相关;
- DELETE 子句只删除目标表和源表的 JOIN 条件为 TRUE,并且是更新后的符合删除条件的记录,DELETE 子句不影响 INSERT 项插入的行。删除条件作用在更新后的记录上,既可以和源表相关,也可以和目标表相关,或者都相关。如果 JOIN 条件为 TRUE,但是不符合更新条件,并没有更新数据,那么 DELETE 将不会删除任何数据。当执行了删除操作,会触发目标表上的 DELETE 触发器,也会进行约束检查。
-
MERGE_INSERT_CLAUSE:当目标表和源表的 JOIN 条件为 FALSE 时,执行该语句。同时会触发目标表上的 INSERT 触发器,也会进行约束检查。可指定插入条件,插入条件只能在源表上设置;
-
MERGE_UPDATE_CLAUSE 和 MERGE_INSERT_CLAUSE 既可以同时指定,也可以只出现其中任何一个;
-
需要有对源表的 SELECT 权限,对目标表的 UPDATE/INSERT 权限,如果 UPDATE 子句有 DELETE,还需要有 DELETE 权限;
-
UPDATE 子句不能更新在 ON 连接条件中出现的列;
-
如果匹配到,源表中的匹配行必须唯一,否则报错;
-
<ins_value_list > 不能包含目标表列;
-
插入的 WHERE 条件只能包含源表列;
-
MERGE INTO 操作符方式允许在兼容 Oracle 模式下,且 MERGE_OPT_FLAG 不包含取值 8 时,将 MERGE INTO 语句中不加前缀的列名解析为目标表的列名。
举例说明
下面的例子把 T1 表中 C1 值为 2 的记录行中的 C2 列,更新为表 T2 中 C3 值为 2 的记录中 C4 列的值,同时把 T2 中 C3 列为 4 的记录行插入到 T1 中。
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1 (C1 INT, C2 VARCHAR(20));
CREATE TABLE T2 (C3 INT, C4 VARCHAR(20));
INSERT INTO T1 VALUES(1,'T1_1');
INSERT INTO T1 VALUES(2,'T1_2');
INSERT INTO T1 VALUES(3,'T1_3');
INSERT INTO T2 VALUES(2,'T2_2');
INSERT INTO T2 VALUES(4,'T2_4');
COMMIT;
MERGE INTO T1 USING T2 ON (T1.C1=T2.C3)
WHEN MATCHED THEN UPDATE SET T1.C2=T2.C4
WHEN NOT MATCHED THEN INSERT (C1,C2) VALUES(T2.C3, T2.C4);
下面的例子把 T1 表中 C1 值为 2,4 的记录行中的 C2 列更新为表 T2 中 C3 值为 2,4 的记录中 C4 列的值,同时把 T2 中 C3 列为 5 的记录行插入到了 T1 中。由于 UPDATE 带了 DELETE 子句,且 T1 中 C1 列值为 2 和 4 的记录行被更新过,而 C1 为 4 的行符合删除条件,最终该行会被删除掉。
DROP TABLE T1;
DROP TABLE T2;
CREATE TABLE T1 (C1 INT, C2 VARCHAR(20));
CREATE TABLE T2 (C3 INT, C4 VARCHAR(20));
INSERT INTO T1 VALUES(1,'T1_1');
INSERT INTO T1 VALUES(2,'T1_2');
INSERT INTO T1 VALUES(3,'T1_3');
INSERT INTO T1 VALUES(4,'T1_4');
INSERT INTO T2 VALUES(2,'T2_2');
INSERT INTO T2 VALUES(4,'T2_4');
INSERT INTO T2 VALUES(5,'T2_5');
COMMIT;
MERGE INTO T1 USING T2 ON (T1.C1=T2.C3)
WHEN MATCHED THEN UPDATE SET T1.C2=T2.C4 WHERE T1.C1 >= 2 DELETE WHERE T1.C1=4
WHEN NOT MATCHED THEN INSERT (C1,C2) VALUES(T2.C3, T2.C4);
5.5 伪列的使用
伪列从语法上和表中的列很相似,查询时能够返回一个值,但实际上伪列在表中并不存在。用户只可以对伪列进行查询,但不能插入、更新和删除它们的值。除了 4.13.2 层次查询相关伪列和 4.15 ROWNUM 中介绍的伪列外,DM 中还提供包括 ROWID、TRXID 等伪列。
5.5.1 ROWID
DM 中行标识符 ROWID 用来标识数据库基表中每一条记录的唯一键值,标识了数据记录的确切的存储位置。ROWID 由 18 位字符组成,分别为“4 位站点号 +6 位分区号 +8 位物理行号”。如果是单机则 4 位站点号为 AAAA,即 0。如果是非分区表,则 6 位分区号为 AAAAAA,即 0。关于 ROWID 中站点号、分区号和物理行号的使用和转换请参考附录 3 中的 22. ROWID。
如果用户在选择数据的同时从基表中选取 ROWID,在后续的更新语句中,就可以使用 ROWID 来提高性能。如果在查询时加上 FOR UPDATE 语句,该数据行就会被锁住,以防其他用户修改数据,保证查询和更新之间的一致性。
例 查询和使用 ROWID。
SELECT ROWID, VENDORID, NAME, CREDIT FROM PURCHASING.VENDOR WHERE NAME = '广州出版社';
查询结果如下:
ROWID VENDORID NAME CREDIT
------------------ ----------- ---------- -----------
AAAAAAAAAAAAAAAAAH 7 广州出版社 1
通过指定 ROWID 来确定待执行的行。
UPDATE PURCHASING.VENDOR SET CREDIT=2 WHERE ROWID ='AAAAAAAAAAAAAAAAAH';
5.5.2 TRXID
伪列 TRXID 用来表示当前事务的事务标识。
5.5.3 PHYROWID
伪列 PHYROWID 用来表示当前记录的物理存储信息。
PHYROWID 值由聚集 B 树或二级 B 树中物理记录的文件号、页号、页内槽号组成,能体现聚集 B 树或二级 B 树的存储信息,聚集 B 树记录的最高位为 1。
当查询语句中实际使用 CSCN、CSEK、BLKUP 操作符时,PHYROWID 内容是聚集 B 树中记录的物理存储地址;当查询语句中实际仅使用 SSEK、SSCN 操作符时,PHYROWID 内容是二级 B 树中记录的物理存储地址。
5.6 DM 自增列的使用
5.6.1 DM 自增列定义
1.自增列功能定义
DM 提供两种自增方式:IDENTITY 自增列和 AUTO_INCREMENT 自增列。本节专门介绍 IDENTITY 自增列用法。
语法格式
IDENTITY [ (种子, 增量) ]
参数
1.种子 装载到表中的第一个行所使用的值;
2.增量 增量值,该值被添加到前一个已装载的行的标识值上。增量值可以为正数或负数,但不能为 0。
使用说明
- IDENTITY 适用于 INT、BIGINT、DEC(n, 0)类型的列。每个表只能创建一个自增列;
- 不能对自增列使用 DEFAULT 约束;
- 必须同时指定种子和增量值,或者二者都不指定。如果二者都未指定,则取默认值(1,1)。若种子或增量为小数类型,报错;
- 最大值和最小值为该列的数据类型的边界;
- 建表种子和增量大于最大值或者种子和增量小于最小值时报错;
- 自增列一旦生成,无法更新,不允许用 UPDATE 语句进行修改;
- 自增列的值一旦生成,无法回滚。例如,数据表 T 中包含一个自增列,该列当前值为 n,增量为 1,对表 T 执行数据插入时,如果经约束检查发现待插入数据不满足约束条件,则会回滚数据插入操作,但此时自增列的值 n+1 已经生成,无法回滚,因此自增列的当前值变为 n+1;
- 临时表、列存储表不支持使用自增列。
2.自增列查询函数
- IDENT_SEED(函数)
语法格式
IDENT_SEED ('tablename')
功能:返回种子值,该值是在带有自增列的表中创建自增列时指定的。
参数:tablename 是带有引号的字符串常量,也可以是变量、函数或列名。tablename 的数据类型为 CHAR 或 VARCHAR。其含义是表名,可带模式名前缀。
返回类型:返回数据类型为 INT/NULL
- IDENT_INCR(函数)
语法格式
IDENT_INCR ('tablename')
功能:返回增量值,该值是在带有自增列的表中创建自增列时指定的。
参数:tablename 是带有引号的字符串常量,也可以是变量、函数或列名。tablename 的数据类型为 CHAR 或 VARCHAR。其含义是表名,可带模式名前缀。
返回类型:返回数据类型为 INT/NULL
例 用自增列查询函数获得表 PERSON_TYPE 的自增列的种子和增量信息。
SELECT IDENT_SEED('PERSON.PERSON_TYPE');
查询结果为:1
SELECT IDENT_INCR('PERSON.PERSON_TYPE');
查询结果为:1
5.6.2 SET IDENTITY_INSERT 属性
设置是否允许将显式值插入表的自增列中。ON 是,OFF 否。
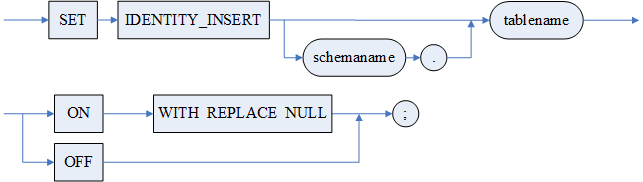
语法格式
SET IDENTITY_INSERT [<模式名>.]<表名> ON [WITH REPLACE NULL];
SET IDENTITY_INSERT [<模式名>.]<表名> OFF;
参数
1.<模式名> 指明表所属的模式,缺省为当前模式;
2.<表名> 指明含有自增列的表名。
图例
SET IDENTITY_INSERT
使用说明
1.IDENTITY_INSERT 属性的默认值为 OFF。SET IDENTITY_INSERT 的设置是在执行或运行时进行的。当一个连接结束,IDENTITY_INSERT 属性将被自动还原为 OFF;
2.DM 要求一个会话连接中只有一个表的 IDENTITY_INSERT 属性可以设置为 ON,当设置一个新的表 IDENTITY_INSERT 属性设置为 ON 时,之前已经设置为 ON 的表会自动还原为 OFF。当一个表的 IDENTITY_INSERT 属性被设置为 ON 时,该表中的自动增量列的值由用户指定。如果插入值大于表的当前标识值(自增列当前值),则 DM 自动将新插入值作为当前标识值使用,即改变该表的自增列当前值;否则,将不影响该自增列当前值;
3.当设置一个表的 IDENTITY_INSERT 属性为 OFF 时,新插入行中自增列的当前值由系统自动生成,用户将无法指定;
4.自增列一经插入,无法修改;
5.手动插入自增列,除了将 IDENTITY_INSERT 设置为 ON,还要求在插入列表中明确指定待插入的自增列列名。插入方式与非 IDENTITY 表是完全一样的。如果插入时,既不指定自增列名也不给自增列赋值,则新插入行中自增列的当前值由系统自动生成;
6.WITH REPLACE NULL 此模式下允许显式插入 NULL 值,同时,系统自动将 NULL 值替换为自增值。
举例说明
例 SET IDENTITY_INSERT 的使用。
- PERSON_TYPE 表中的 PERSON_TYPEID 列是自增列,目前拥有的数据如表 5.6.1 所示。
| PERSON_TYPEID | NAME |
|---|---|
| 1 | 采购经理 |
| 2 | 采购代表 |
| 3 | 销售经理 |
| 4 | 销售代表 |
- 在该表中插入数据,自增列的值由系统自动生成。
INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('销售总监');
INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('人力资源部经理');
插入结果如表 5.6.2 所示:
| PERSON_TYPEID | NAME |
|---|---|
| 1 | 采购经理 |
| 2 | 采购代表 |
| 3 | 销售经理 |
| 4 | 销售代表 |
| 5 | 销售总监 |
| 6 | 人力资源部经理 |
- 当插入数据并且要指定自增列的值时,必须要通过语句将 IDENTITY_INSERT 设置为 ON 时,插入语句中必须指定 PERSON_TYPEID 中要插入的列。例如:
SET IDENTITY_INSERT PERSON.PERSON_TYPE ON;
INSERT INTO PERSON.PERSON_TYPE(PERSON_TYPEID, NAME) VALUES( 8, '广告部经理');
INSERT INTO PERSON.PERSON_TYPE(PERSON_TYPEID, NAME) VALUES( 9, '财务部经理');
插入结果如表 5.6.3 所示:
| PERSON_TYPEID | NAME |
|---|---|
| 1 | 采购经理 |
| 2 | 采购代表 |
| 3 | 销售经理 |
| 4 | 销售代表 |
| 5 | 销售总监 |
| 6 | 人力资源部经理 |
| 8 | 广告部经理 |
| 9 | 财务部经理 |
- 不允许用户修改自增列的值。
UPDATE PERSON.PERSON_TYPE SET PERSON_TYPEID = 9 WHERE NAME = '广告部经理';
修改失败。对于自增列,不允许 UPDATE 操作。
- 还原 IDENTITY_INSERT 属性。
SET IDENTITY_INSERT PERSON.PERSON_TYPE OFF;
- 插入后再次查询。注意观察自增列当前值的变化。
INSERT INTO PERSON.PERSON_TYPE(NAME) VALUES('市场总监');
| PERSON_TYPEID | NAME |
|---|---|
| 1 | 采购经理 |
| 2 | 采购代表 |
| 3 | 销售经理 |
| 4 | 销售代表 |
| 5 | 销售总监 |
| 6 | 人力资源部经理 |
| 8 | 广告部经理 |
| 9 | 财务部经理 |
| 10 | 市场总监 |
- 使用 WITH REPLACE NULL 模式,显式插入 NULL 值。同时,系统自动将 NULL 值替换为自增值。
SET IDENTITY_INSERT PERSON.PERSON_TYPE ON WITH REPLACE NULL;
INSERT INTO PERSON.PERSON_TYPE(PERSON_TYPEID, NAME) VALUES(NULL, '总经理');
| PERSON_TYPEID | NAME |
|---|---|
| 1 | 采购经理 |
| 2 | 采购代表 |
| 3 | 销售经理 |
| 4 | 销售代表 |
| 5 | 销售总监 |
| 6 | 人力资源部经理 |
| 8 | 广告部经理 |
| 9 | 财务部经理 |
| 10 | 市场总监 |
| 11 | 总经理 |